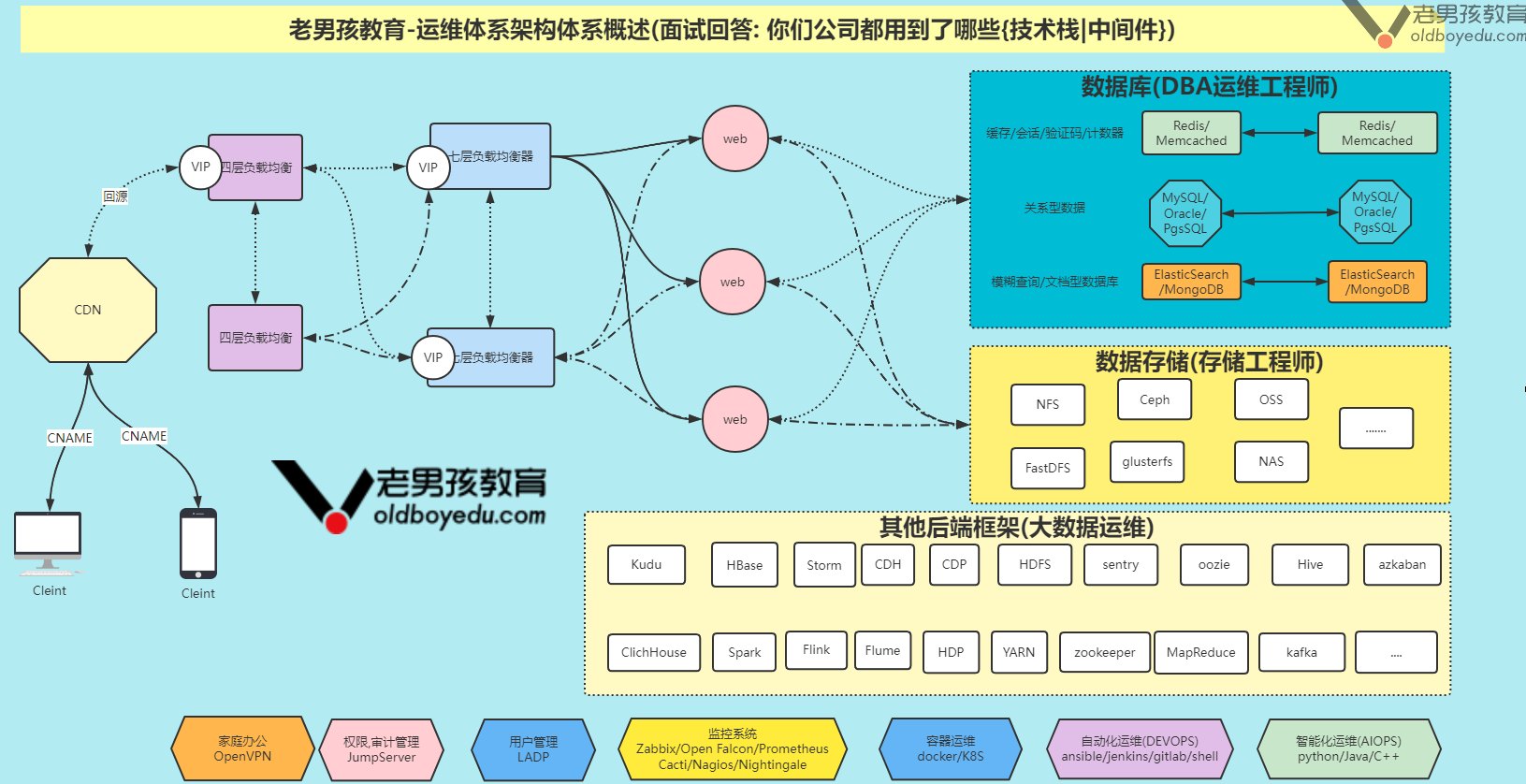
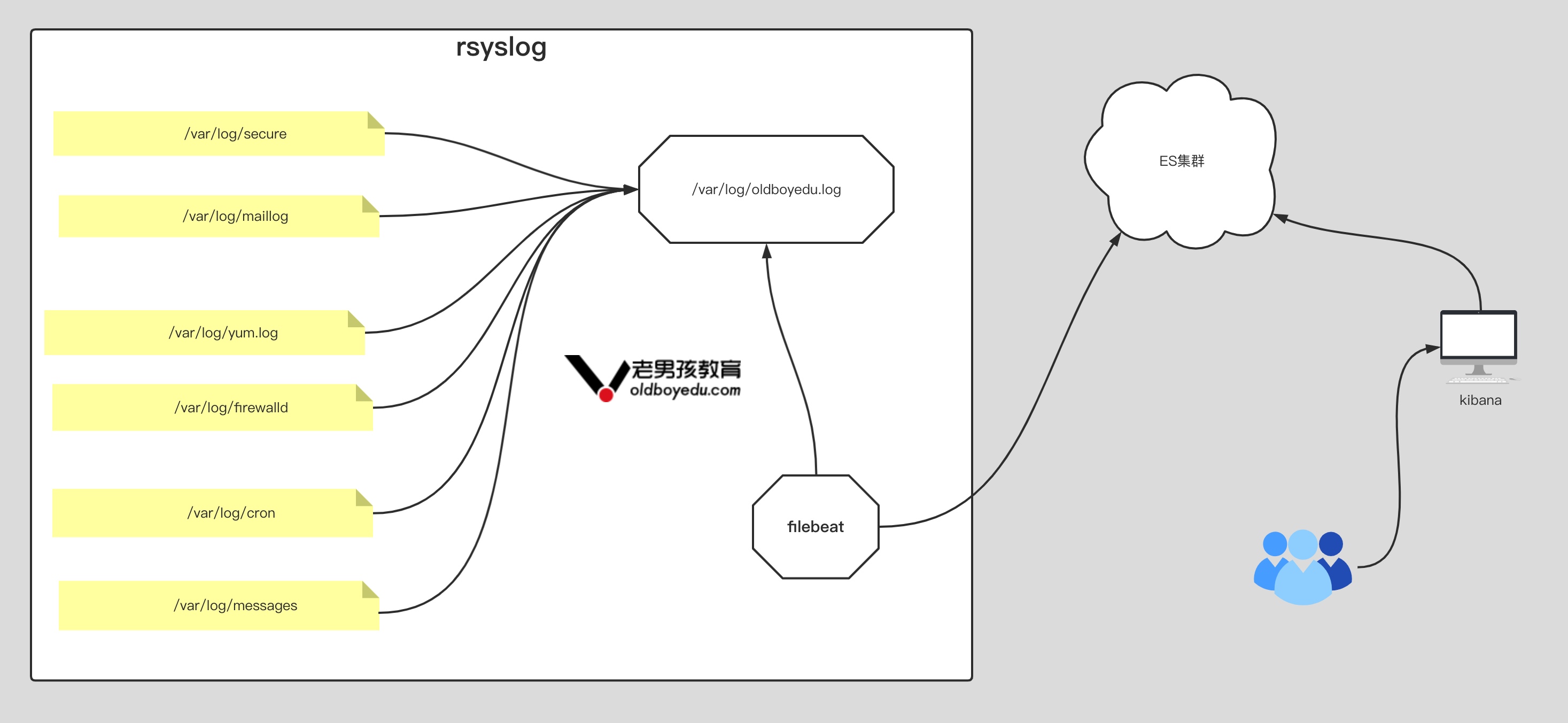
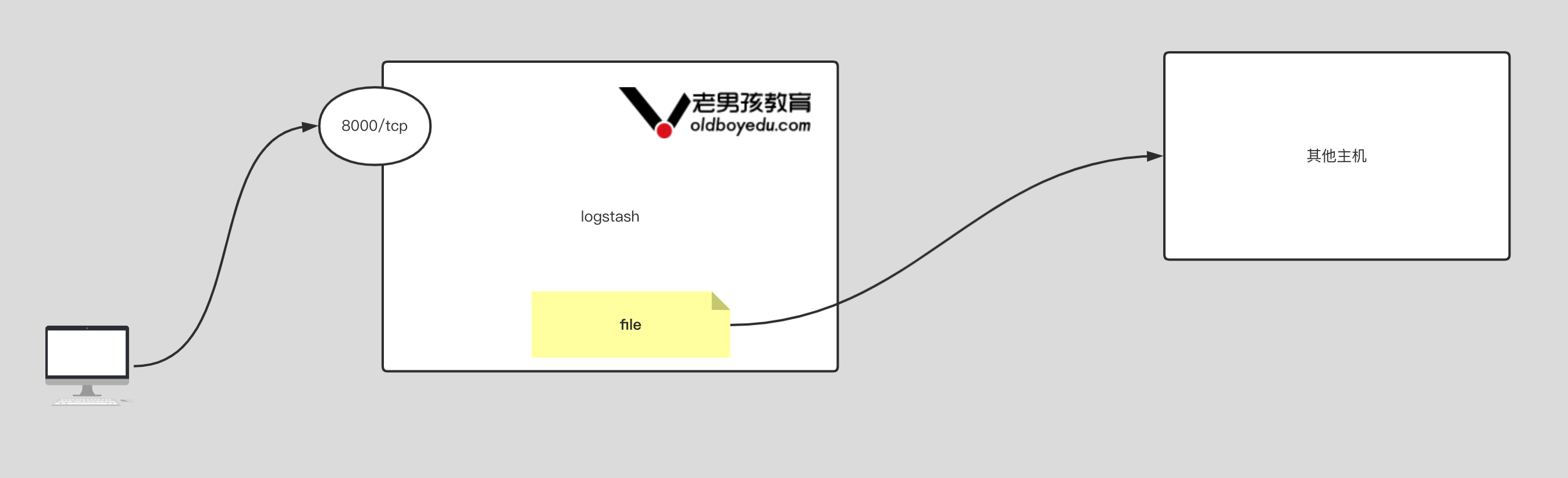
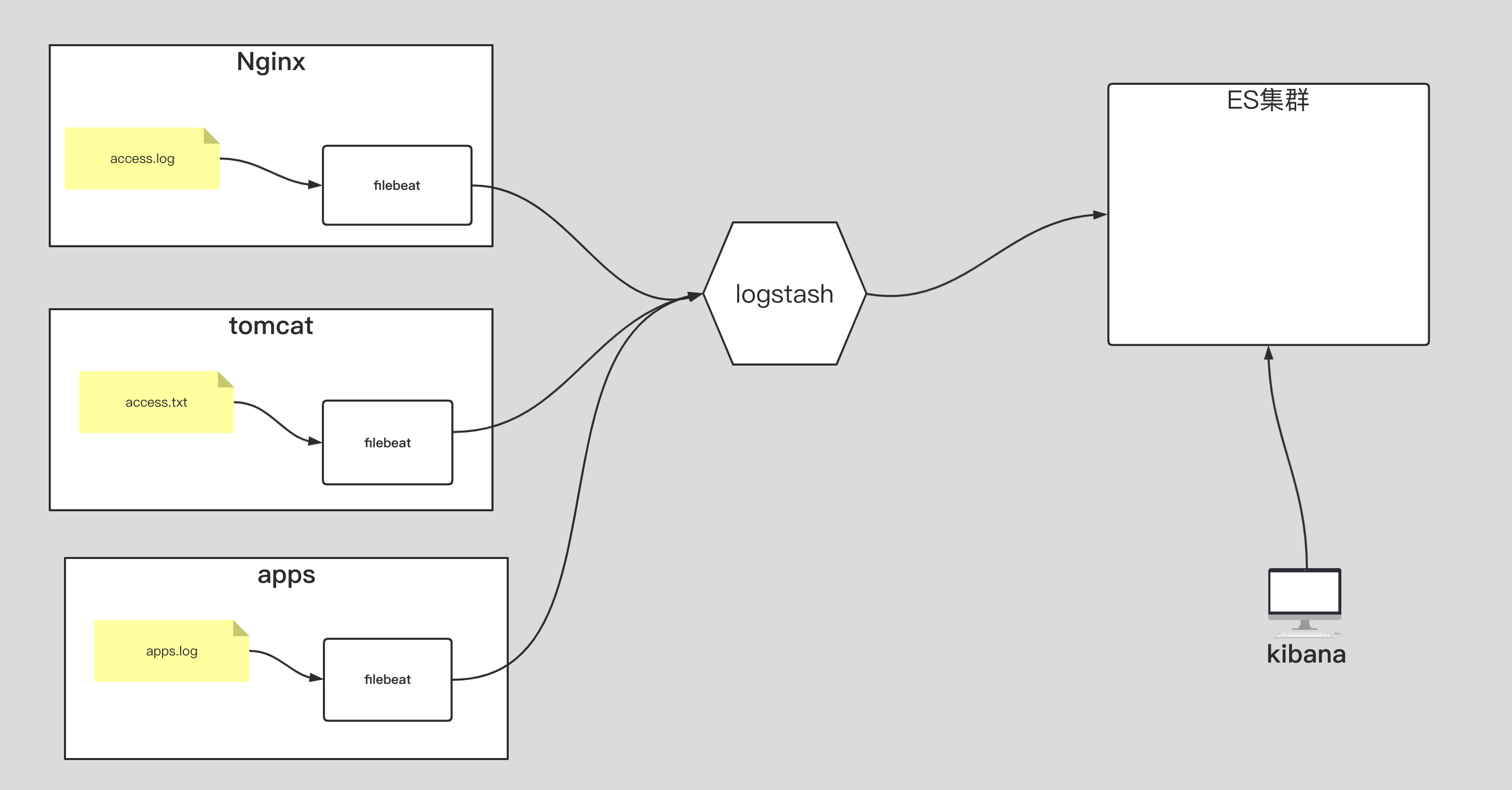
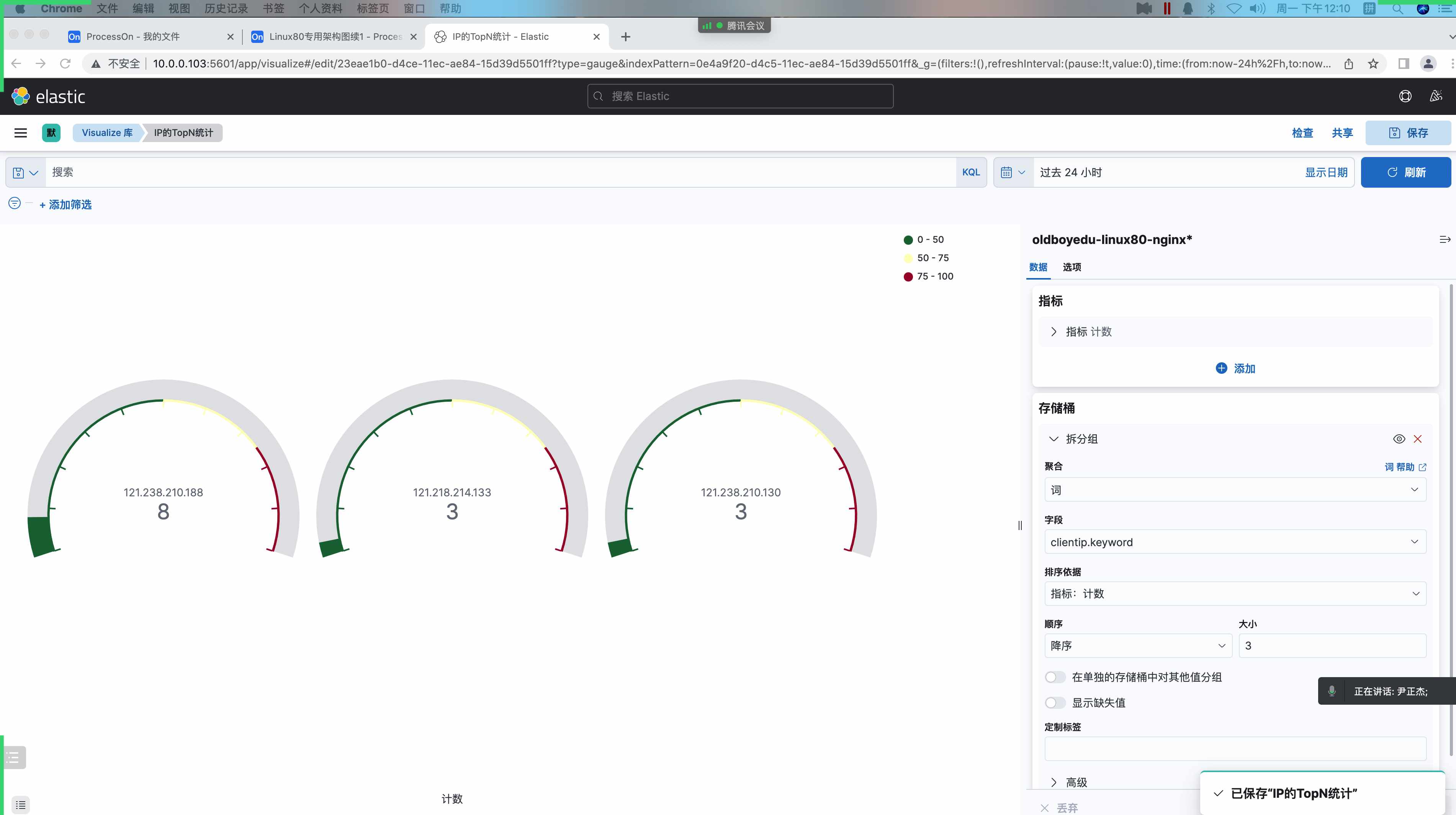
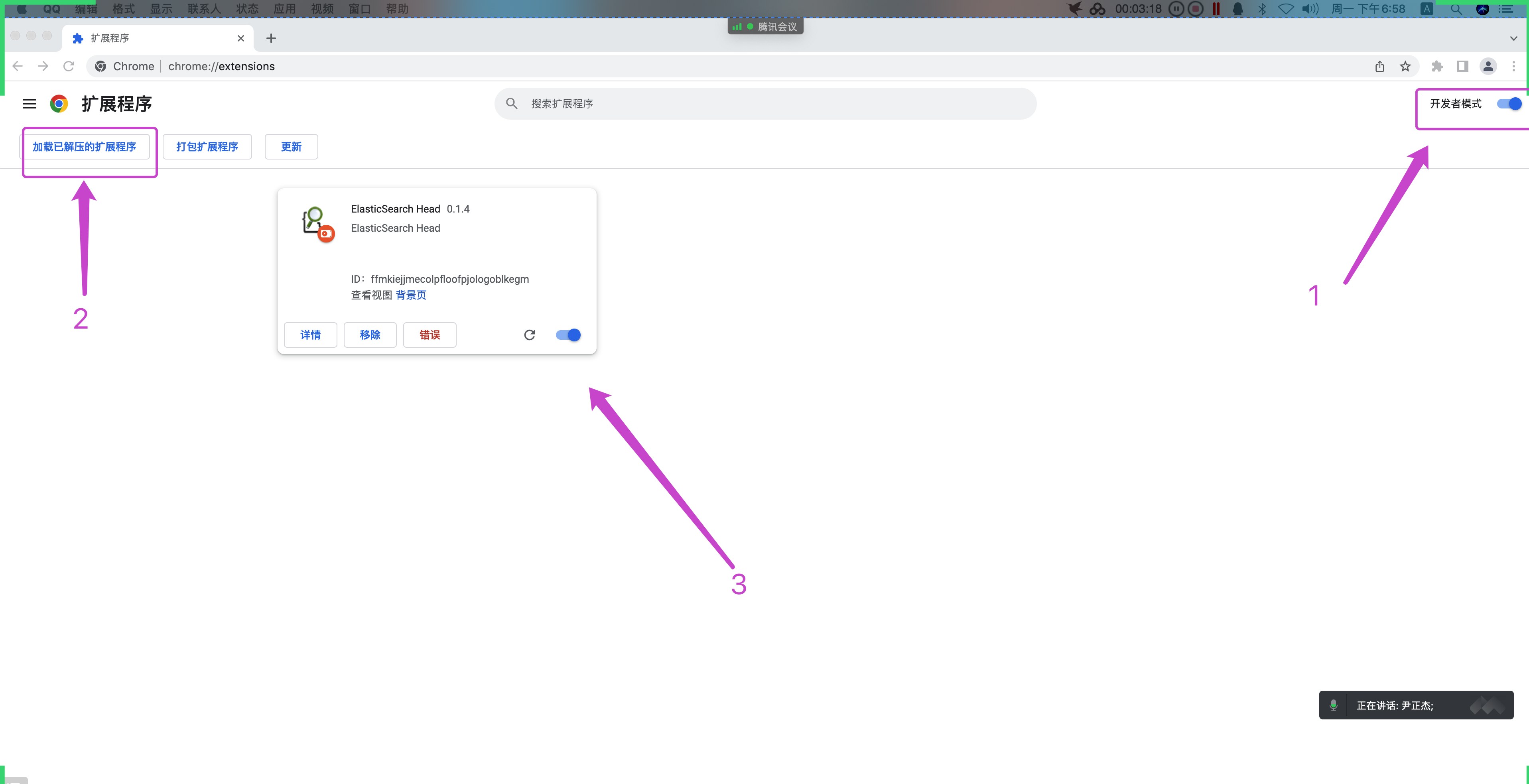
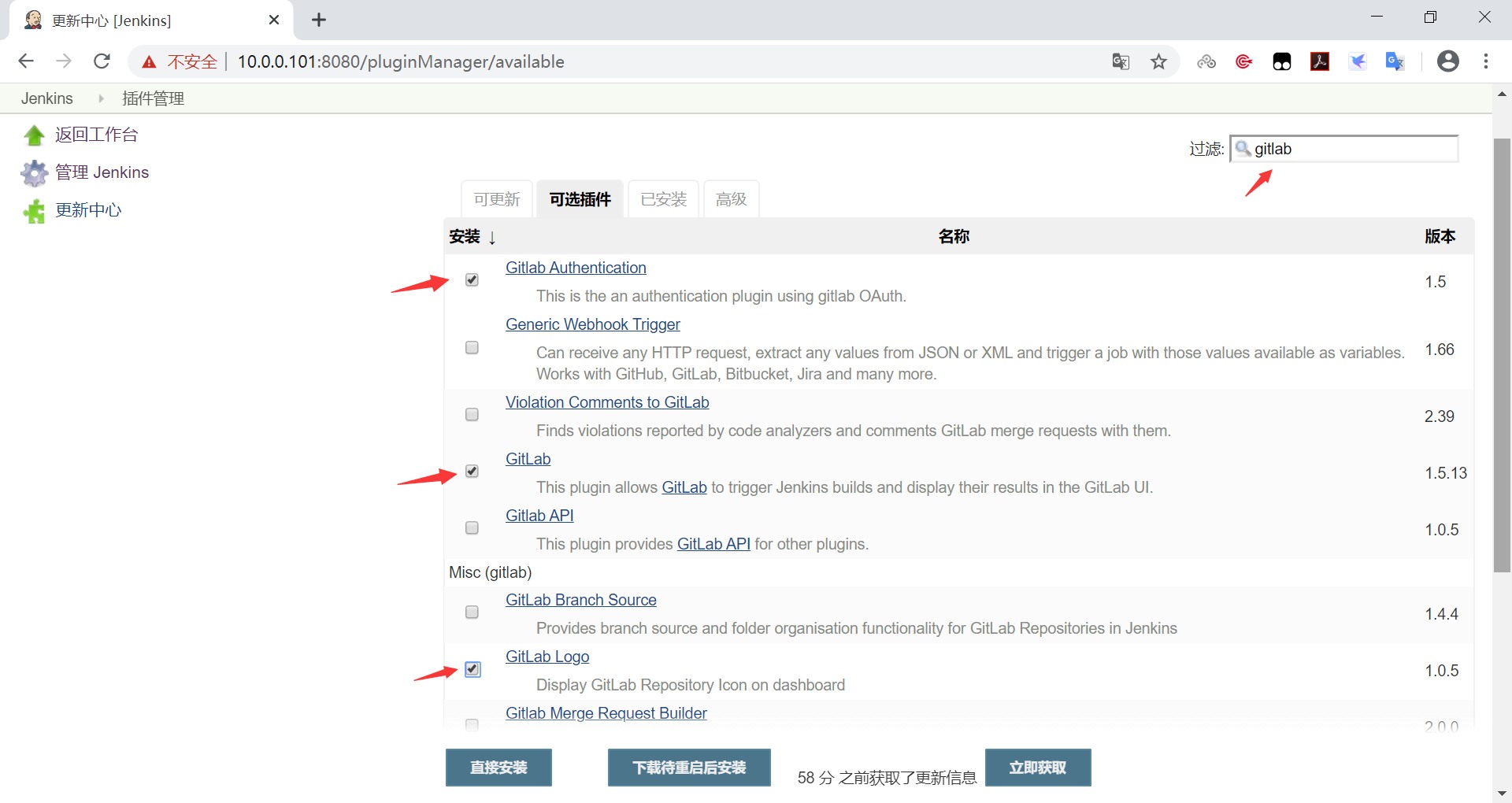
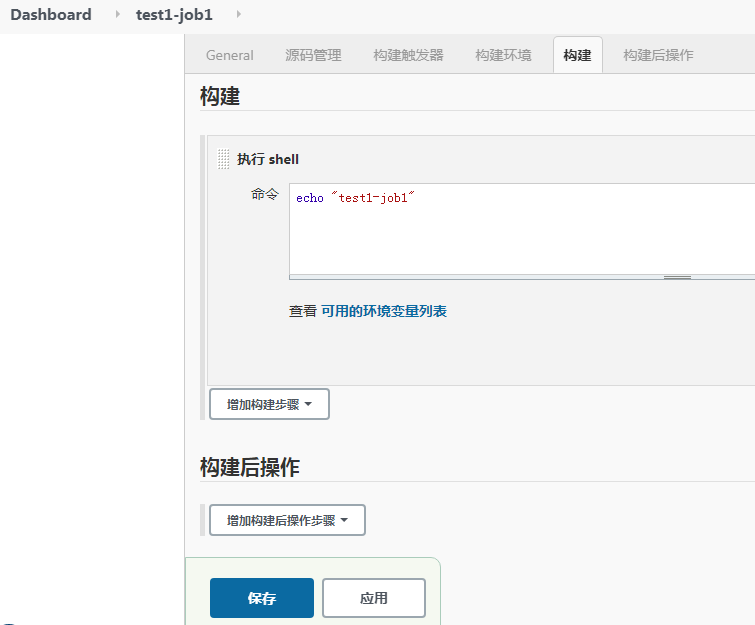
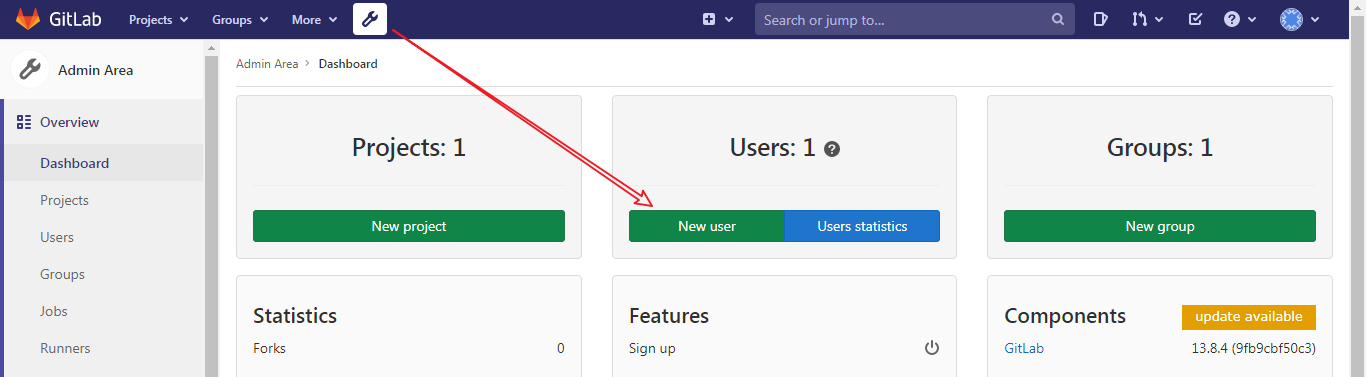
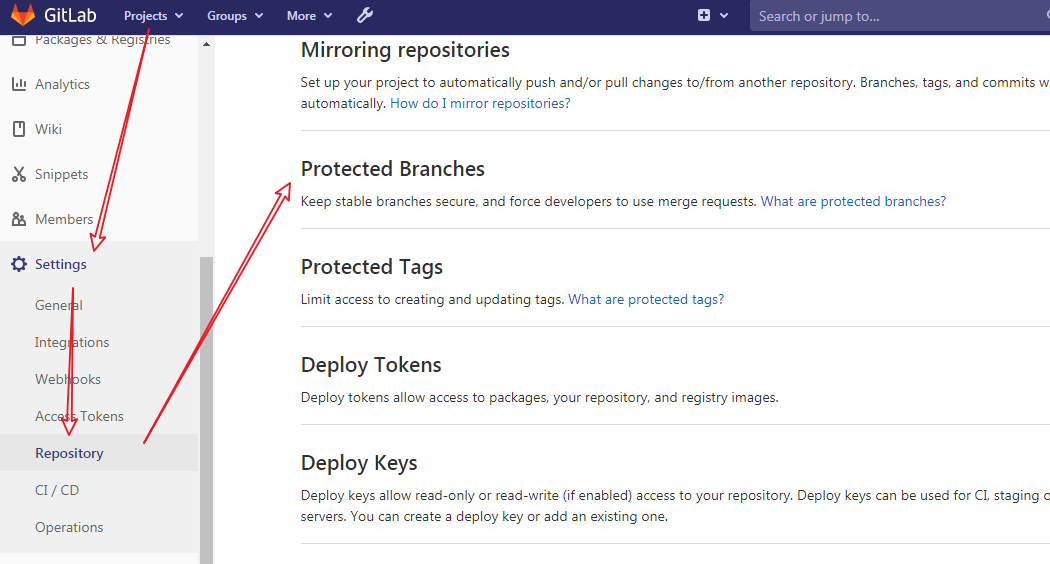
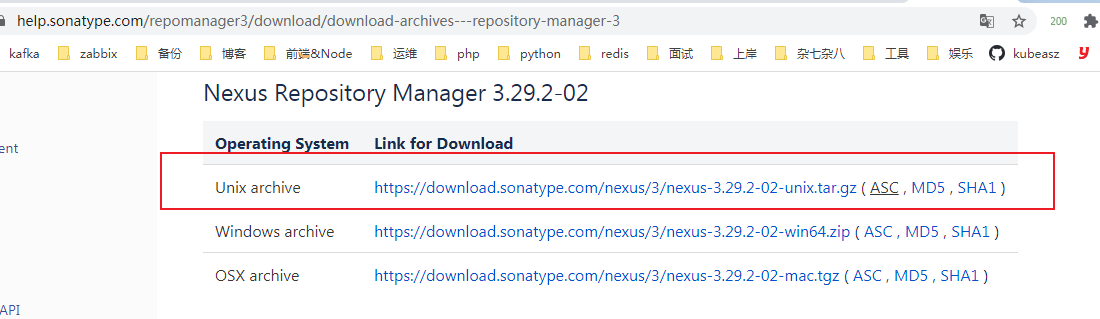
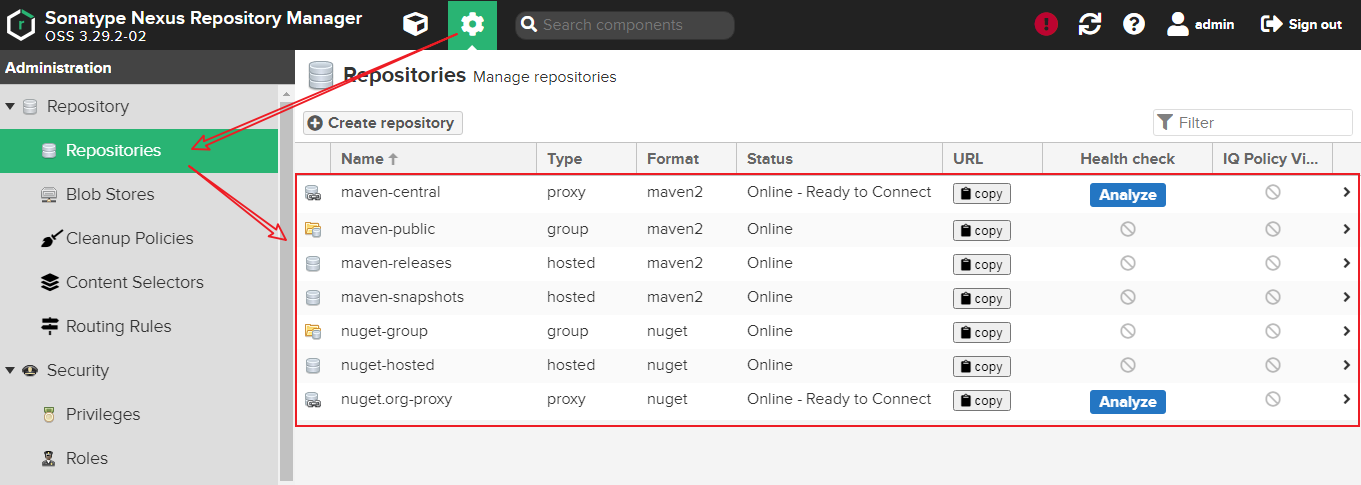
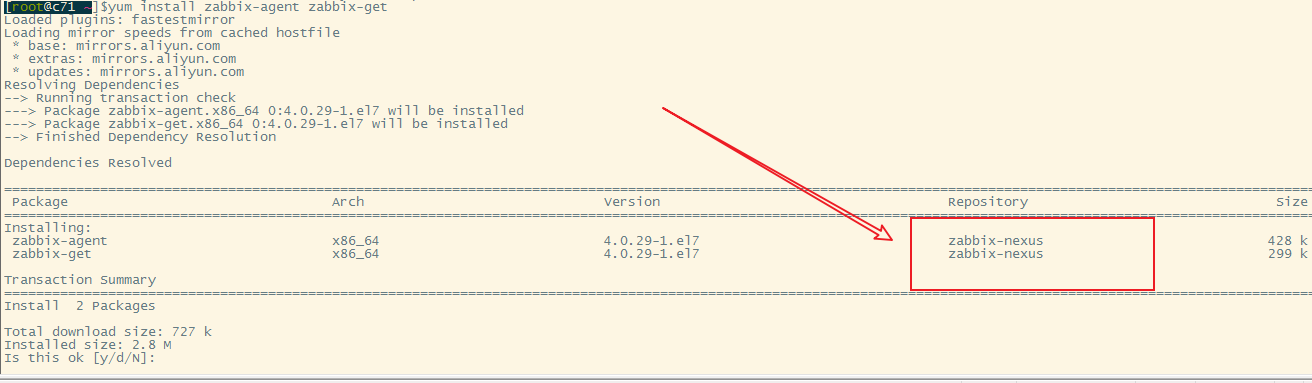
# traceroute命令查看请求ip为10.10.74.193的pod / $ traceroute 10.10.74.193 traceroute to 10.10.74.193 (10.10.74.193), 30 hops max, 46 byte packets 1 10.0.1.32 (10.0.1.32) 0.005 ms 0.006 ms 0.002 ms # 当前pod所在节点的ip 2 10.0.1.33 (10.0.1.33) 1.220 ms 0.254 ms 0.147 ms # 对方pod所在节点的ip 3 10.10.74.193 (10.10.74.193) 0.207 ms 0.308 ms 0.163 ms # 对方pod的ip
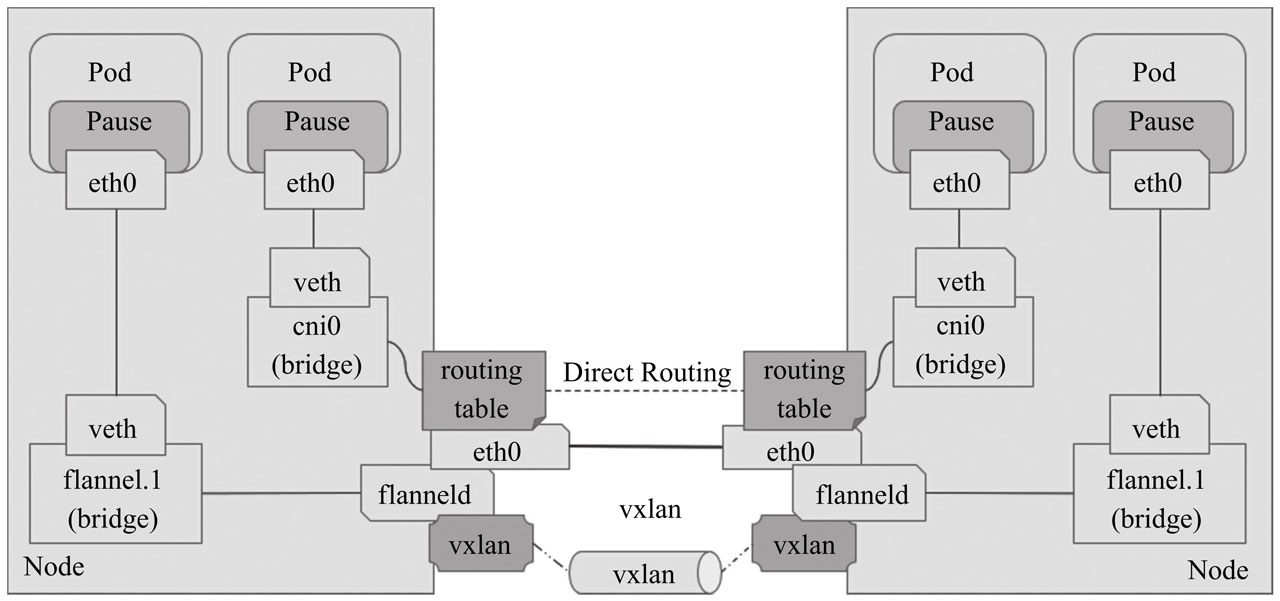
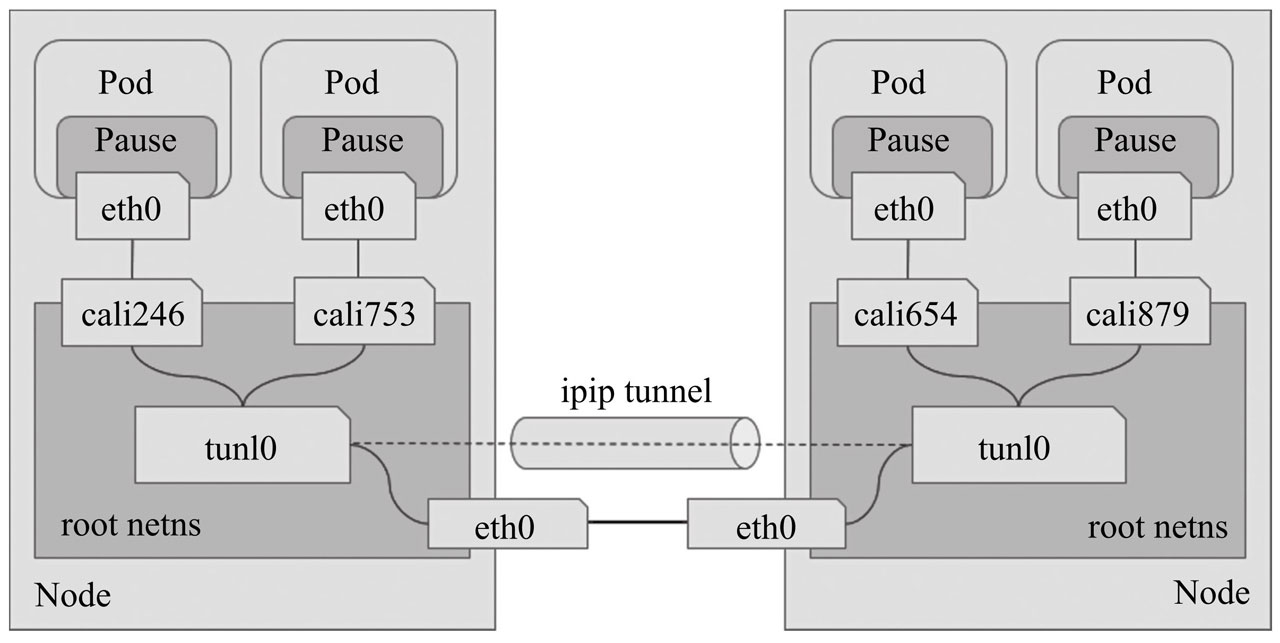
如果 node 需要跨网段通信,Calico 也提供了IPIP模式,IPIP 模式下,calico 会在每个节点上创建一个 tunl0 接口(TUN 类型虚拟设备)用于封装三层隧道报文。节点上每创建一个 Pod 资源,都自动创建一对虚拟以太网接口(TAP 类型的虚拟设备),其中一个附加于 Pod 的网络名称空间,另一个(名称以 cali 为前缀后跟随机字串)留置在节点的根网络名称空间,并经由 tunl0 封装或解封三层隧道报文,Calico IPIP 模式如下图:
IPIP 模式下 calico 的通信过程:
1 2 3 4 5
/ $ traceroute 10.10.58.65 # 请求ip为10.10.58.65的pod traceroute to 10.10.58.65 (10.10.58.65), 30 hops max, 46 byte packets 1 172.31.6.210 (172.31.6.210) 0.004 ms 0.004 ms 0.002 ms # 当前pod所在node地址 2 10.10.58.64 (10.10.58.64) 0.003 ms 0.432 ms 0.497 ms # 对方pod所在node的tunl0地址 3 10.10.58.65 (10.10.58.65) 0.553 ms 2.114 ms 0.775 ms # 对方pod地址
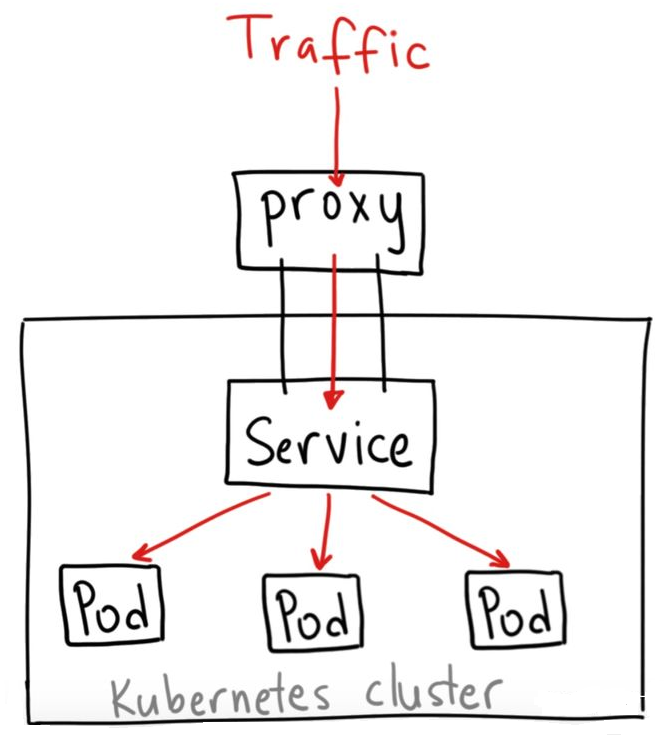
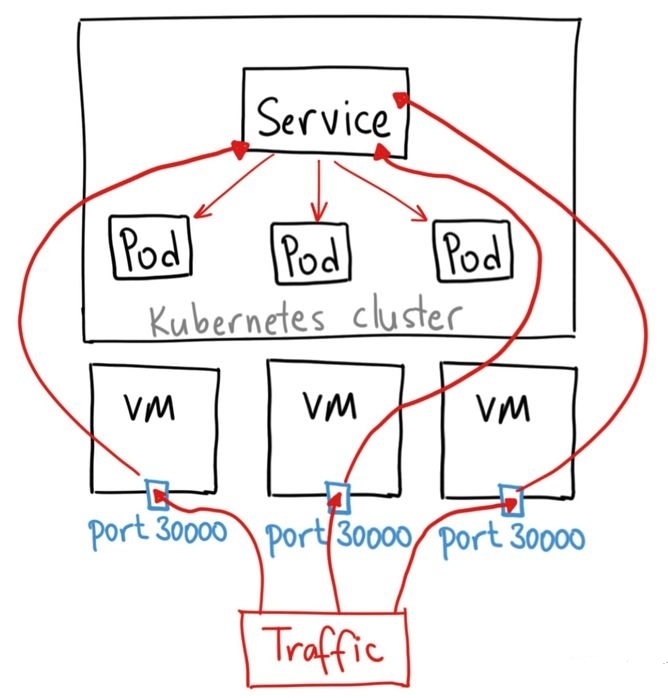
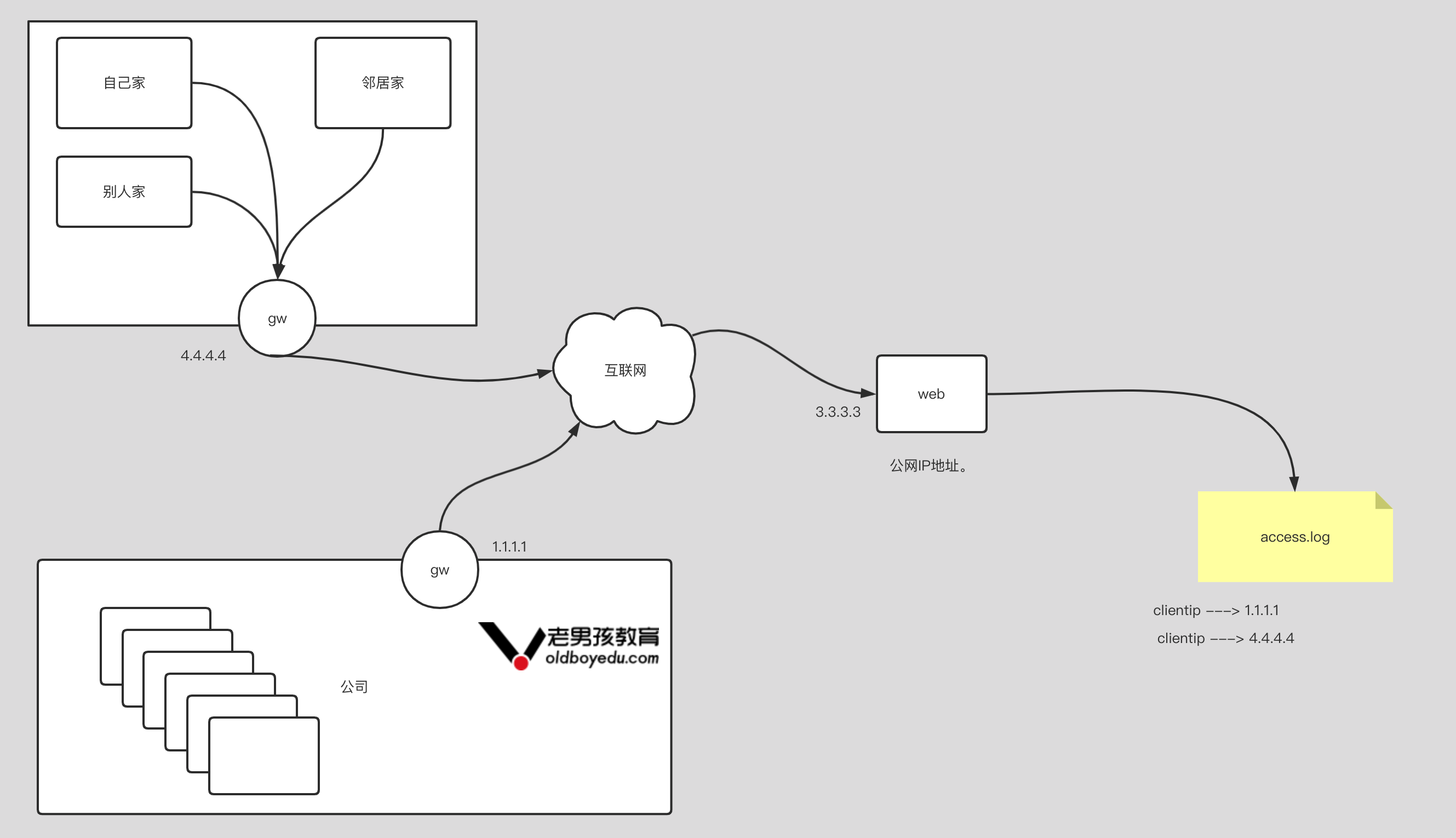
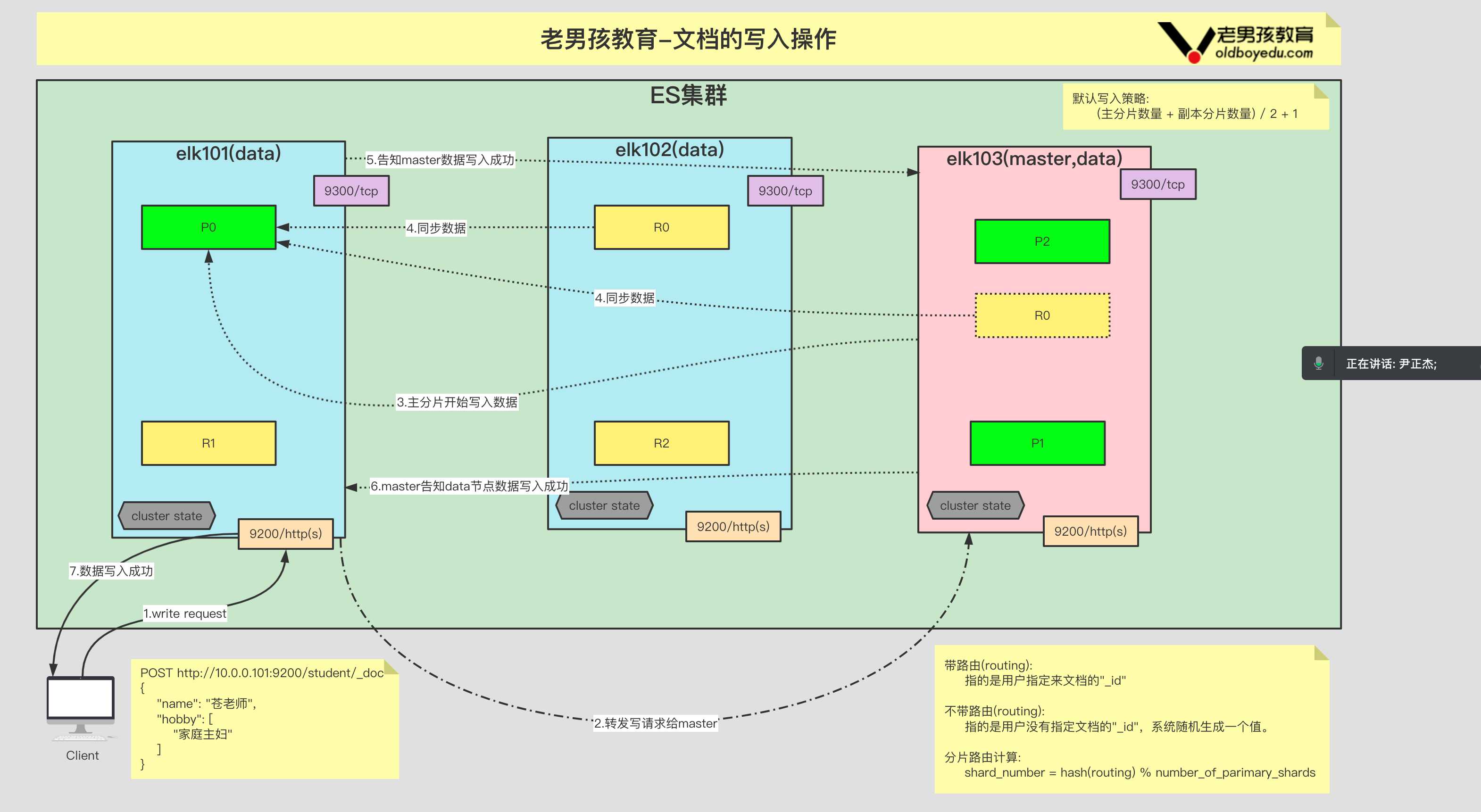
请求流量首先到达外部负载均衡器,由其调度至某个工作节点之上,而后再由工作节点的 netfilter(kube-proxy)组件上的规则(iptables 或 ipvs)调度至某个目标 Pod 对象
集群外的流量先进入节点网络,再进入service 网络,最后进入pod 网络
