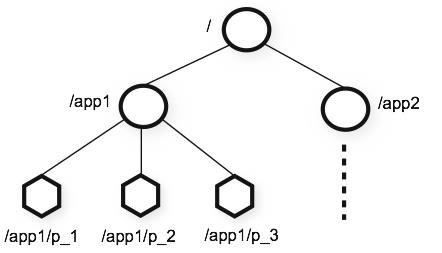
Consumer:消费者,每个 consumer 属于一个特定的 consuer group(若不指定 group name 则属于默认 group),使用 consumer high level API 时,同一 topic 的一条消息只能被同一个 consumer group 内的一个 consumer 消费,但多个 consumer group 可同时消费这一消息
[root@kakfa1 bin]$./kafka-topics.sh --delete \ --topic lujinkai \ --zookeeper zk1.ljk.cn:2181 Topic lujinkai is marked for deletion. Note: This will have no impact if delete.topic.enable is not set to true.
[root@zabbix src]$which rabbitmq-plugins /usr/sbin/rabbitmq-plugins [root@zabbix src]$rabbitmq-plugins enable rabbitmq_management Enabling plugins on node rabbit@mq1: rabbitmq_management The following plugins have been configured: rabbitmq_management rabbitmq_management_agent rabbitmq_web_dispatch Applying plugin configuration to rabbit@mq1... The following plugins have been enabled: rabbitmq_management rabbitmq_management_agent rabbitmq_web_dispatch