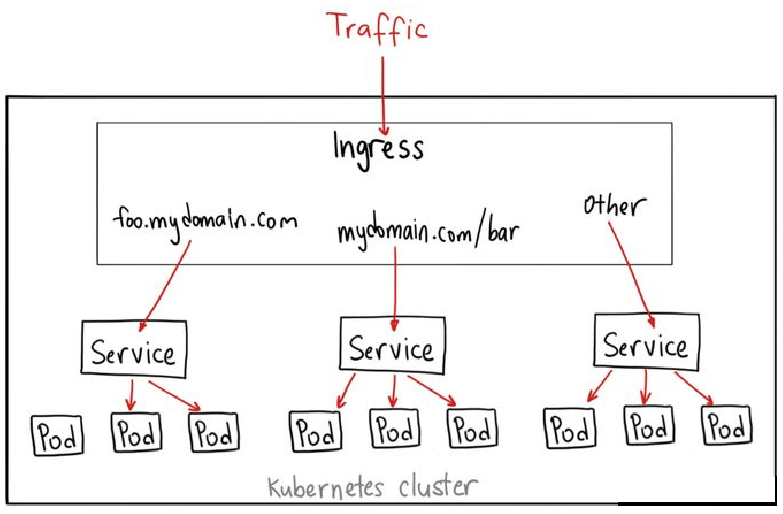
网络策略
网络策略(Network Policy)是用于控制分组的 Pod 资源彼此之间如何进行通信,以及分组的 Pod 资源如何与其他网络端点进行通信的规范。它用于为 Kubernetes 实现更为精细的流量控制,实现租户隔离机制。Kubernetes 使用标准的资源对象“NetworkPolicy”供管理员按需定义网络访问控制策略
Prefix flag strings with ETCDCTL_, convert all letters to upper-case, and replace dash(-) with underscore(_). Note that the environment variables with the prefix ETCDCTL_ can only be used with the etcdctl global flags. Also, the environment variable ETCDCTL_API is a special case variable for etcdctl internal use only.
Key-value commands
PUT [options] <key> <value>
PUT assigns the specified value with the specified key. If key already holds a value, it is overwritten.
RPC: Put
Options
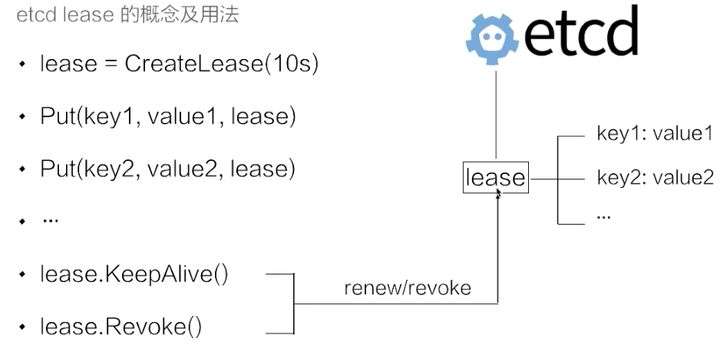
lease – lease ID (in hexadecimal) to attach to the key.
prev-kv – return the previous key-value pair before modification.
ignore-value – updates the key using its current value.
ignore-lease – updates the key using its current lease.
Output
OK
Examples
1 2 3 4 5 6 7
./etcdctl put foo bar --lease=1234abcd # OK ./etcdctl get foo # foo # bar ./etcdctl put foo --ignore-value # to detache lease # OK
1 2 3 4 5 6 7
./etcdctl put foo bar --lease=1234abcd # OK ./etcdctl put foo bar1 --ignore-lease # to use existing lease 1234abcd # OK ./etcdctl get foo # foo # bar1
1 2 3 4 5 6 7
./etcdctl put foo bar1 --prev-kv # OK # foo # bar ./etcdctl get foo # foo # bar1
Remarks
If <value> isn’t given as command line argument, this command tries to read the value from standard input.
When <value> begins with ‘-‘, <value> is interpreted as a flag. Insert ‘–’ for workaround:
1 2
./etcdctl put <key> -- <value> ./etcdctl put -- <key> <value>
Providing <value> in a new line after using carriage return is not supported and etcdctl may hang in that case. For example, following case is not supported:
1 2
./etcdctl put <key>\r <value>
A <value> can have multiple lines or spaces but it must be provided with a double-quote as demonstrated below:
1
./etcdctl put foo "bar1 2 3"
GET [options] <key> [range_end]
GET gets the key or a range of keys [key, range_end) if range_end is given.
RPC: Range
Options
hex – print out key and value as hex encode string
limit – maximum number of results
prefix – get keys by matching prefix
order – order of results; ASCEND or DESCEND
sort-by – sort target; CREATE, KEY, MODIFY, VALUE, or VERSION
rev – specify the kv revision
print-value-only – print only value when used with write-out=simple
consistency – Linearizable(l) or Serializable(s)
from-key – Get keys that are greater than or equal to the given key using byte compare
keys-only – Get only the keys
Output
<key>\n<value>\n<next_key>\n<next_value>…
Examples
First, populate etcd with some keys:
1 2 3 4 5 6 7 8
./etcdctl put foo bar # OK ./etcdctl put foo1 bar1 # OK ./etcdctl put foo2 bar2 # OK ./etcdctl put foo3 bar3 # OK
Get the key named foo:
1 2 3
./etcdctl get foo # foo # bar
Get all keys:
1 2 3 4 5 6 7 8 9
./etcdctl get --from-key '' # foo # bar # foo1 # bar1 # foo2 # foo2 # foo3 # bar3
Get all keys with names greater than or equal to foo1:
If any key or value contains non-printable characters or control characters, simple formatted output can be ambiguous due to new lines. To resolve this issue, set --hex to hex encode all strings.
DEL [options] <key> [range_end]
Removes the specified key or range of keys [key, range_end) if range_end is given.
RPC: DeleteRange
Options
prefix – delete keys by matching prefix
prev-kv – return deleted key-value pairs
from-key – delete keys that are greater than or equal to the given key using byte compare
Output
Prints the number of keys that were removed in decimal if DEL succeeded.