[root@mq1 ~]$rabbitmqctl add_user ljk 123456 # 添加用户 Adding user "ljk" ... Done. Don't forget to grant the user permissions to some virtual hosts! See 'rabbitmqctl help set_permissions' to learn more. [root@mq1 ~]$rabbitmqctl set_user_tags ljk administrator # 用户授权 Setting tags for user "ljk" to [administrator] ... [root@mq1 ~]$rabbitmqctl list_users Listing users ... user tags ljk [administrator] # 授权成功 guest [administrator]
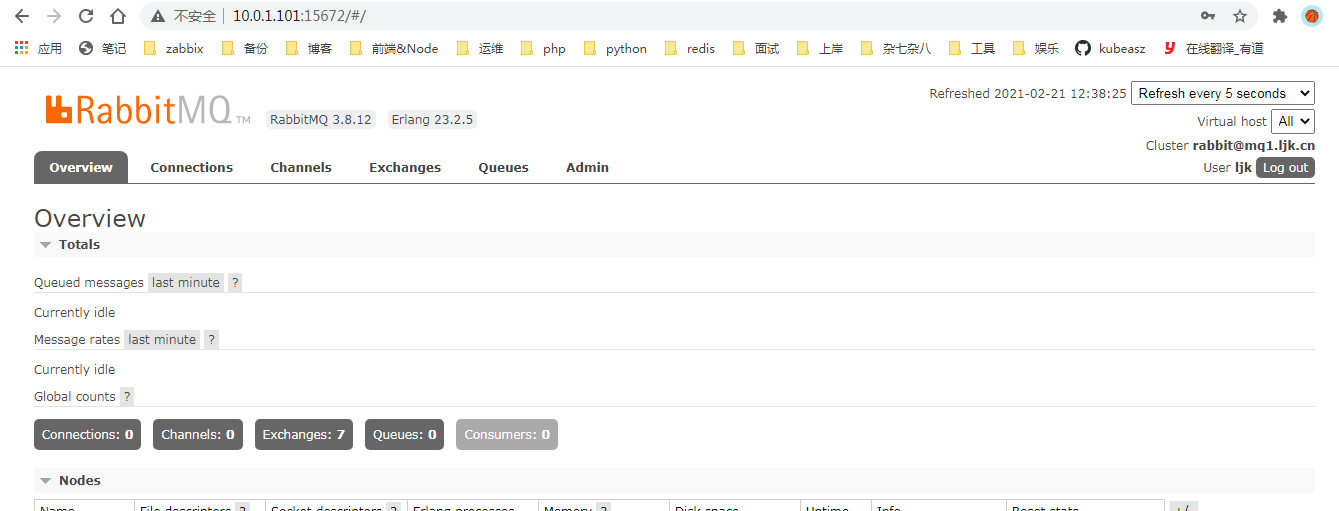
使用账号 ljk,密码 123456,成功登录 web 管理界面:
登录之后,我们很少进行更改,主要是查看 rabbitmq 的运行状态
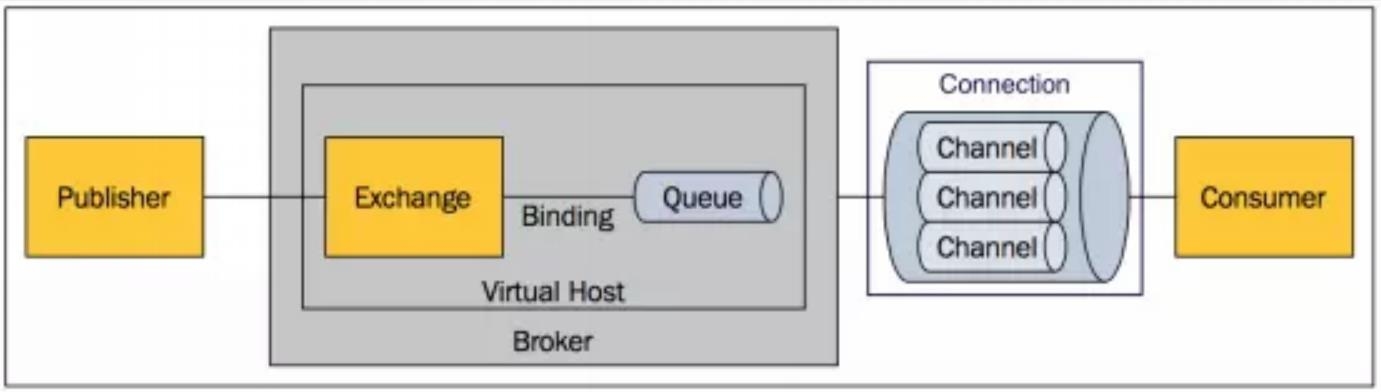
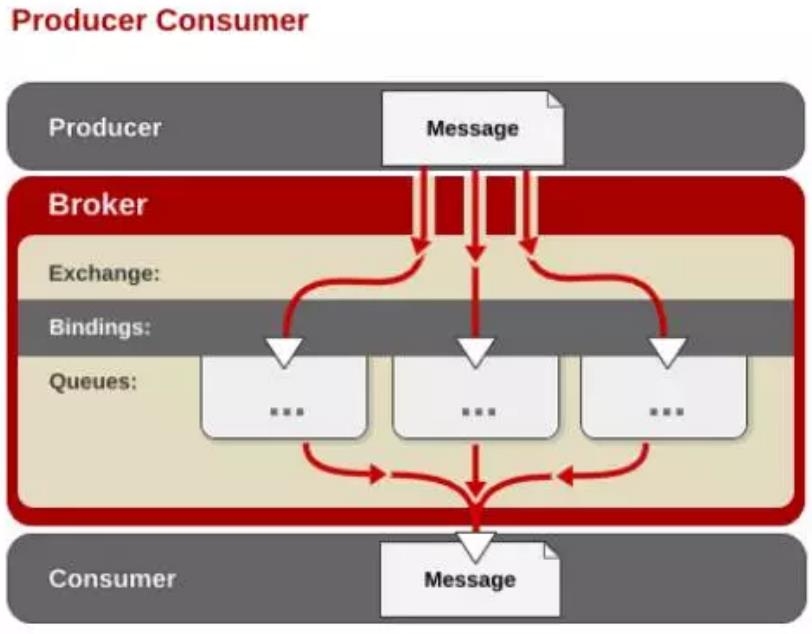
RabbitMQ 集群部署
普通模式:创建好 RabbitMQ 集群之后的默认模式 所有的 mq 节点保存相同的元数据,即消息队列,但队列里的数据仅保存一份,消费者从 A 节点拉取消息,如果消息在 B 节点,那么 B 会将消息发送给 A 节点,然后消费者就能拉取到数据了 缺点:单点失败
[root@mq1 ~]$rabbitmqctl delete_vhost test Deleting vhost "test" ...