Examples
1 2 3 4 5
./etcdctl put foo bar # OK ./etcdctl del foo # 1 ./etcdctl get foo
1 2 3 4 5 6 7
./etcdctl put key val # OK ./etcdctl del --prev-kv key # 1 # key # val ./etcdctl get key
1 2 3 4 5 6 7 8 9
./etcdctl put a 123 # OK ./etcdctl put b 456 # OK ./etcdctl put z 789 # OK ./etcdctl del --from-key a # 3 ./etcdctl get --from-key a
1 2 3 4 5 6 7 8 9
./etcdctl put zoo val # OK ./etcdctl put zoo1 val1 # OK ./etcdctl put zoo2 val2 # OK ./etcdctl del --prefix zoo # 3 ./etcdctl get zoo2
TXN [options]
TXN reads multiple etcd requests from standard input and applies them as a single atomic transaction. A transaction consists of list of conditions, a list of requests to apply if all the conditions are true, and a list of requests to apply if any condition is false.
RPC: Txn
Options
hex – print out keys and values as hex encoded strings.
interactive – input transaction with interactive prompting.
SUCCESS if etcd processed the transaction success list, FAILURE if etcd processed the transaction failure list. Prints the output for each command in the executed request list, each separated by a blank line.
Examples
txn in interactive mode:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
./etcdctl txn -i # compares: mod("key1") > "0"
# success requests (get, put, delete): put key1 "overwrote-key1"
# failure requests (get, put, delete): put key1 "created-key1" put key2 "some extra key"
# FAILURE
# OK
# OK
txn in non-interactive mode:
1 2 3 4 5 6 7 8 9 10 11 12 13 14
./etcdctl txn <<<'mod("key1") > "0" put key1 "overwrote-key1" put key1 "created-key1" put key2 "some extra key" '
# FAILURE
# OK
# OK
Remarks
When using multi-line values within a TXN command, newlines must be represented as \n. Literal newlines will cause parsing failures. This differs from other commands (such as PUT) where the shell will convert literal newlines for us. For example:
1 2 3 4 5 6 7 8 9 10 11 12 13 14
./etcdctl txn <<<'mod("key1") > "0" put key1 "overwrote-key1" put key1 "created-key1" put key2 "this is\na multi-line\nvalue" '
# FAILURE
# OK
# OK
COMPACTION [options] <revision>
COMPACTION discards all etcd event history prior to a given revision. Since etcd uses a multiversion concurrency control model, it preserves all key updates as event history. When the event history up to some revision is no longer needed, all superseded keys may be compacted away to reclaim storage space in the etcd backend database.
RPC: Compact
Options
physical – ‘true’ to wait for compaction to physically remove all old revisions
Watch watches events stream on keys or prefixes, [key or prefix, range_end) if range_end is given. The watch command runs until it encounters an error or is terminated by the user. If range_end is given, it must be lexicographically greater than key or “\x00”.
RPC: Watch
Options
hex – print out key and value as hex encode string
interactive – begins an interactive watch session
prefix – watch on a prefix if prefix is set.
prev-kv – get the previous key-value pair before the event happens.
rev – the revision to start watching. Specifying a revision is useful for observing past events.
./etcdctl -w json member list # {"header":{"cluster_id":17237436991929493444,"member_id":9372538179322589801,"raft_term":2},"members":[{"ID":9372538179322589801,"name":"infra1","peerURLs":["http://127.0.0.1:12380"],"clientURLs":["http://127.0.0.1:2379"]},{"ID":10501334649042878790,"name":"infra2","peerURLs":["http://127.0.0.1:22380"],"clientURLs":["http://127.0.0.1:22379"]},{"ID":18249187646912138824,"name":"infra3","peerURLs":["http://127.0.0.1:32380"],"clientURLs":["http://127.0.0.1:32379"]}]}
1 2 3 4 5 6 7 8
./etcdctl -w table member list +------------------+---------+--------+------------------------+------------------------+ | ID | STATUS | NAME | PEER ADDRS | CLIENT ADDRS | +------------------+---------+--------+------------------------+------------------------+ | 8211f1d0f64f3269 | started | infra1 | http://127.0.0.1:12380 | http://127.0.0.1:2379 | | 91bc3c398fb3c146 | started | infra2 | http://127.0.0.1:22380 | http://127.0.0.1:22379 | | fd422379fda50e48 | started | infra3 | http://127.0.0.1:32380 | http://127.0.0.1:32379 | +------------------+---------+--------+------------------------+------------------------+
ENDPOINT <subcommand>
ENDPOINT provides commands for querying individual endpoints.
Options
cluster – fetch and use all endpoints from the etcd cluster member list
ENDPOINT HEALTH
ENDPOINT HEALTH checks the health of the list of endpoints with respect to cluster. An endpoint is unhealthy when it cannot participate in consensus with the rest of the cluster.
Output
If an endpoint can participate in consensus, prints a message indicating the endpoint is healthy. If an endpoint fails to participate in consensus, prints a message indicating the endpoint is unhealthy.
Example
Check the default endpoint’s health:
1 2
./etcdctl endpoint health # 127.0.0.1:2379 is healthy: successfully committed proposal: took = 2.095242ms
Check all endpoints for the cluster associated with the default endpoint:
1 2 3 4
./etcdctl endpoint --cluster health # http://127.0.0.1:2379 is healthy: successfully committed proposal: took = 1.060091ms # http://127.0.0.1:22379 is healthy: successfully committed proposal: took = 903.138µs # http://127.0.0.1:32379 is healthy: successfully committed proposal: took = 1.113848ms
ENDPOINT STATUS
ENDPOINT STATUS queries the status of each endpoint in the given endpoint list.
Output
Simple format
Prints a humanized table of each endpoint URL, ID, version, database size, leadership status, raft term, and raft status.
JSON format
Prints a line of JSON encoding each endpoint URL, ID, version, database size, leadership status, raft term, and raft status.
alarm:<alarm type> if alarm is present and disarmed.
Examples
1
./etcdctl alarm disarm
If NOSPACE alarm is present:
1 2
./etcdctl alarm disarm # alarm:NOSPACE
ALARM LIST
alarm list lists all alarms.
RPC: Alarm
Output
alarm:<alarm type> if alarm is present, empty string if no alarms present.
Examples
1
./etcdctl alarm list
If NOSPACE alarm is present:
1 2
./etcdctl alarm list # alarm:NOSPACE
DEFRAG [options]
DEFRAG defragments the backend database file for a set of given endpoints while etcd is running, or directly defragments an etcd data directory while etcd is not running. When an etcd member reclaims storage space from deleted and compacted keys, the space is kept in a free list and the database file remains the same size. By defragmenting the database, the etcd member releases this free space back to the file system.
Note that defragmentation to a live member blocks the system from reading and writing data while rebuilding its states.
Note that defragmentation request does not get replicated over cluster. That is, the request is only applied to the local node. Specify all members in --endpoints flag or --cluster flag to automatically find all cluster members.
Options
data-dir – Optional. If present, defragments a data directory not in use by etcd.
Output
For each endpoints, prints a message indicating whether the endpoint was successfully defragmented.
Example
1 2 3
./etcdctl --endpoints=localhost:2379,badendpoint:2379 defrag # Finished defragmenting etcd member[localhost:2379] # Failed to defragment etcd member[badendpoint:2379] (grpc: timed out trying to connect)
Run defragment operations for all endpoints in the cluster associated with the default endpoint:
To defragment a data directory directly, use the --data-dir flag:
1 2 3 4
# Defragment while etcd is not running ./etcdctl defrag --data-dir default.etcd # success (exit status 0) # Error: cannot open database at default.etcd/member/snap/db
Remarks
DEFRAG returns a zero exit code only if it succeeded defragmenting all given endpoints.
SNAPSHOT <subcommand>
SNAPSHOT provides commands to restore a snapshot of a running etcd server into a fresh cluster.
SNAPSHOT SAVE <filename>
SNAPSHOT SAVE writes a point-in-time snapshot of the etcd backend database to a file.
Output
The backend snapshot is written to the given file path.
Example
Save a snapshot to “snapshot.db”:
1
./etcdctl snapshot save snapshot.db
SNAPSHOT RESTORE [options] <filename>
SNAPSHOT RESTORE creates an etcd data directory for an etcd cluster member from a backend database snapshot and a new cluster configuration. Restoring the snapshot into each member for a new cluster configuration will initialize a new etcd cluster preloaded by the snapshot data.
Options
The snapshot restore options closely resemble to those used in the etcd command for defining a cluster.
data-dir – Path to the data directory. Uses <name>.etcd if none given.
wal-dir – Path to the WAL directory. Uses data directory if none given.
initial-cluster – The initial cluster configuration for the restored etcd cluster.
initial-cluster-token – Initial cluster token for the restored etcd cluster.
initial-advertise-peer-urls – List of peer URLs for the member being restored.
name – Human-readable name for the etcd cluster member being restored.
skip-hash-check – Ignore snapshot integrity hash value (required if copied from data directory)
Output
A new etcd data directory initialized with the snapshot.
Example
Save a snapshot, restore into a new 3 node cluster, and start the cluster:
# endpoints should include leader node ./etcdctl --endpoints ${transferee_ep} move-leader ${transferee_id} # Error: no leader endpoint given at [localhost:22379 localhost:32379]
# request to leader with target node ID ./etcdctl --endpoints ${leader_ep} move-leader ${transferee_id} # Leadership transferred from 45ddc0e800e20b93 to c89feb932daef420
Concurrency commands
LOCK [options] <lockname> [command arg1 arg2 …]
LOCK acquires a distributed mutex with a given name. Once the lock is acquired, it will be held until etcdctl is terminated.
Options
ttl - time out in seconds of lock session.
Output
Once the lock is acquired but no command is given, the result for the GET on the unique lock holder key is displayed.
If a command is given, it will be executed with environment variables ETCD_LOCK_KEY and ETCD_LOCK_REV set to the lock’s holder key and revision.
LOCK returns a zero exit code only if it is terminated by a signal and releases the lock.
If LOCK is abnormally terminated or fails to contact the cluster to release the lock, the lock will remain held until the lease expires. Progress may be delayed by up to the default lease length of 60 seconds.
ELECT [options] <election-name> [proposal]
ELECT participates on a named election. A node announces its candidacy in the election by providing a proposal value. If a node wishes to observe the election, ELECT listens for new leaders values. Whenever a leader is elected, its proposal is given as output.
Options
listen – observe the election.
Output
If a candidate, ELECT displays the GET on the leader key once the node is elected election.
If observing, ELECT streams the result for a GET on the leader key for the current election and all future elections.
ELECT returns a zero exit code only if it is terminated by a signal and can revoke its candidacy or leadership, if any.
If a candidate is abnormally terminated, election rogress may be delayed by up to the default lease length of 60 seconds.
Authentication commands
AUTH <enable or disable>
auth enable activates authentication on an etcd cluster and auth disable deactivates. When authentication is enabled, etcd checks all requests for appropriate authorization.
RPC: AuthEnable/AuthDisable
Output
Authentication Enabled.
Examples
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
./etcdctl user add root # Password of root:#type password for root # Type password of root again for confirmation:#re-type password for root # User root created ./etcdctl user grant-role root root # Role root is granted to user root ./etcdctl user get root # User: root # Roles: root ./etcdctl role add root # Role root created ./etcdctl role get root # Role root # KV Read: # KV Write: ./etcdctl auth enable # Authentication Enabled
ROLE <subcommand>
ROLE is used to specify different roles which can be assigned to etcd user(s).
ROLE ADD <role name>
role add creates a role.
RPC: RoleAdd
Output
Role <role name> created.
Examples
1 2
./etcdctl --user=root:123 role add myrole # Role myrole created
ROLE GET <role name>
role get lists detailed role information.
RPC: RoleGet
Output
Detailed role information.
Examples
1 2 3 4 5 6
./etcdctl --user=root:123 role get myrole # Role myrole # KV Read: # foo # KV Write: # foo
ROLE DELETE <role name>
role delete deletes a role.
RPC: RoleDelete
Output
Role <role name> deleted.
Examples
1 2
./etcdctl --user=root:123 role delete myrole # Role myrole deleted
ROLE LIST <role name>
role list lists all roles in etcd.
RPC: RoleList
Output
A role per line.
Examples
1 2 3 4
./etcdctl --user=root:123 role list # roleA # roleB # myrole
ROLE GRANT-PERMISSION [options] <role name> <permission type> <key> [endkey]
role grant-permission grants a key to a role.
RPC: RoleGrantPermission
Options
from-key – grant a permission of keys that are greater than or equal to the given key using byte compare
prefix – grant a prefix permission
Output
Role <role name> updated.
Examples
Grant read and write permission on the key foo to role myrole:
1 2
./etcdctl --user=root:123 role grant-permission myrole readwrite foo # Role myrole updated
Grant read permission on the wildcard key pattern foo/* to role myrole:
1 2
./etcdctl --user=root:123 role grant-permission --prefix myrole readwrite foo/ # Role myrole updated
ROLE REVOKE-PERMISSION <role name> <permission type> <key> [endkey]
role revoke-permission revokes a key from a role.
RPC: RoleRevokePermission
Options
from-key – revoke a permission of keys that are greater than or equal to the given key using byte compare
prefix – revoke a prefix permission
Output
Permission of key <key> is revoked from role <role name> for single key. Permission of range [<key>, <endkey>) is revoked from role <role name> for a key range. Exit code is zero.
Examples
1 2
./etcdctl --user=root:123 role revoke-permission myrole foo # Permission of key foo is revoked from role myrole
USER <subcommand>
USER provides commands for managing users of etcd.
USER ADD <user name or user:password> [options]
user add creates a user.
RPC: UserAdd
Options
interactive – Read password from stdin instead of interactive terminal
Output
User <user name> created.
Examples
1 2 3 4
./etcdctl --user=root:123 user add myuser # Password of myuser: #type password for my user # Type password of myuser again for confirmation:#re-type password for my user # User myuser created
USER GET <user name> [options]
user get lists detailed user information.
RPC: UserGet
Options
detail – Show permissions of roles granted to the user
Output
Detailed user information.
Examples
1 2 3
./etcdctl --user=root:123 user get myuser # User: myuser # Roles:
USER DELETE <user name>
user delete deletes a user.
RPC: UserDelete
Output
User <user name> deleted.
Examples
1 2
./etcdctl --user=root:123 user delete myuser # User myuser deleted
USER LIST
user list lists detailed user information.
RPC: UserList
Output
List of users, one per line.
Examples
1 2 3 4
./etcdctl --user=root:123 user list # user1 # user2 # myuser
USER PASSWD <user name> [options]
user passwd changes a user’s password.
RPC: UserChangePassword
Options
interactive – if true, read password in interactive terminal
Output
Password updated.
Examples
1 2 3 4
./etcdctl --user=root:123 user passwd myuser # Password of myuser: #type new password for my user # Type password of myuser again for confirmation: #re-type the new password for my user # Password updated
USER GRANT-ROLE <user name> <role name>
user grant-role grants a role to a user
RPC: UserGrantRole
Output
Role <role name> is granted to user <user name>.
Examples
1 2
./etcdctl --user=root:123 user grant-role userA roleA # Role roleA is granted to user userA
USER REVOKE-ROLE <user name> <role name>
user revoke-role revokes a role from a user
RPC: UserRevokeRole
Output
Role <role name> is revoked from user <user name>.
Examples
1 2
./etcdctl --user=root:123 user revoke-role userA roleA # Role roleA is revoked from user userA
Utility commands
MAKE-MIRROR [options] <destination>
make-mirror mirrors a key prefix in an etcd cluster to a destination etcd cluster.
Options
dest-cacert – TLS certificate authority file for destination cluster
dest-cert – TLS certificate file for destination cluster
dest-key – TLS key file for destination cluster
prefix – The key-value prefix to mirror
dest-prefix – The destination prefix to mirror a prefix to a different prefix in the destination cluster
no-dest-prefix – Mirror key-values to the root of the destination cluster
dest-insecure-transport – Disable transport security for client connections
Output
The approximate total number of keys transferred to the destination cluster, updated every 30 seconds.
Migrates keys in a v2 store to a v3 mvcc store. Users should run migration command for all members in the cluster.
Options
data-dir – Path to the data directory
wal-dir – Path to the WAL directory
transformer – Path to the user-provided transformer program (default if not provided)
Output
No output on success.
Default transformer
If user does not provide a transformer program, migrate command will use the default transformer. The default transformer transforms storev2 formatted keys into mvcc formatted keys according to the following Go program:
Users can provide a customized 1:n transformer function that transforms a key from the v2 store to any number of keys in the mvcc store. The migration program writes JSON formatted v2 store keys to the transformer program’s stdin, reads protobuf formatted mvcc keys back from the transformer program’s stdout, and finishes migration by saving the transformed keys into the mvcc store.
The provided transformer should read until EOF and flush the stdout before exiting to ensure data integrity.
./etcdctl version # etcdctl version: 3.1.0-alpha.0+git # API version: 3.1
CHECK <subcommand>
CHECK provides commands for checking properties of the etcd cluster.
CHECK PERF [options]
CHECK PERF checks the performance of the etcd cluster for 60 seconds. Running the check perf often can create a large keyspace history which can be auto compacted and defragmented using the --auto-compact and --auto-defrag options as described below.
prefix – the prefix for writing the performance check’s keys.
auto-compact – if true, compact storage with last revision after test is finished.
auto-defrag – if true, defragment storage after test is finished.
Output
Prints the result of performance check on different criteria like throughput. Also prints an overall status of the check as pass or fail.
Examples
Shows examples of both, pass and fail, status. The failure is due to the fact that a large workload was tried on a single node etcd cluster running on a laptop environment created for development and testing purpose.
1 2 3 4 5 6 7 8 9 10 11 12
./etcdctl check perf --load="s" # 60 / 60 Booooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooo! 100.00%1m0s # PASS: Throughput is 150 writes/s # PASS: Slowest request took 0.087509s # PASS: Stddev is 0.011084s # PASS ./etcdctl check perf --load="l" # 60 / 60 Booooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooo! 100.00%1m0s # FAIL: Throughput too low: 6808 writes/s # PASS: Slowest request took 0.228191s # PASS: Stddev is 0.033547s # FAIL
CHECK DATASCALE [options]
CHECK DATASCALE checks the memory usage of holding data for different workloads on a given server endpoint. Running the check datascale often can create a large keyspace history which can be auto compacted and defragmented using the --auto-compact and --auto-defrag options as described below.
prefix – the prefix for writing the datascale check’s keys.
auto-compact – if true, compact storage with last revision after test is finished.
auto-defrag – if true, defragment storage after test is finished.
Output
Prints the system memory usage for a given workload. Also prints status of compact and defragment if related options are passed.
Examples
1 2 3 4 5 6 7
./etcdctl check datascale --load="s" --auto-compact=true --auto-defrag=true # Start data scale check for work load [10000 key-value pairs, 1024 bytes per key-value, 50 concurrent clients]. # Compacting with revision 18346204 # Compacted with revision 18346204 # Defragmenting "127.0.0.1:2379" # Defragmented "127.0.0.1:2379" # PASS: Approximate system memory used : 64.30 MB.
Exit codes
For all commands, a successful execution return a zero exit code. All failures will return non-zero exit codes.
Output formats
All commands accept an output format by setting -w or --write-out. All commands default to the “simple” output format, which is meant to be human-readable. The simple format is listed in each command’s Output description since it is customized for each command. If a command has a corresponding RPC, it will respect all output formats.
If a command fails, returning a non-zero exit code, an error string will be written to standard error regardless of output format.
Simple
A format meant to be easy to parse and human-readable. Specific to each command.
JSON
The JSON encoding of the command’s RPC response. Since etcd’s RPCs use byte strings, the JSON output will encode keys and values in base64.
Some commands without an RPC also support JSON; see the command’s Output description.
Protobuf
The protobuf encoding of the command’s RPC response. If an RPC is streaming, the stream messages will be concetenated. If an RPC is not given for a command, the protobuf output is not defined.
Fields
An output format similar to JSON but meant to parse with coreutils. For an integer field named Field, it writes a line in the format "Field" : %d where %d is go’s integer formatting. For byte array fields, it writes "Field" : %q where %q is go’s quoted string formatting (e.g., []byte{'a', '\n'} is written as "a\n").
Compatibility Support
etcdctl is still in its early stage. We try out best to ensure fully compatible releases, however we might break compatibility to fix bugs or improve commands. If we intend to release a version of etcdctl with backward incompatibilities, we will provide notice prior to release and have instructions on how to upgrade.
Input Compatibility
Input includes the command name, its flags, and its arguments. We ensure backward compatibility of the input of normal commands in non-interactive mode.
Output Compatibility
Output includes output from etcdctl and its exit code. etcdctl provides simple output format by default. We ensure compatibility for the simple output format of normal commands in non-interactive mode. Currently, we do not ensure backward compatibility for JSON format and the format in non-interactive mode. Currently, we do not ensure backward compatibility of utility commands.
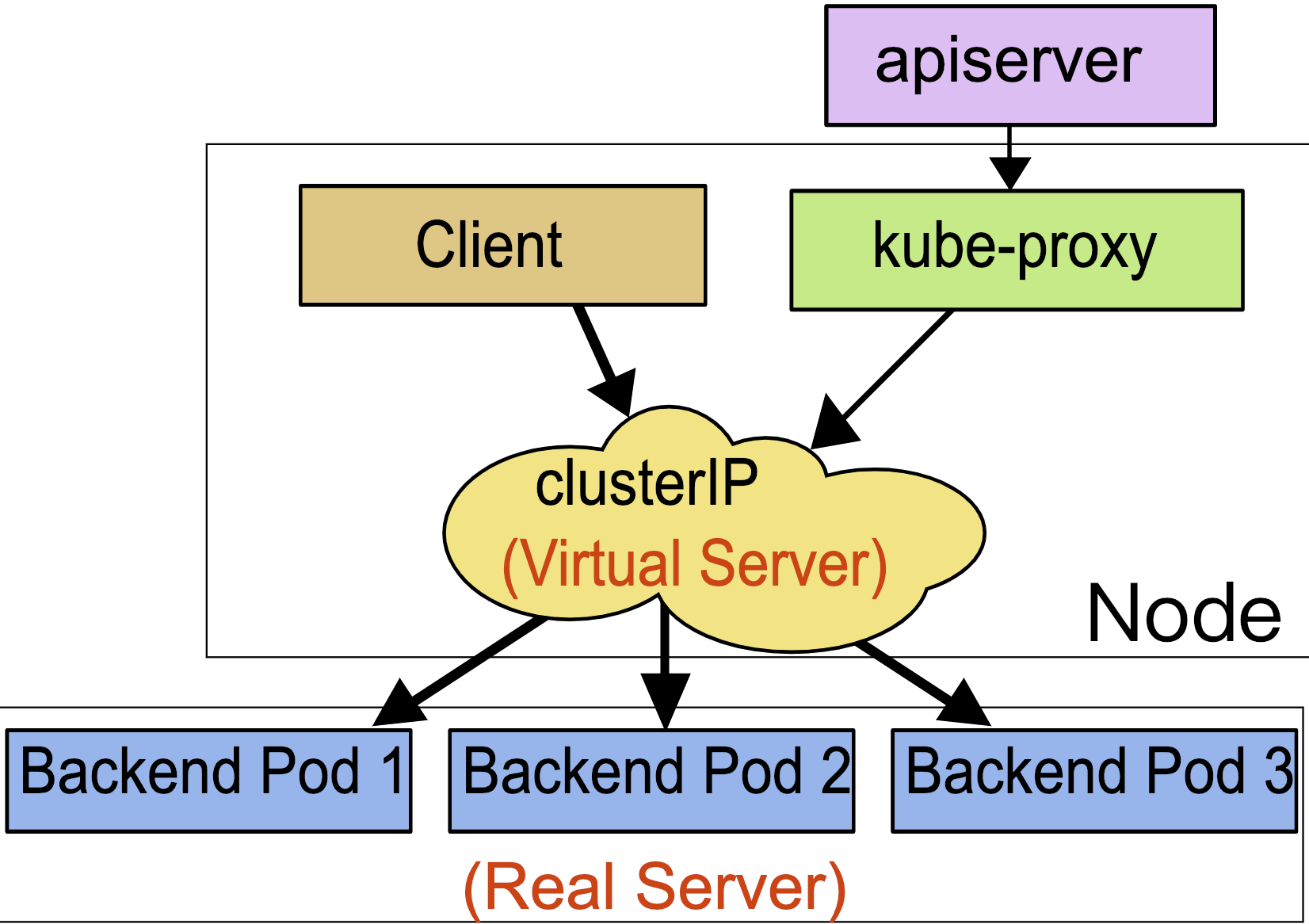
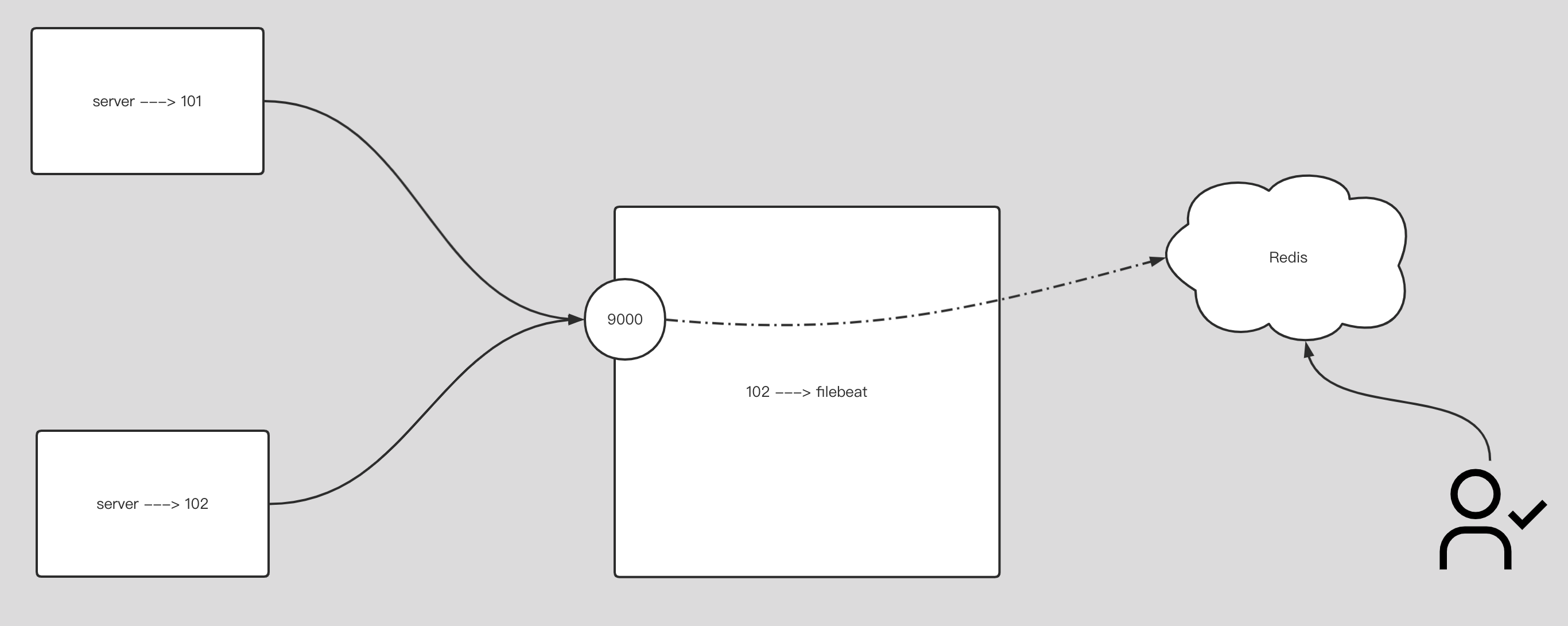
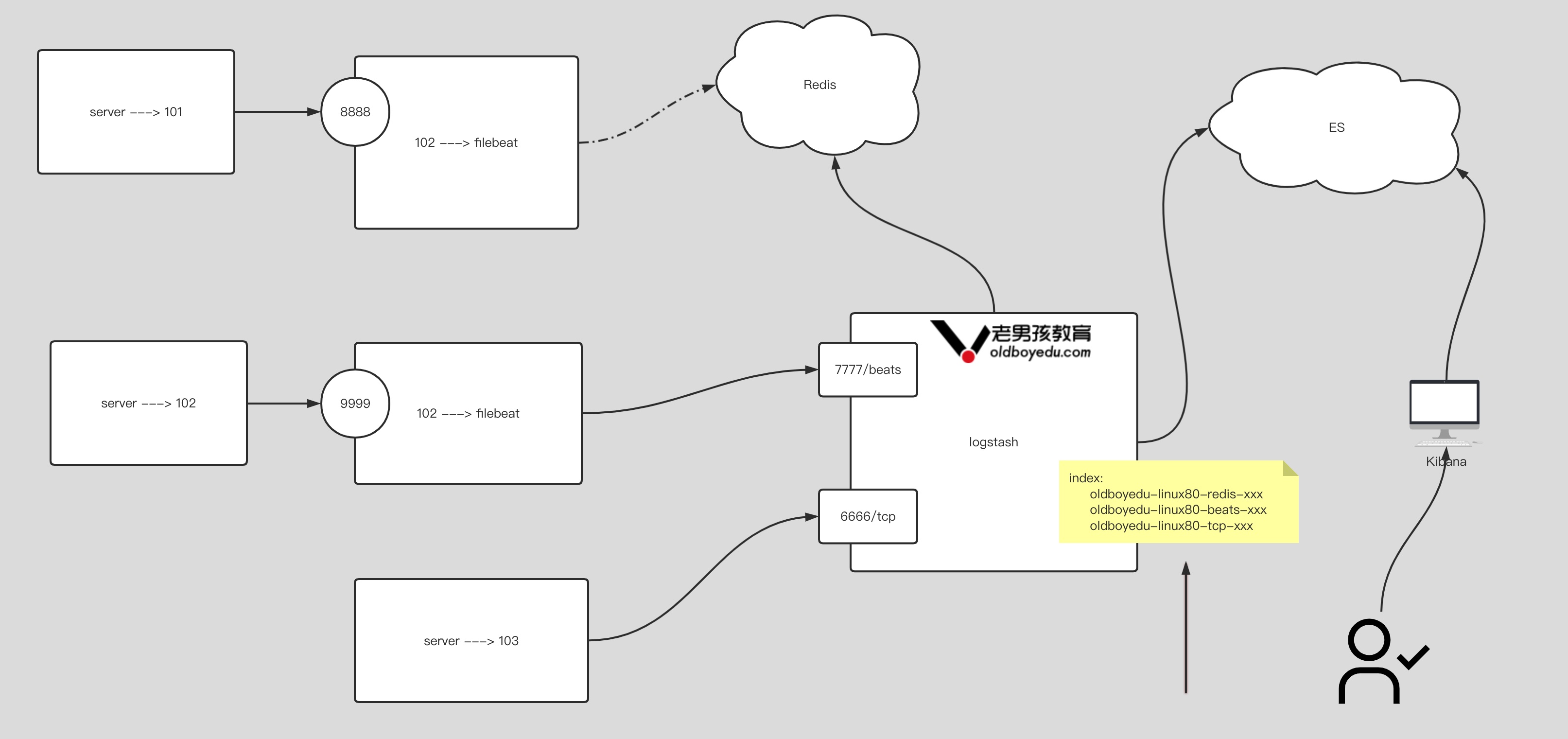
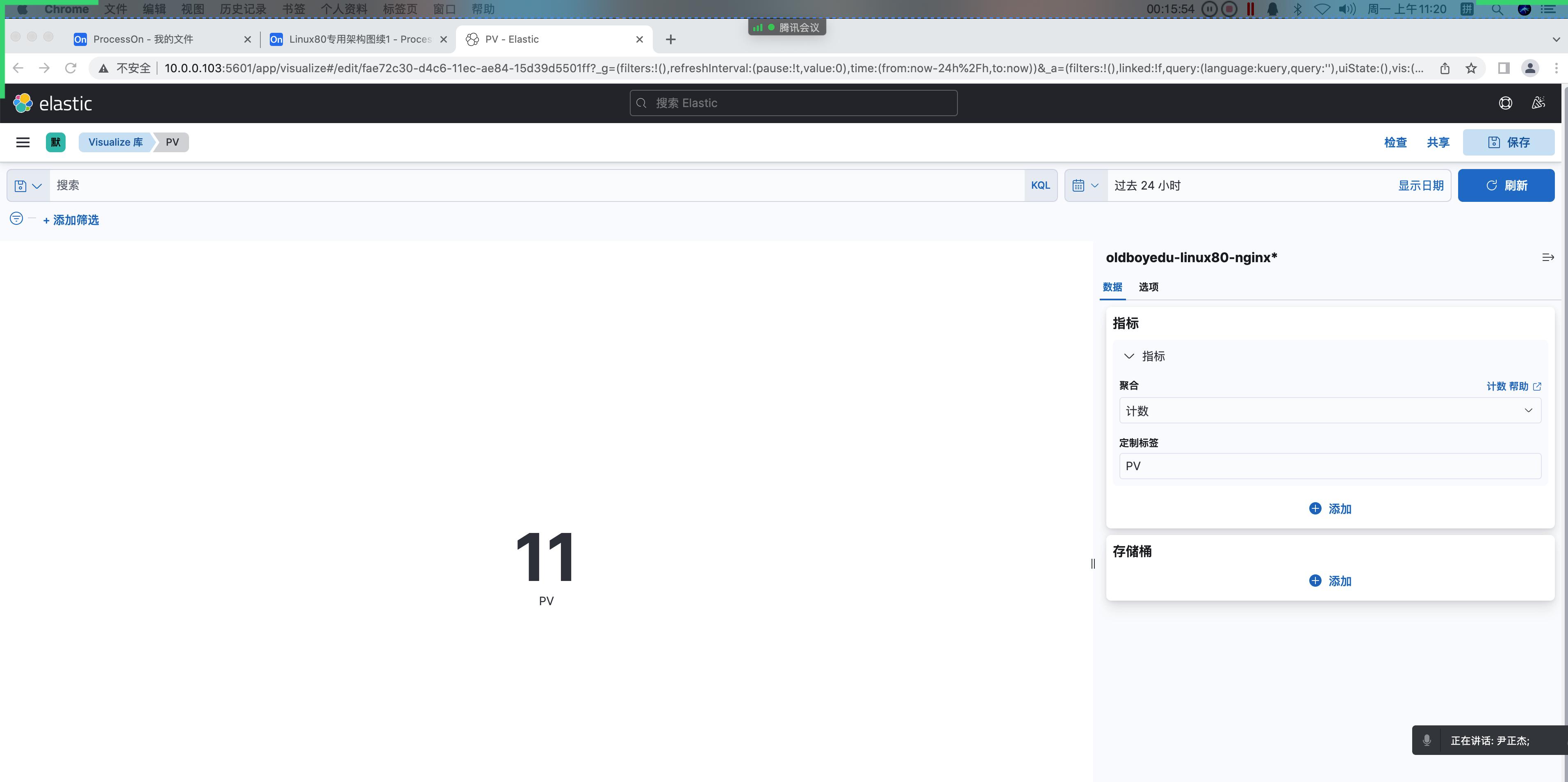
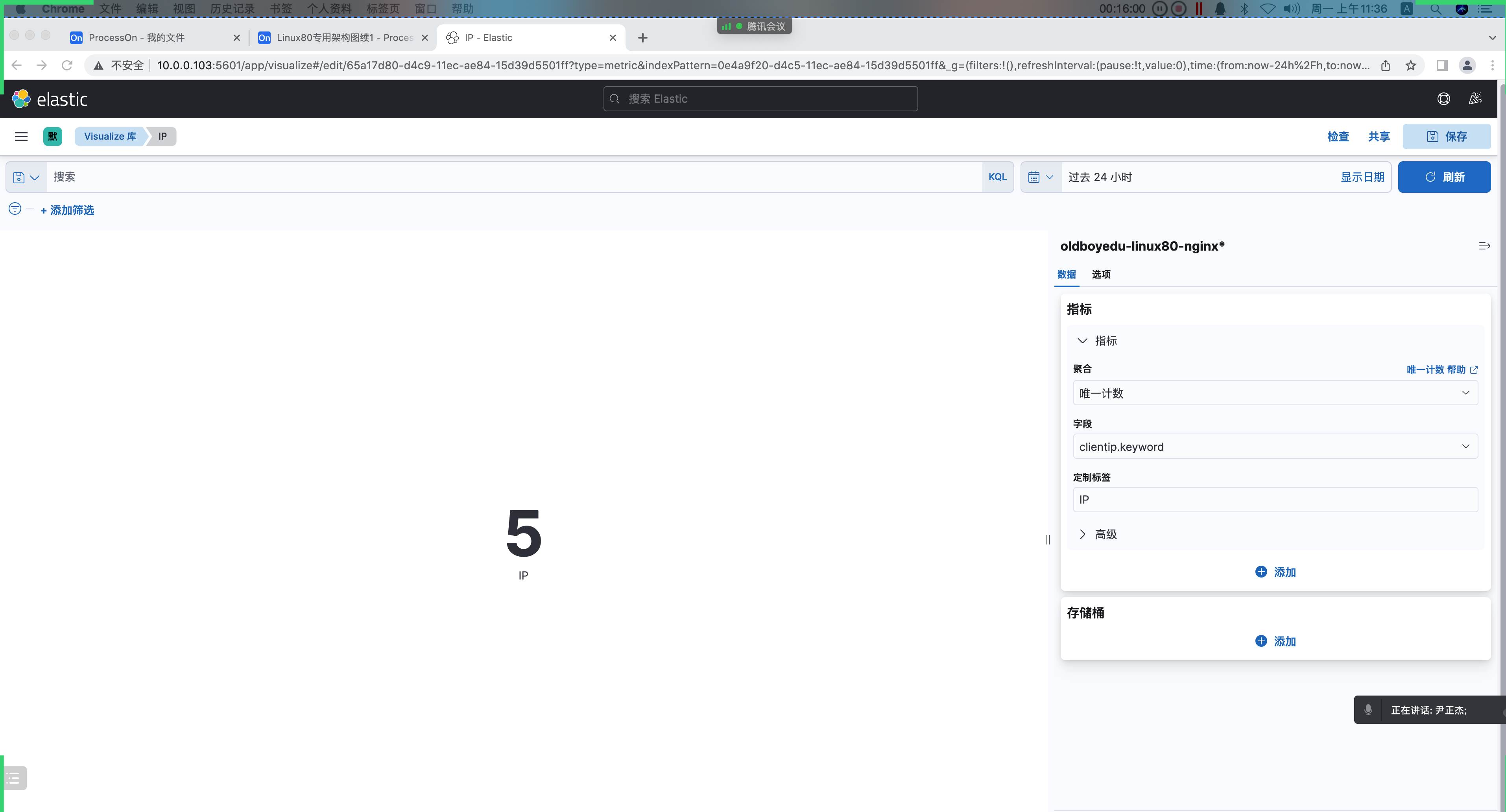
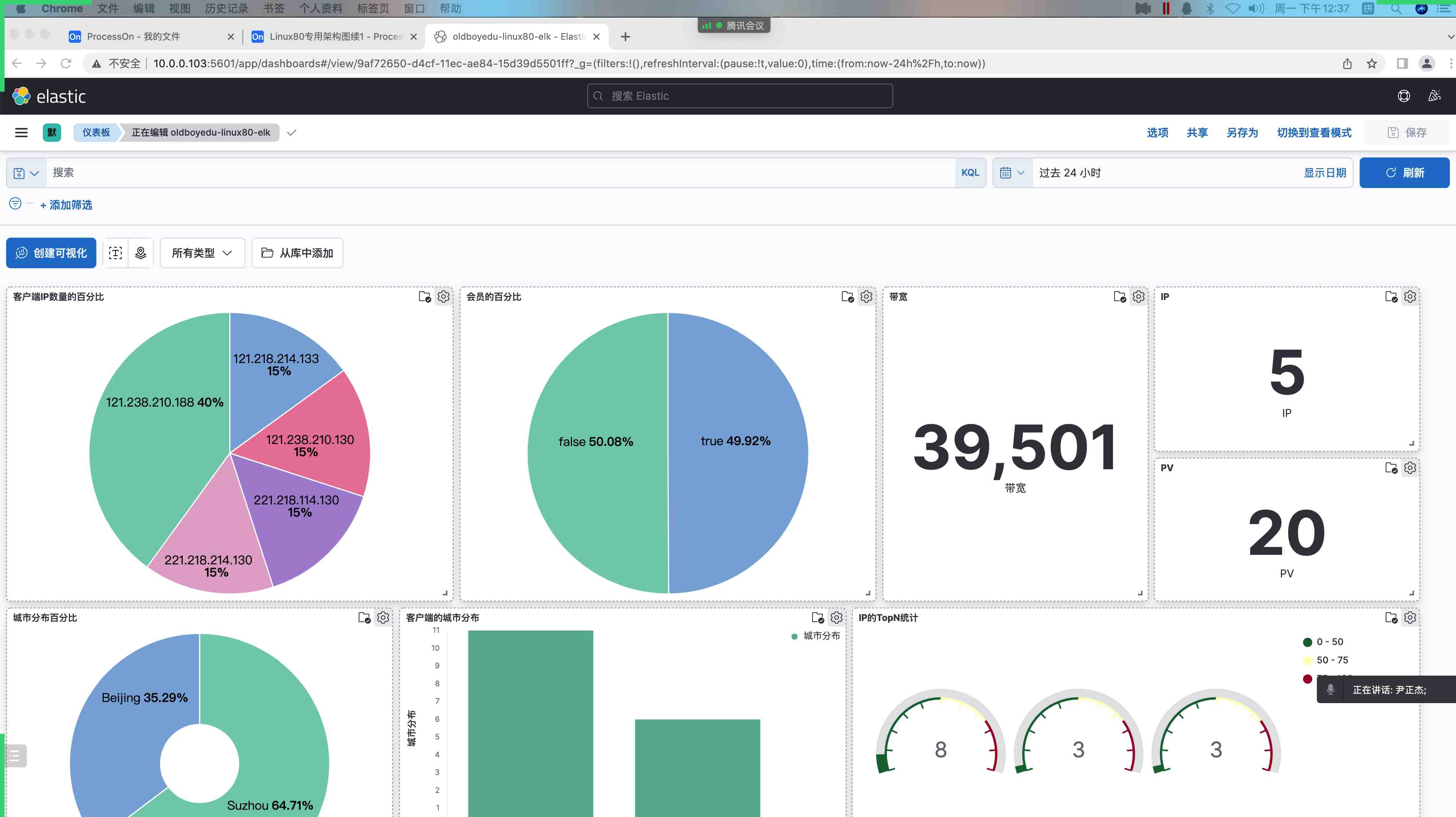
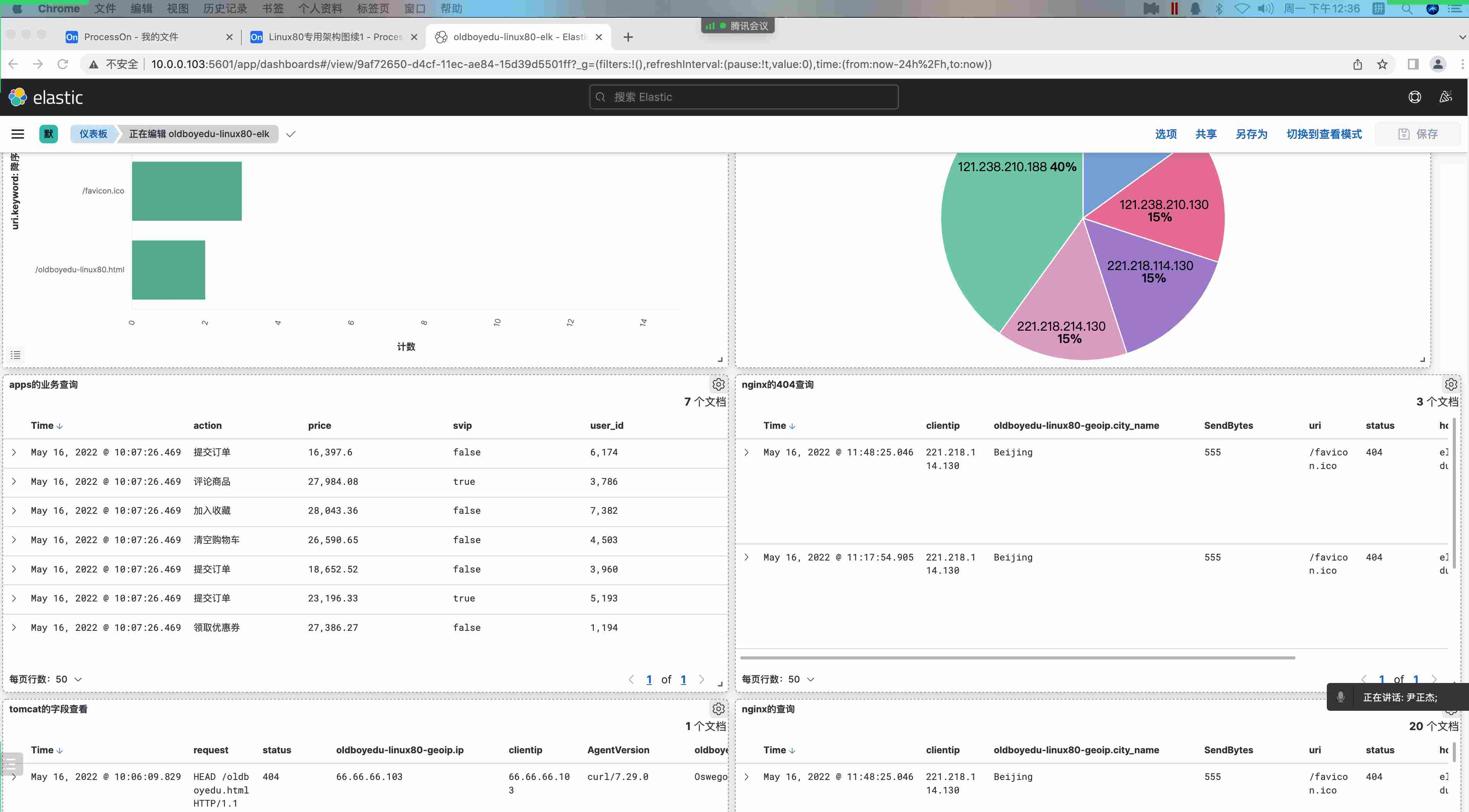
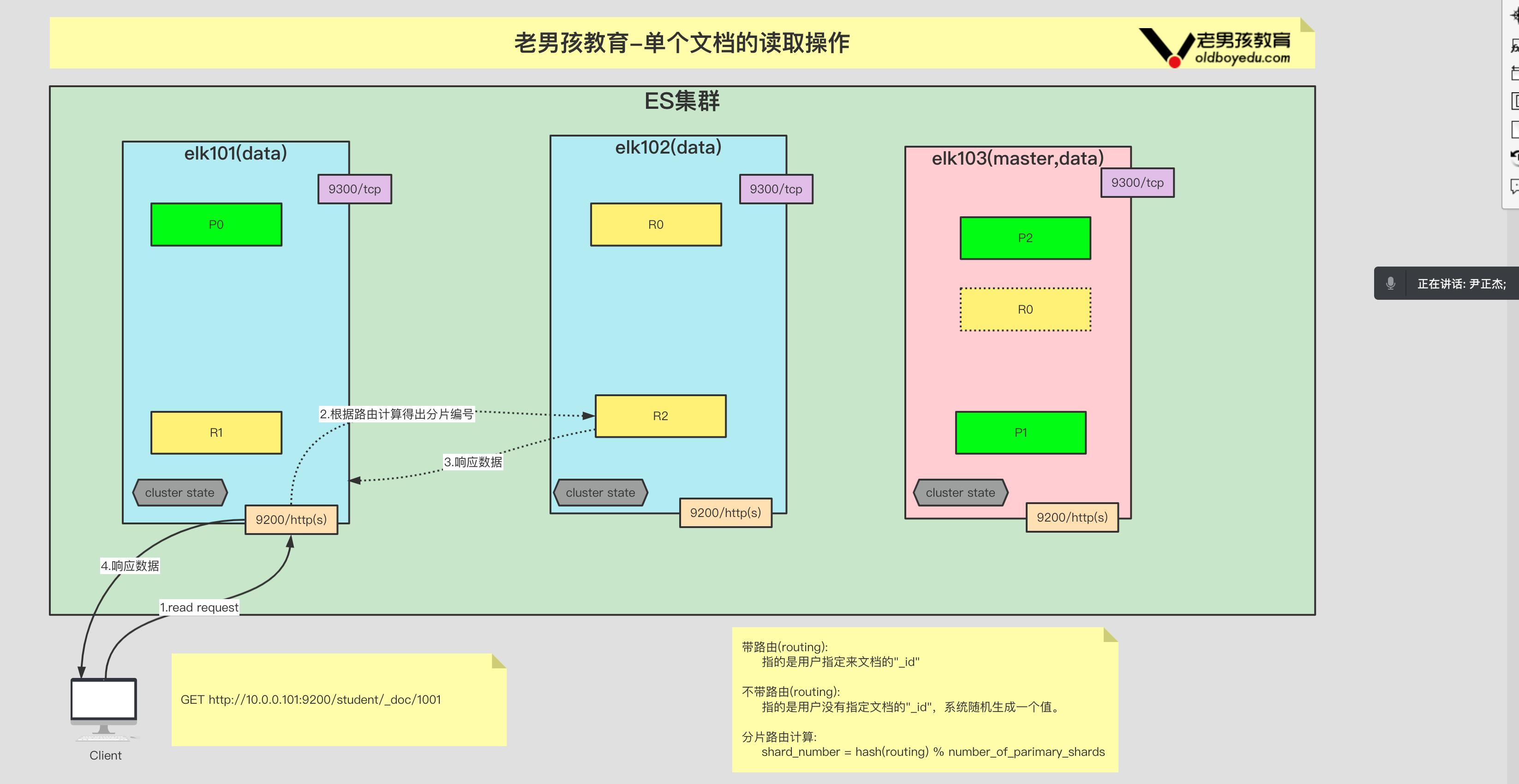
在 kubernetes 中,当创建带有多个副本的 deployment 时,kubernetes 会创建出多个 pod,此时即一个服务后端有多个容器,那么在 kubernetes 中负载均衡怎么做,容器漂移后 ip 也会发生变化,如何做服务发现以及会话保持?这就是 service 的作用,service 是一组具有相同 label pod 集合的抽象,集群内外的各个服务可以通过 service 进行互相通信,当创建一个 service 对象时也会对应创建一个 endpoint 对象,endpoint 是用来做容器发现的,service 只是将多个 pod 进行关联,实际的路由转发都是由 kubernetes 中的 kube-proxy 组件来实现,因此,service 必须结合 kube-proxy 使用,kube-proxy 组件可以运行在 kubernetes 集群中的每一个节点上也可以只运行在单独的几个节点上,其会根据 service 和 endpoints 的变动来改变节点上 iptables 或者 ipvs 中保存的路由规则