添加账户 jack 密码为 123456
1 2 3
[root@mq1 ~]$rabbitmqctl add_user jack 123456 Adding user "jack" ... Done. Don't forget to grant the user permissions to some virtual hosts! See 'rabbitmqctl help set_permissions' to learn more.
更改用户密码
1 2
[root@mq1 ~]$rabbitmqctl change_password jack 654321 Changing password for user "jack" ...
设置 jack 用户对 test 的 vhost 有读写权限,三个点为配置正则、读和写
1
[root@mq1 ~]$rabbitmqctl set_permissions -p test jack ".*"".*"".*"
data = obj.stdout.read() data1 = eval(data) for i in data1: if i.get("running") == "true": running_list.append(i.get("name")) else: error_list.append(i.get("name"))
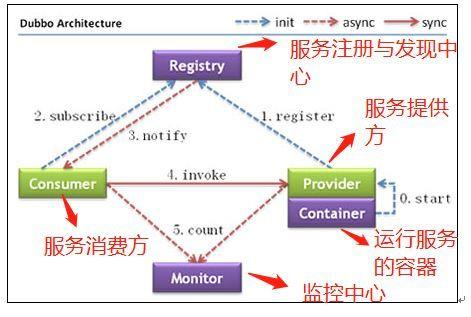
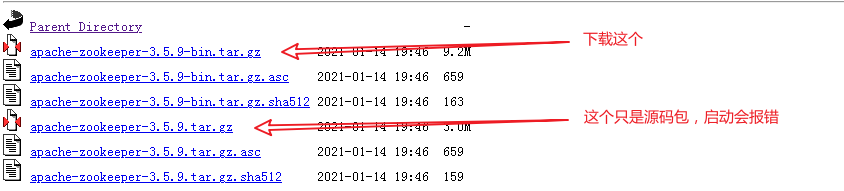
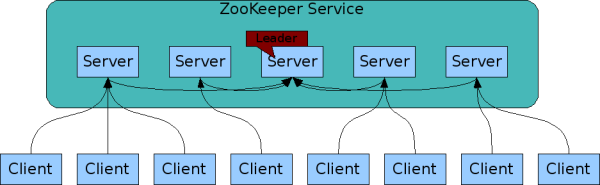
[root@provider1 dubbo-demo-provider-2.1.5]$tail -f logs/stdout.log # 查看日志 Java HotSpot(TM) 64-Bit Server VM warning: ignoring option PermSize=128m; support was removed in 8.0 Java HotSpot(TM) 64-Bit Server VM warning: UseCMSCompactAtFullCollection is deprecated and will likely be removed in a future release. log4j:WARN No appenders could be found for logger (com.alibaba.dubbo.common.logger.LoggerFactory). log4j:WARN Please initialize the log4j system properly. log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info. [2021-02-23 13:25:48] Dubbo service server started! # 启动成功
[root@mysql-master ~]$mysql -uroot -p # 创建 zabbix_server 数据库 mysql> create database zabbix_server character set utf8 collate utf8_bin; # 创建 zabbix_server 用户 mysql> create user zabbix_server@'10.0.%.%' identified by '123456'; mysql> grant all privileges on zabbix_server.* to zabbix_server@'10.0.%.%';
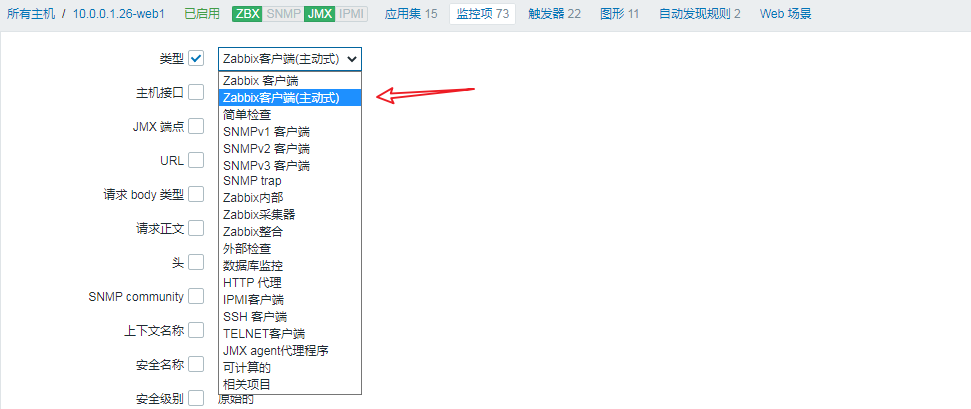
主动检查:agent 从 zabbix server 获取监控项列表,然后定期采集数据,主动发送给 zabbix server
被动模式