service 的工作原理
service 资源基于标签选择器将一组 pod 定义成一个逻辑组合,并通过自己的 ip 地址和端口调度代理请求至组内 pod 的对象之上,它向客户隐藏了真实的、处理用户请求的 pod 资源,使得客户端的请求看上去像是由 service 直接处理并进行响应一样
Service 对象的 IP 地址也称为 Cluster IP,是一种 VIP(虚拟 IP),k8s 集群内部的 VIP
service 网段不能跟机房网络、docker 网段、容器网段冲突,否则可能会导致网络不通
Service 以负载均衡的方式进行流量调度,Service 和 Pod 之间松耦合,创建 Service 和 Pod 的任务可由不同的用户分别完成
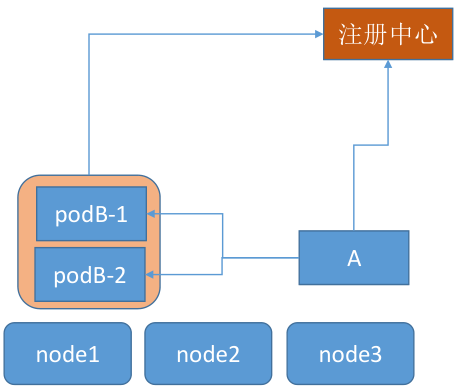
Service 通过 API Server 实时监控(watch)标签选择器匹配到的后端 Pod,不过 Service 并不直接链接至 Pod,它们中间还有一个中间层 --Endpoints资源对象,默认情况下,创建 Service 对象时,其关联的 Endpoints 对象会自动创建
endpoints controller 是负责生成和维护所有 endpoints 对象的控制器,监听 service 和对应 pod 的变化,更新对应 service 的 endpoints 对象。当用户创建 service 后 endpoints controller 会监听 pod 的状态,当 pod 处于 running 且准备就绪时,endpoints controller 会将 pod ip 记录到 endpoints 对象中,因此,service 的容器发现是通过 endpoints 来实现的。而 kube-proxy 会监听 service 和 endpoints 的更新并调用其代理模块在主机上刷新路由转发规则
Endpoints 是一个由 IP 地址和端口组成的列表,这些 IP 和端口来自于其 Service 关联的 Pod
每个节点上的 kube-proxy 组件 watch 各 Service 及其关联的 Endpoints,如果有变动,就会实时更新当前节点上相应的 iptables 或 ipvs 规则,确保 Cluster IP 的流量能调度到 Endpoints
简单来讲,一个 Service 对象就是一个 Node 上的这些 iptables 和 ipvs 规则
service 的负载均衡
pod 之间通信,一般不会 pod 直接访问 pod,而是 pod 先访问 service,然后 service 再到 pod
关于将 Cluster IP 的流量能调度到 Endpoints,有三种方式:userspace 代理、iptables 代理、ipvs 代理
userspace 代理
1.1 版本之前的默认代理模型,效率低
iptables 代理
通过 iptables 进行目标地址转换和流量调度,缺点是不会在后端 Pod 资源无响应时自动进行重定向
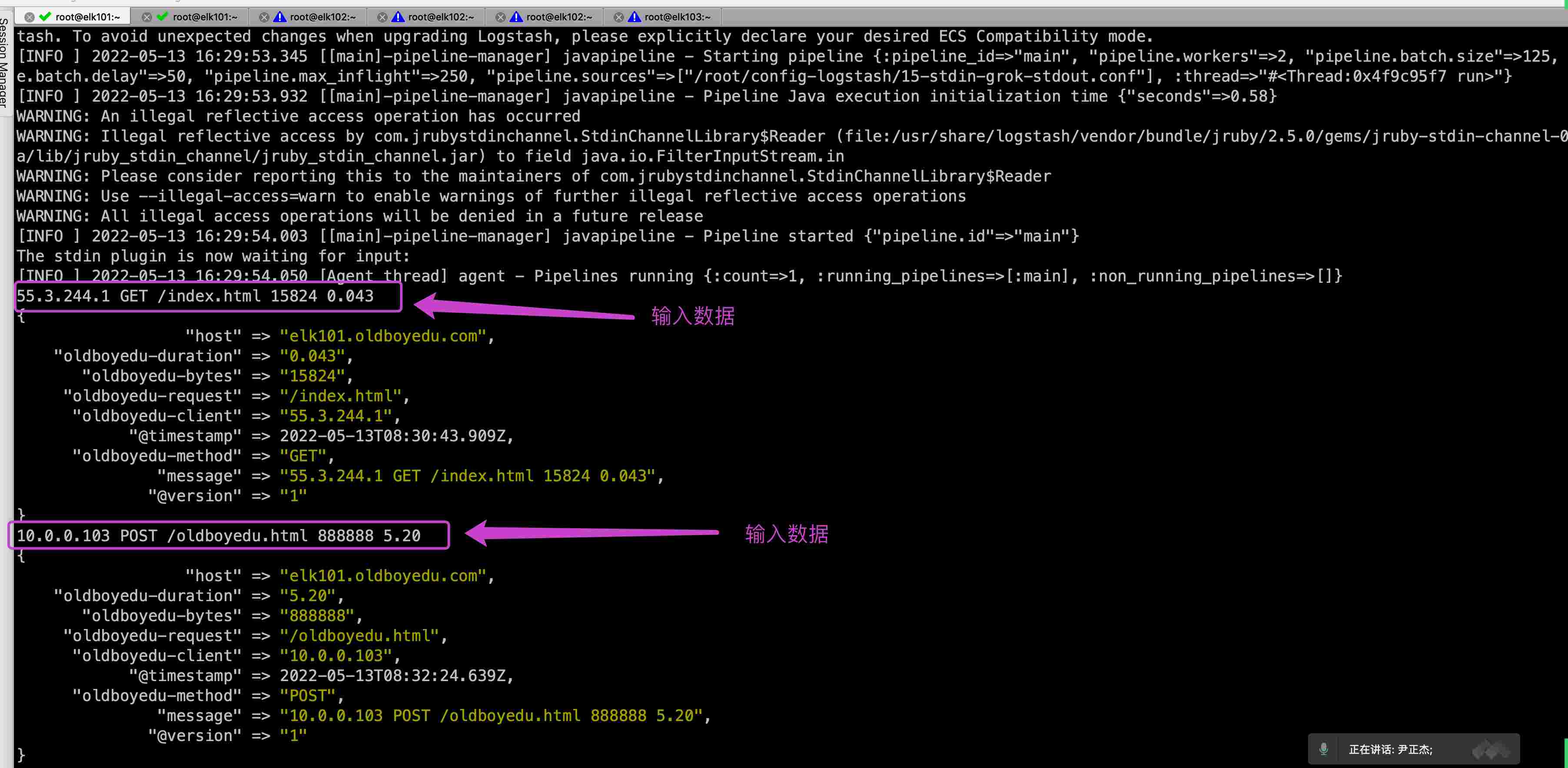
etcdctl put [options] <key> <value> (<value> can also be given from stdin) [flags]
$etcdctl put /testkey "test data" OK
$etcdctl get --print-value-only /testkey test data
删 del
1 2 3 4
etcdctl del [options] <key> [range_end] [flags]
$etcdctl del /testkey 1
改 put
直接覆盖即可
1 2
$etcdctl put /testkey "test data2" OK
查 get
1 2 3 4 5 6 7 8 9 10
etcdctl get [options] <key> [range_end] [flags]
$etcdctl get --print-value-only /testkey test data2
$etcdctl get --prefix --keys-only / # 获取所有key $etcdctl get --prefix --keys-only /calico $etcdctl get --prefix --keys-only /registry $etcdctl get --prefix --keys-only /registry/services $etcdctl get /calico/ipam/v2/handle/ipip-tunnel-addr-k8s-master.ljk.local
The kube-apiserver ability to serve on an insecure port, deprecated since v1.10, has been removed. The insecure address flags --address and --insecure-bind-address have no effect in kube-apiserver and will be removed in v1.24. The insecure port flags --port and --insecure-port may only be set to 0 and will be removed in v1.24. (#95856, @knight42, [SIG API Machinery, Node, Testing])
1 2 3 4 5 6
$kubectl get pods net-test1 -o yaml apiVersion: v1 kind: Pod >metadata: >spec: >status:
以上返回的数据,每个字段表示的意义可以通过 kubectl explain 查询帮助
1
kubectl explain <type>.<fieldName>[.<fieldName>]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
$kubectl explain pod.apiVersion KIND: Pod VERSION: v1
FIELD: apiVersion <string>
DESCRIPTION: APIVersion defines the versioned schema of this representation of an object. Servers should convert recognized schemas to the latest internal value, and may reject unrecognized values. More info: https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#resources
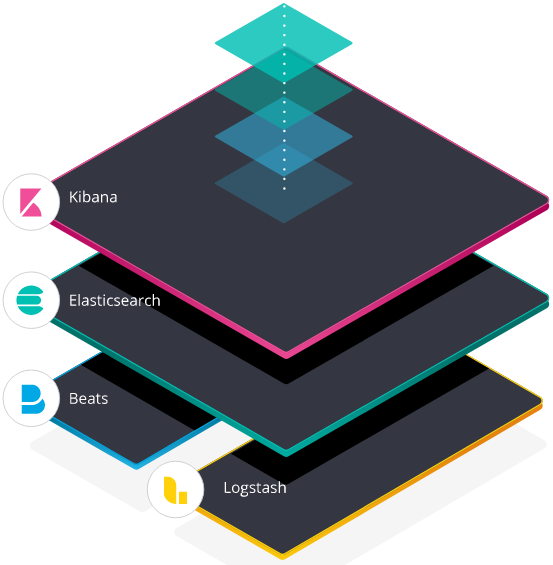
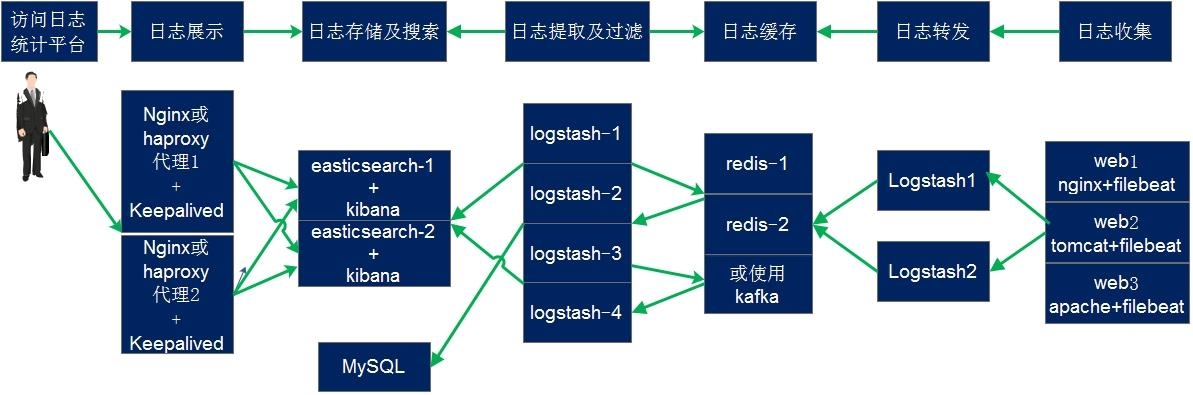
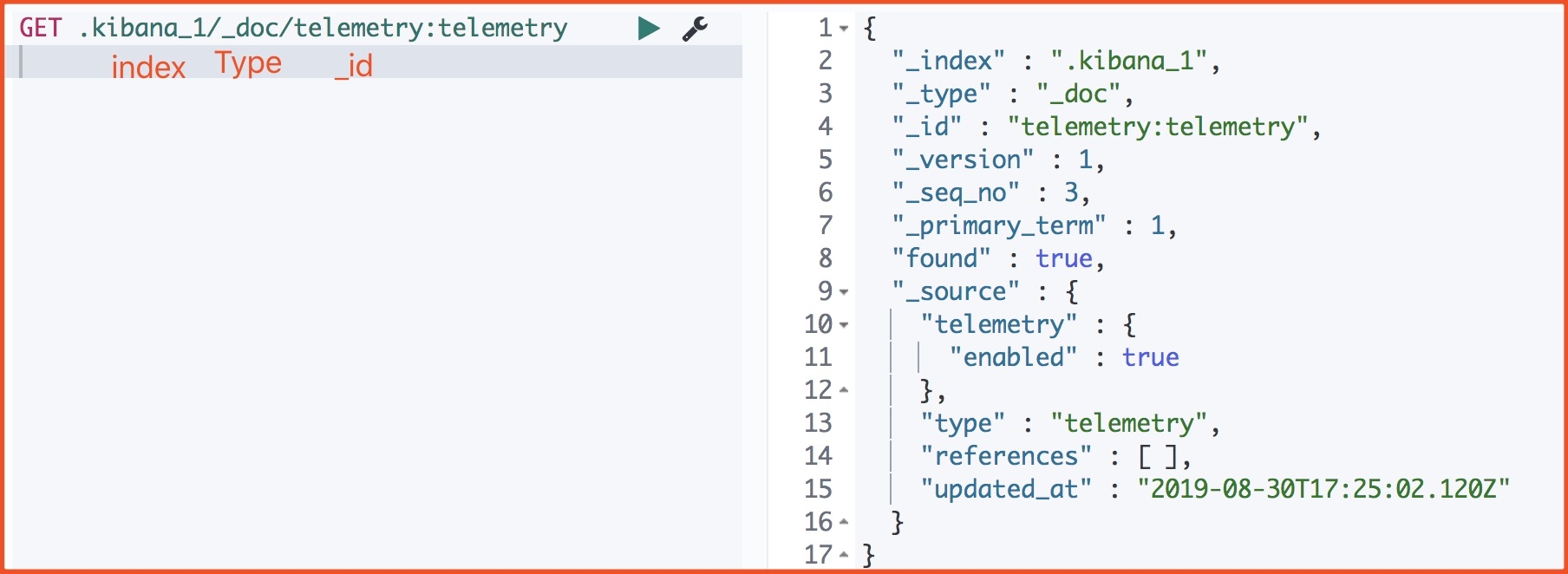
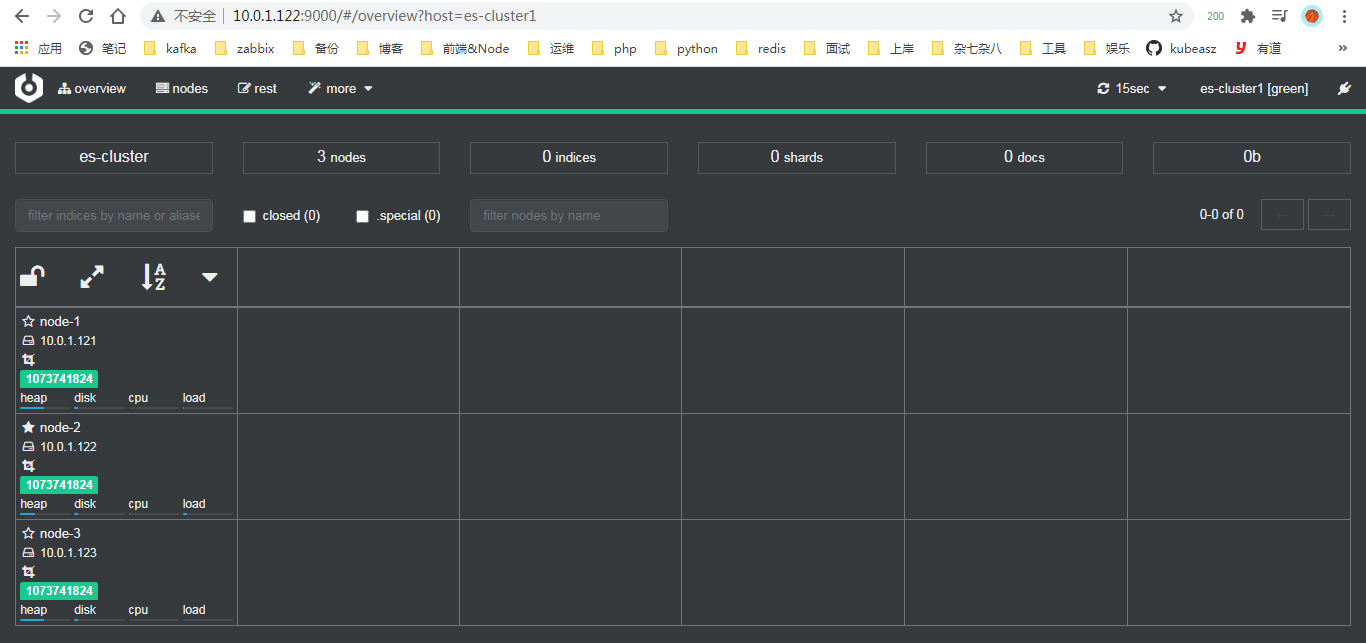
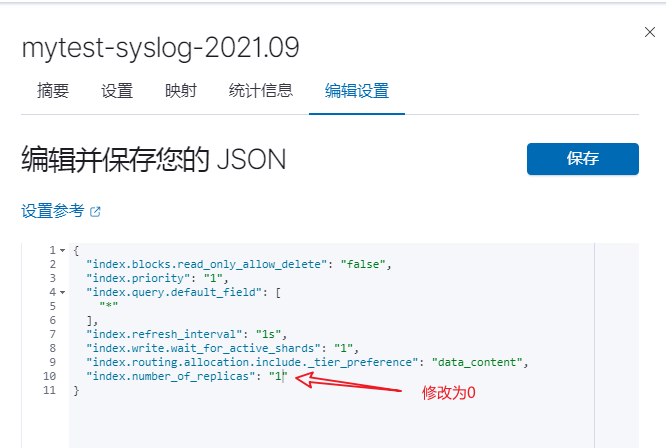
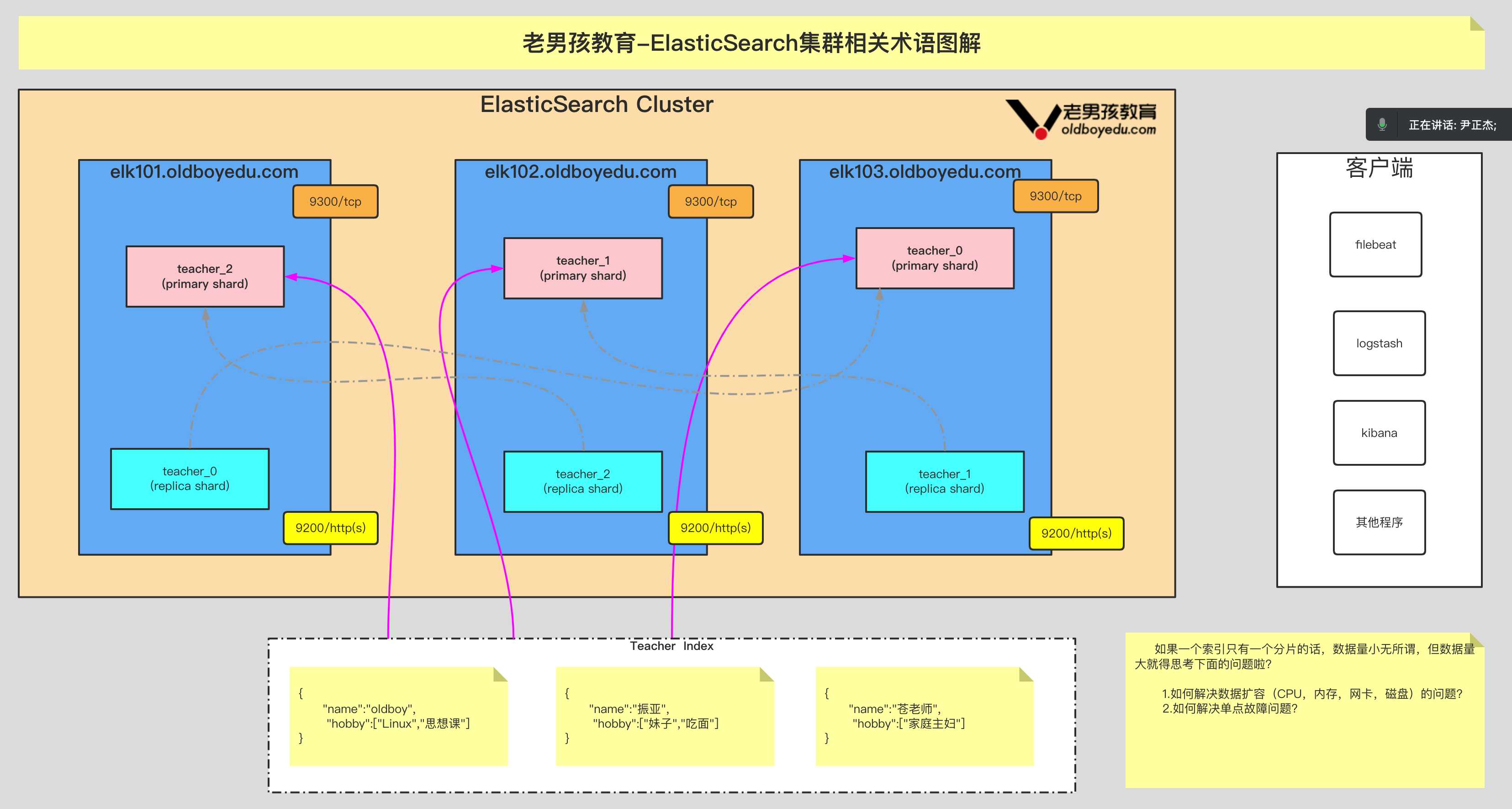
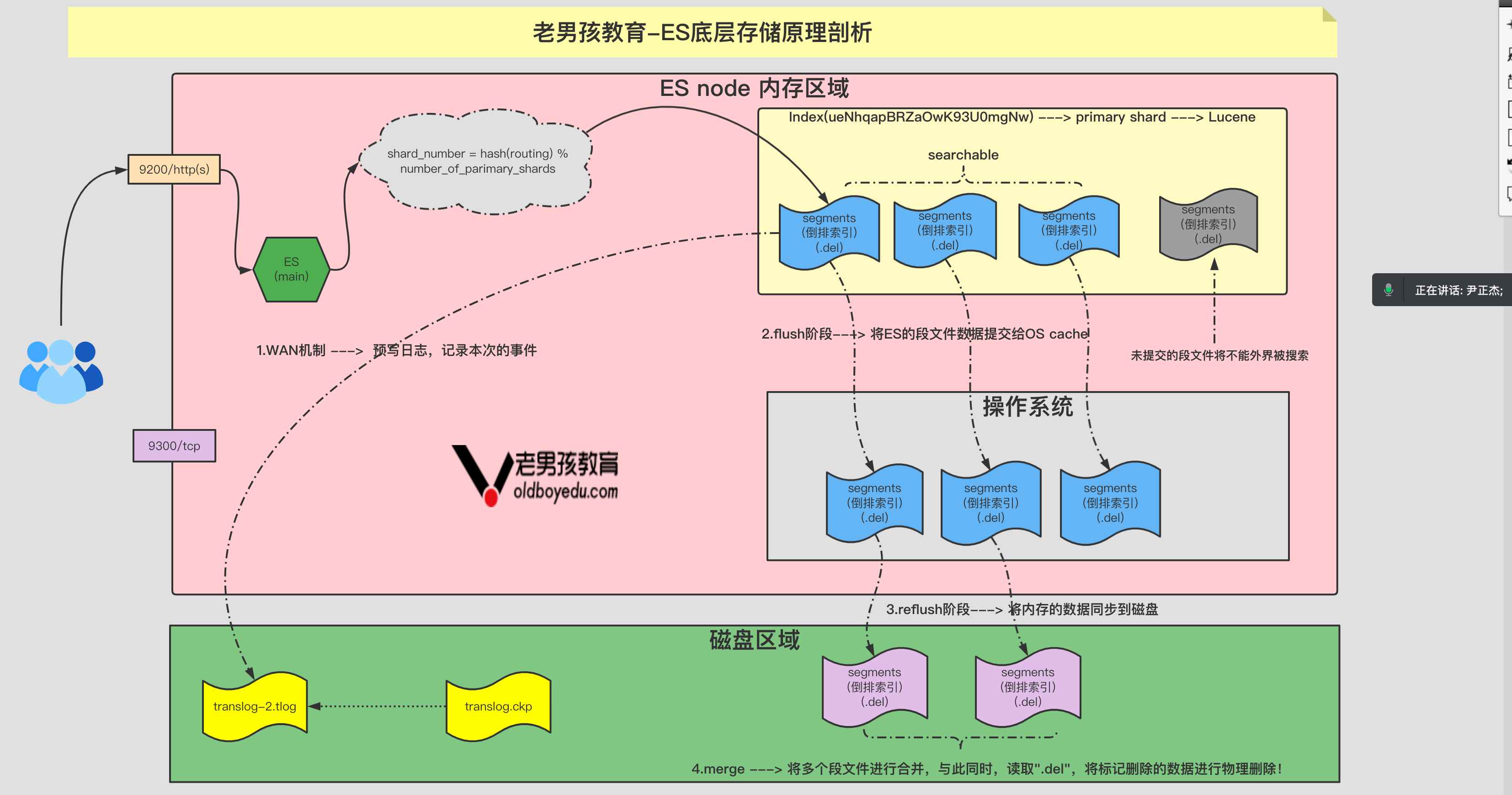
重点理解 index 和 document 这两个概念:index(索引)类似 kafka 的 topic,oss 的 bucket,要尽量控制 index 的数量;index 中的单条数据称为 document(文档),相当于 mysql 表中的行
之前的版本中,索引和文档中间还有个 type(类型)的概念,每个索引下可以建立多个 type,document 存储时需要指定 index 和 type,因为一个 index 中的 type 并不隔离,document 不能重名,所以 type 并没有多少意义。从 7.0 版本开始,一个 index 只能建一个名为_doc 的 type,8.0.0 以后将完全取消
Disable or enable metric logging for this specific plugin instance by default we record all the metrics we can, but you can disable metrics collection for a specific plugin.
Disable or enable metric logging for this specific plugin instance. By default we record all the metrics we can, but you can disable metrics collection for a specific plugin.
The producer will attempt to batch records together into fewer requests whenever multiple records are being sent to the same partition. This helps performance on both the client and the server. This configuration controls the default batch size in bytes.