被动模式下,zabbix server 会根据主机关联的模板中的监控项和数据采集间隔时间,周期性的打开随机端口并向 zabbix agent 服务器的 10050 发起 tcp 连接,然后发送获取监控项数据的指令,即 zabbix server 发送什么指令,zabbix agent 就收集什么数据,zabbix server 什么时候发送 zabbix agent 就什么时候采集,zabbix server 不发送 zabbix agent 就闲着,所以 zabbix agent 也不用关心其监控项和数据采集周期间隔时间
优点就是配置简单,缺点是会加大 zabbix server 的工作量,在数百甚至数千台服务器的环境下会导致 zabbix server 需要轮训向每个 zabbix agent 发送数据采集指令,如果 zabbix server 负载很高还会导致不能及时获取到最新数据
主动模式
主动模式下,zabbix agent 主动向 zabbix server 的 10051 端口发起 tcp 连接请求(zabbix agent 配置文件中指定 zabbix server 的 IP 或者主机名),获取到自己的监控项和数据采集周期等信息,然后再周期性的采集指定的数返回给 zabbix server
[root@web1 data]$echo -e "stats\nquit" | nc 127.0.0.1 11211 STAT pid 5590 STAT uptime 725 STAT time 1613618905 STAT version 1.5.6 Ubuntu STAT libevent 2.1.8-stable STAT pointer_size 64 STAT rusage_user 0.072870 STAT rusage_system 0.048580 STAT max_connections 1024 STAT curr_connections 1 STAT total_connections 4 STAT rejected_connections 0 STAT connection_structures 2 STAT reserved_fds 20 STAT cmd_get 0 STAT cmd_set 0 STAT cmd_flush 0 STAT cmd_touch 0 STAT get_hits 0 STAT get_misses 0 STAT get_expired 0 STAT get_flushed 0 STAT delete_misses 0 STAT delete_hits 0 STAT incr_misses 0 STAT incr_hits 0 STAT decr_misses 0 STAT decr_hits 0 STAT cas_misses 0 STAT cas_hits 0 STAT cas_badval 0 STAT touch_hits 0 STAT touch_misses 0 STAT auth_cmds 0 STAT auth_errors 0 STAT bytes_read 35 STAT bytes_written 3795 STAT limit_maxbytes 67108864 STAT accepting_conns 1 STAT listen_disabled_num 0 STAT time_in_listen_disabled_us 0 STAT threads 4 STAT conn_yields 0 STAT hash_power_level 16 STAT hash_bytes 524288 STAT hash_is_expanding 0 STAT slab_reassign_rescues 0 STAT slab_reassign_chunk_rescues 0 STAT slab_reassign_evictions_nomem 0 STAT slab_reassign_inline_reclaim 0 STAT slab_reassign_busy_items 0 STAT slab_reassign_busy_deletes 0 STAT slab_reassign_running 0 STAT slabs_moved 0 STAT lru_crawler_running 0 STAT lru_crawler_starts 1275 STAT lru_maintainer_juggles 774 STAT malloc_fails 0 STAT log_worker_dropped 0 STAT log_worker_written 0 STAT log_watcher_skipped 0 STAT log_watcher_sent 0 STAT bytes 0 STAT curr_items 0 STAT total_items 0 STAT slab_global_page_pool 0 STAT expired_unfetched 0 STAT evicted_unfetched 0 STAT evicted_active 0 STAT evictions 0 STAT reclaimed 0 STAT crawler_reclaimed 0 STAT crawler_items_checked 0 STAT lrutail_reflocked 0 STAT moves_to_cold 0 STAT moves_to_warm 0 STAT moves_within_lru 0 STAT direct_reclaims 0 STAT lru_bumps_dropped 0 END
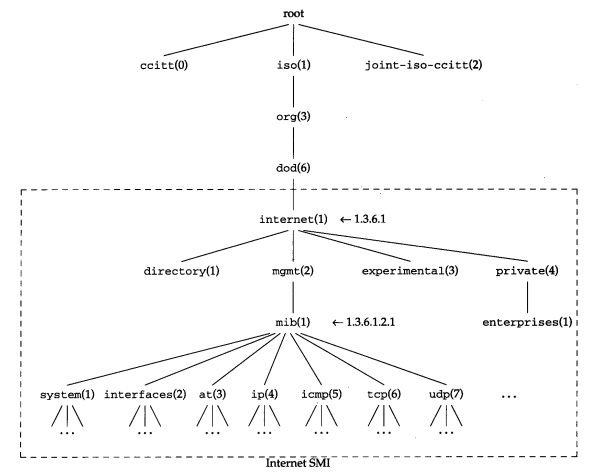
管理信息结构(SMI, Structure of Management Information),一套公用的结构和表示符号
管理信息库(MIB,Management Information Base),管理信息库包含所有代理进程的所有可被查询和修改的参数
OID(Object Identifiers),一个 OID 是一个唯一的键值对,用于标识具体某一个设备的某个具体信息(对象标识),如端口信息、设备名称等
SNMP MIB
MIB 是 OID 的集合。MIB 是基于对象标识树的,对象标识是一个整数序列,中间以”.”分割,这些整数构成一个树型结构,类似于 DNS 或 Unix 的文件系统,MIB 被划分为若干个组,如 system、 interfaces、 a t(地址转换)和 ip 组等。iso. org.dod.internet.private.enterprises(1.3 .6 .1.4.1)这个标识,是给厂家自定义而预留的,比如华为:1.3.6.1.4.1.2011,华三:1.3.6.1.4.1.25506
SNMP OID
OID 就是对象标识
snmpwalk 工具可以使用 SNMP 的 get 请求查询指定 OID 入口的所有 OID 树信息。通过 snmpwalk 也可以查看支持 SNMP 协议(可网管)的设备的一些其他信息,比如 cisco 交换机或路由器 IP 地址、内存使用率等,也可用来协助开发 SNMP 功能
Hello,I am 用户名,The system version is here,please help me to check it,thanks! 操作系统版本信息
1
[root@centos8 ~]# echo -e "Hello, I am `whoami`,The system version is here,please help me to check it ,thanks! \n`cat /etc/os-release`" | mail -s hello root
- 普通文件 d 目录文件 directory b 块设备block c 字符设备 character l 符号链接文件 link p 管道文件 pipe s 套接字文件 socket
普通文件
普通文件分为三类:
纯文本文件 ASCII:使用 cat 可以查看纯文本文件
二进制文件 binary:使用 od 或者 hexdump 命令以 8 进制或者 16 进制查看
数据格式文件 data 有些程序运行的过程中会读取某些特定格式的文件,那些特定格式的文件可以被成为数据文件(data file)。举例来说,我们的 Linux 在使用登录的时候,都会将登录的数据记录在 /var/log/wtmp 文件内,该文件就是一个 data file,它可以被 last 和 who 命令读取内容.