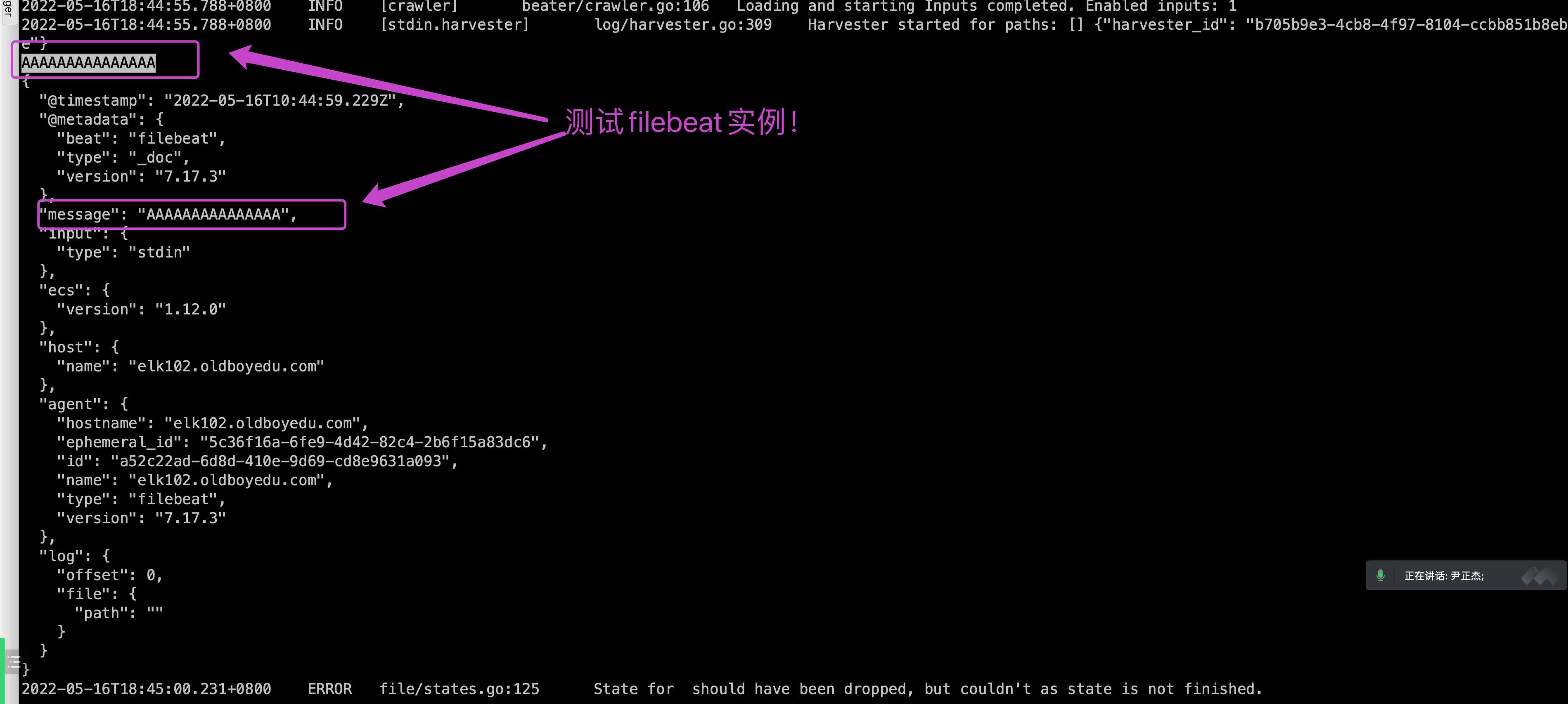
Available Commands: export Export current config or index template generate Generate Filebeat modules, filesets and fields.yml help Help about any command keystore Manage secrets keystore modules Manage configured modules run Run filebeat setup Setup index template, dashboards and ML jobs test Test config version Show current version info
Flags: -E, --E setting=value Configuration overwrite -M, --M setting=value Module configuration overwrite -N, --N Disable actual publishing for testing -c, --c string Configuration file, relative to path.config (default "filebeat.yml") --cpuprofile string Write cpu profile to file -d, --d string Enable certain debug selectors -e, --e Log to stderr and disable syslog/file output --environment environmentVar set environment being ran in (default default) -h, --helphelpfor filebeat --httpprof string Start pprof http server --memprofile string Write memory profile to this file --modules string List of enabled modules (comma separated) --once Run filebeat only once until all harvesters reach EOF --path.config string Configuration path --path.data string Data path --path.home string Home path --path.logs string Logs path --plugin pluginList Load additional plugins --strict.perms Strict permission checking on config files (default true) -v, --v Log at INFO level
Use "filebeat [command] --help"for more information about a command.
Specifies how Filebeat combines matching lines into an event. The settings are after or before. The behavior of these settings depends on what you specify for negate:
Setting for negate
Setting for match
Result
Example pattern: ^b
false
after
Consecutive lines that match the pattern are appended to the previous line that doesn’t match.
false
before
Consecutive lines that match the pattern are prepended to the next line that doesn’t match.
true
after
Consecutive lines that don’t match the pattern are appended to the previous line that does match.
true
before
Consecutive lines that don’t match the pattern are prepended to the next line that does match.
The after setting is equivalent to previous in Logstash, and before is equivalent to next.
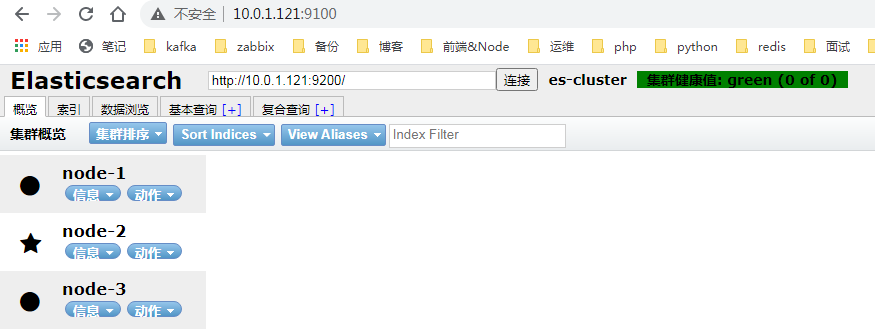
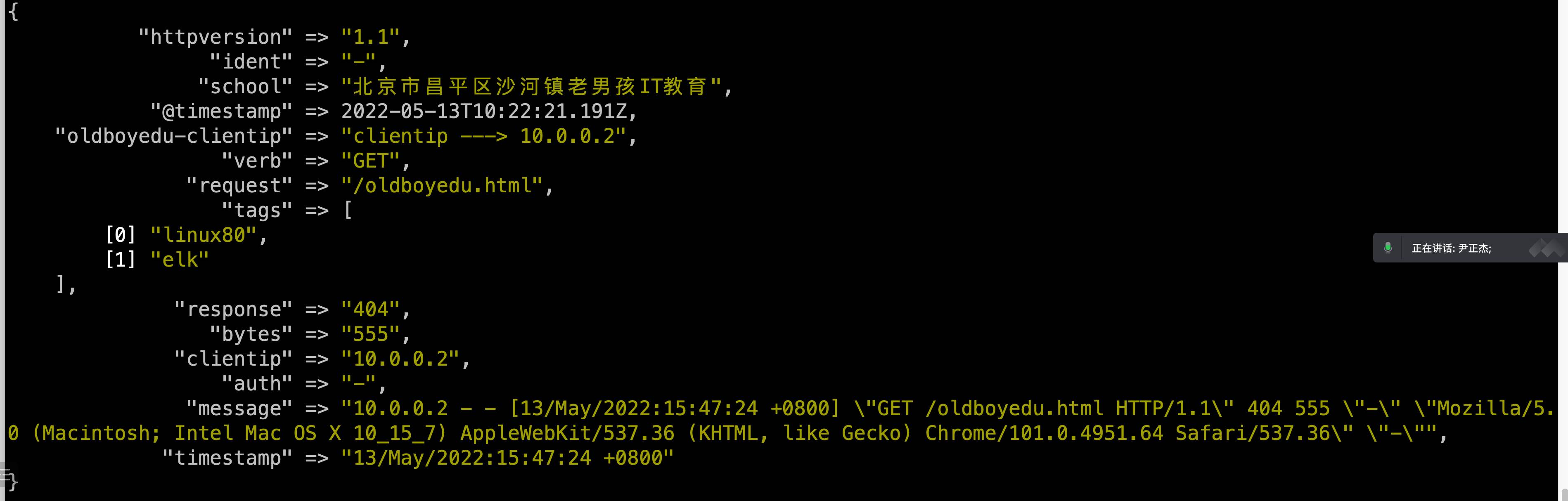
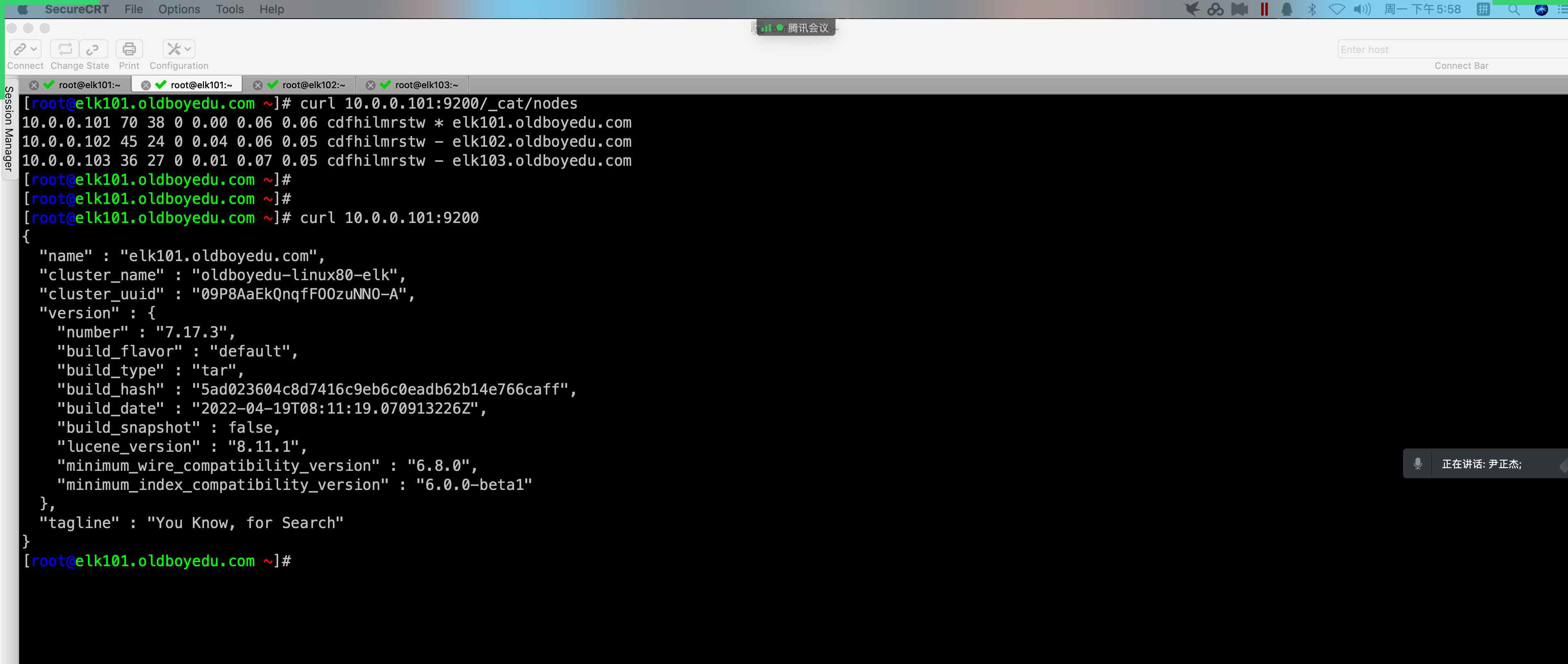
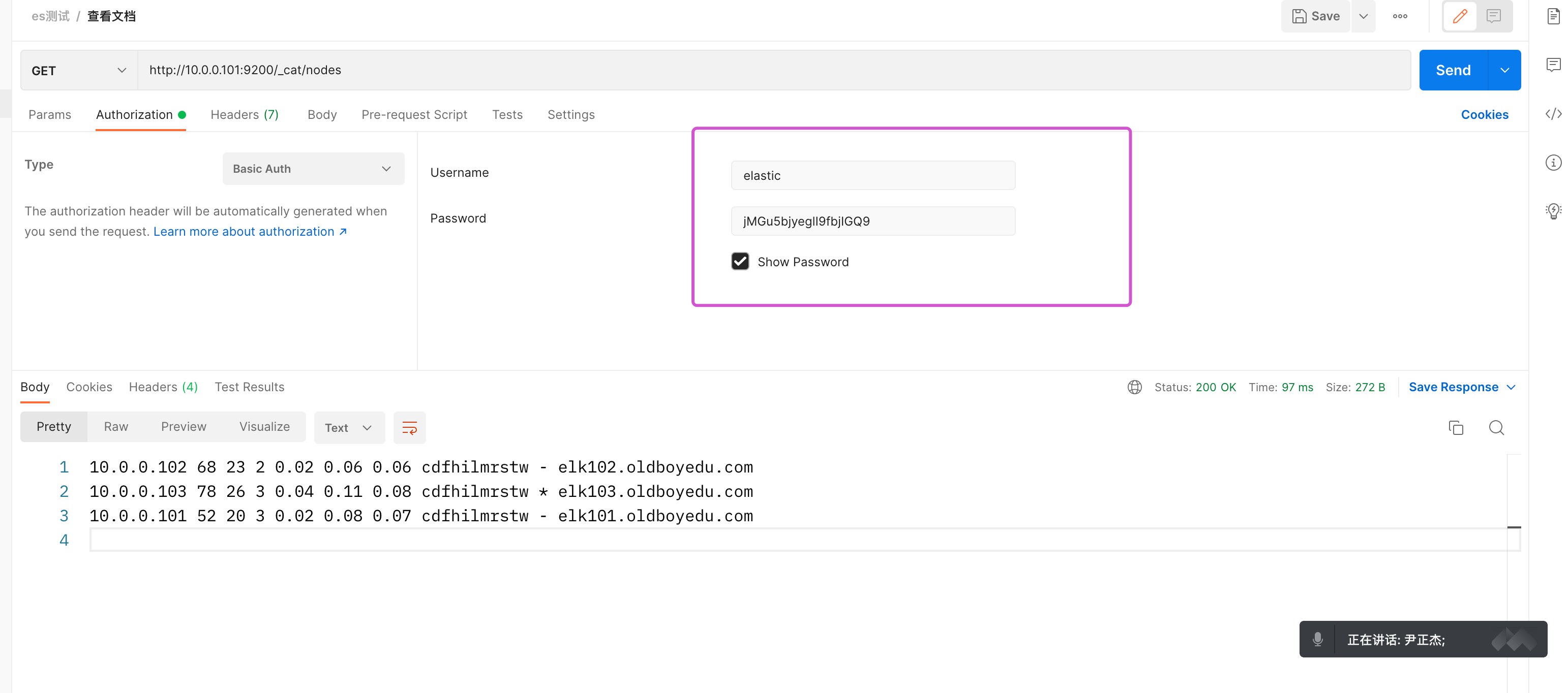
GET http://10.0.0.101:9200/_cat/indices # 查看全部的索引信息 GET http://10.0.0.101:9200/_cat/indices?v # 查看表头信息 GET http://10.0.0.101:9200/_cat/indices/.kibana_7.17.3_001?v # 查看单个索引 GET http://10.0.0.101:9200/.kibana_7.17.3_001 # 查看单个索引的详细信息
GET http://10.0.0.101:9200/teacher/_search # 查看所有的⽂档 GET http://10.0.0.101:9200/teacher/_doc/4FHB0IABf2fC857QLdH6 # 查看某⼀个⽂档 HEAD http://10.0.0.101:9200/teacher/_doc/4FHB0IABf2fC857QLdH6 # 判断某⼀个⽂档是否存在,返回200,404.
# (2)验证置⾃定义分词器是否⽣效 GET http://10.0.0.101:9200/oldboyedu_linux80_2022/_analyze { "text":"If you are a PERSON, Please be kind to small Animals.", "analyzer":"my_analyzer" }
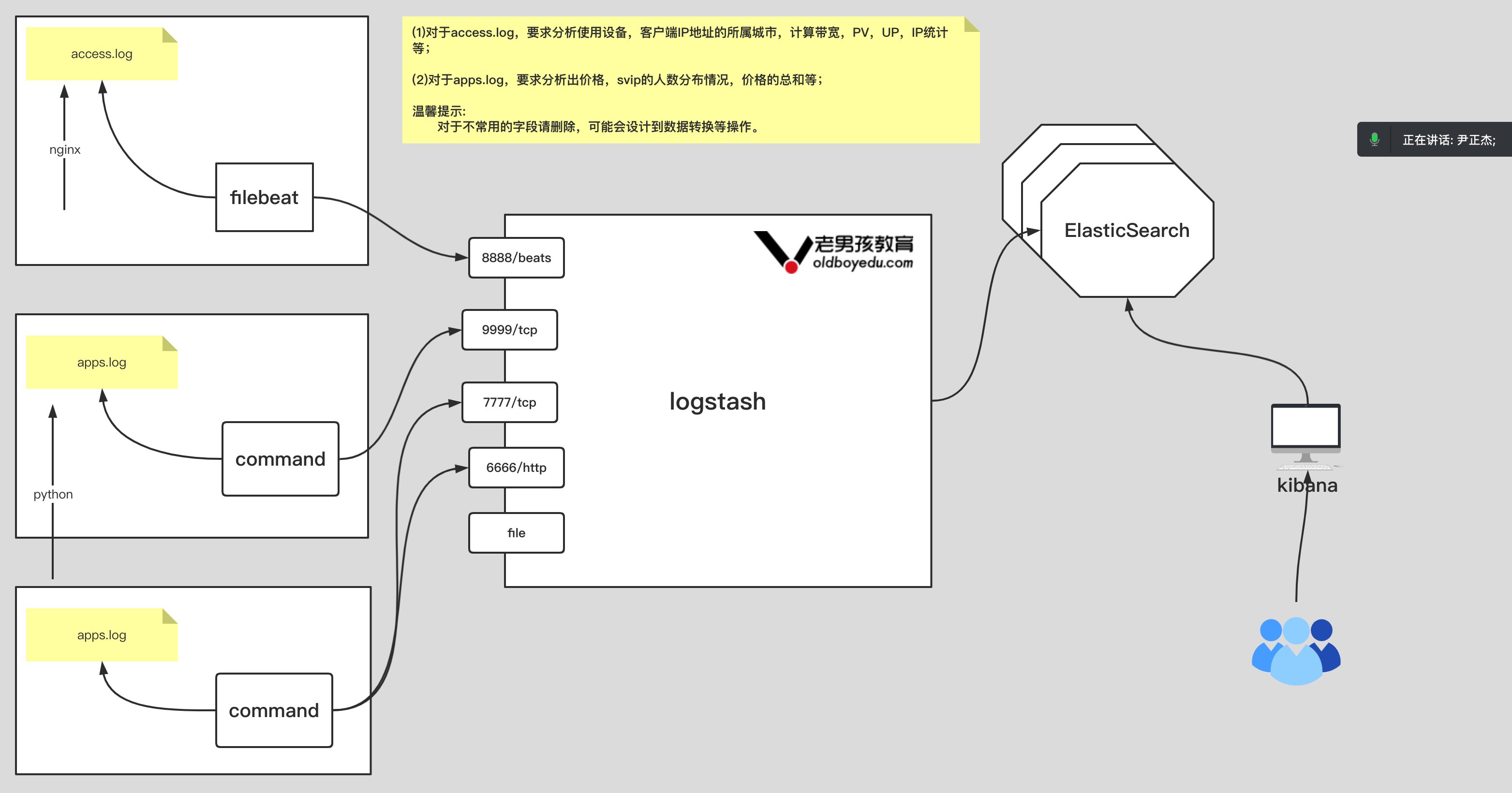
[root@gitlab ~]$gitlab-rake gitlab:backup:create ... Warning: Your gitlab.rb and gitlab-secrets.json files contain sensitive data and are not included in this backup. You will need these files to restore a backup. Please back them up manually.