文件 A 和文件 B 的 inode 号码虽然不一样,但是文件 A 的内容是文件 B 的路径。读取文件 A 时,系统会自动将访问者导向文件 B。因此,无论打开哪一个文件,最终读取的都是文件 B。这时,文件 A 就称为文件 B 的”软链接”(soft link)或者”符号链接(symbolic link)。
这意味着,文件 A 依赖于文件 B 而存在,如果删除了文件 B,打开文件 A 就会报错:”No such file or directory”。这是软链接与硬链接最大的不同:文件 A 指向文件 B 的文件名,而不是文件 B 的 inode 号码,文件 B 的 inode”链接数”不会因此发生变化。
-h, --help Print this message and exit -v, --version Print the version information and exit --md5 Use MD5 to encrypt the password --sha-256 Use SHA-256 to encrypt the password --sha-512 Use SHA-512 to encrypt the password (default)
Report bugs to <bug-grub@gnu.org>. EOF [root@centos6 ~]# grub-crypt Password: Retype password: $6$O4ufCj1vTKW/7Ko7$p9rV3m0dsEsr0ebCyOVN.togh1fVhQCCDBsoc.RkelfWnRrIm3W5vVPuB86oOKo1Yei0QKxO2MRMoX2qzHV7M1 [root@centos6 ~]# useradd -p '$6$O4ufCj1vTKW/7Ko7$p9rV3m0dsEsr0ebCyOVN.togh1fVhQCCDBsoc.RkelfWnRrIm3W5vVPuB86oOKo1Yei0QKxO2MRMoX2qzHV7M1' test [root@centos6 ~]# getent shadow test test:$6$O4ufCj1vTKW/7Ko7$p9rV3m0dsEsr0ebCyOVN.togh1fVhQCCDBsoc.RkelfWnRrIm3W5vVPuB86oOKo1Yei0QKxO2MRMoX2qzHV7M1:18475:0:99999:7:::
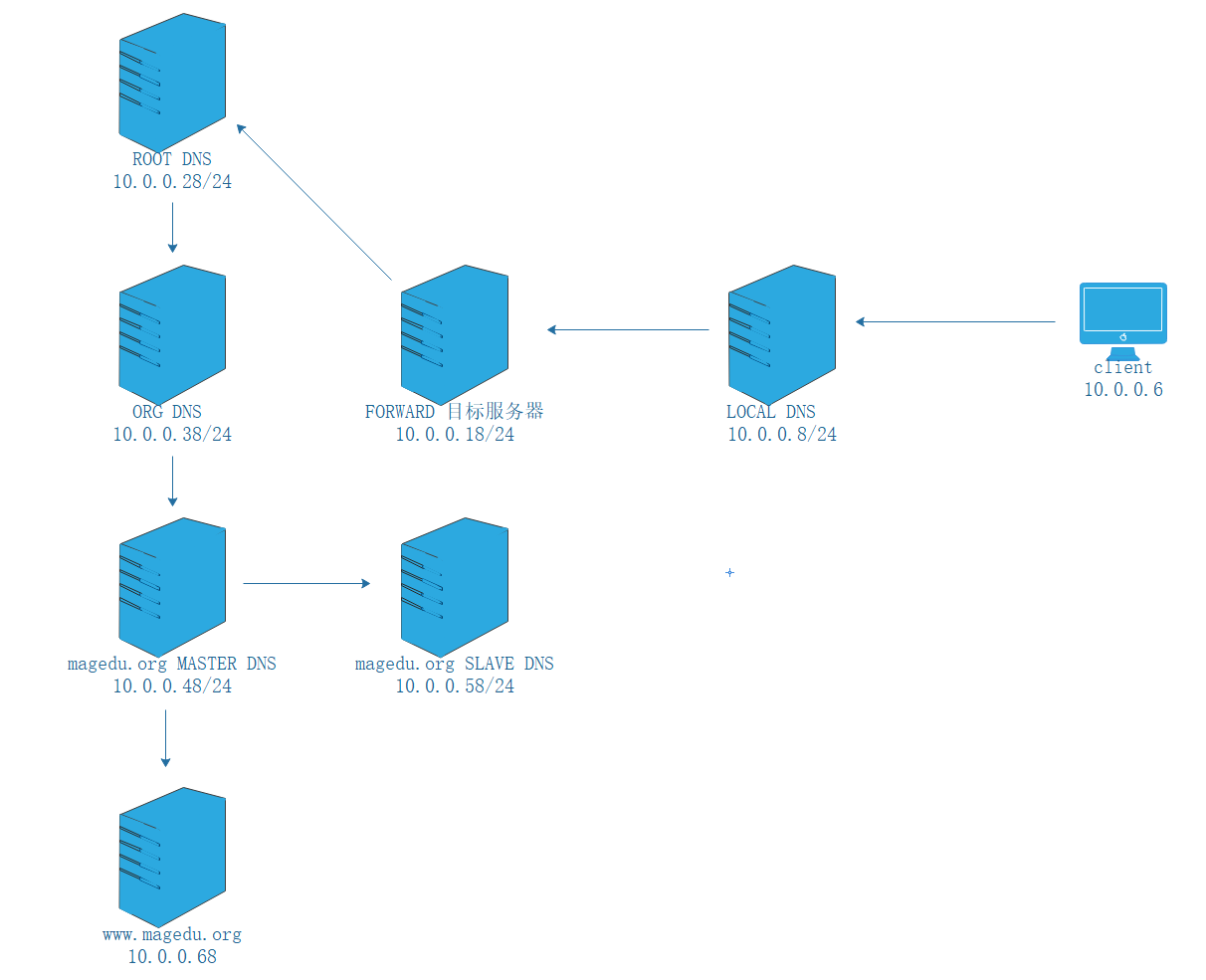
客户端设置 dns 为本地 dns 服务器,本地 dns 服务器负责将所有 dns 解析请求转发到转发目标 dns 服务器,转发目标 DNS 服务器添加根 dns 服务器的 ip 到 named.ca,根 dns 服务器将将解析 org 的 dns 请求转发到org 域 DNS 服务器,org 域 DNS 服务器将解析 magedu.org 的 dns 请求转发到magedu.org 域 DNS 服务器(主从),magedu.org 域 DNS 服务器将解析www.magedu.org的dns请求转发到目标**WEB服务器**,WEB服务器返回请求的数据
zone "magedu.local" IN { type master; file "magedu.local.zone"; };
2. 修改 DNS 区域数据库文件 /var/named/magedu.org.zone
1 2 3 4 5 6 7 8 9 10 11
$TTL 1D @ IN SOA master admin.magedu.org. ( 0 ; serial 1D ; refresh 1H ; retry 1W ; expire 3H ) ; minimum NS master master A 10.0.0.175 www A 10.0.0.8 slave A 10.0.0.6
3. 检查并重启 DNS 主服务器
1 2 3 4 5 6
[root@centos8 ~]$named-checkconf [root@centos8 slaves]$named-checkzone magedu.loacl /var/named/magedu.local.zone zone magedu.loacl/IN: loaded serial 0 OK [root@centos8 ~]$rndc reload server reload successful