数组_zend_array
zend_array 和 HashTable 都是 _zend_array 结构体的别名。
1 | 185 struct _zend_array { |
1 | typedef struct _Bucket { |
数组初始化:
数组添加数据:
数组删除数据:
数组获取数据:
zend_array 和 HashTable 都是 _zend_array 结构体的别名。
1 | 185 struct _zend_array { |
1 | typedef struct _Bucket { |
数组初始化:
数组添加数据:
数组删除数据:
数组获取数据:
数组初始化$arr = [1,2,3];,打印 gc 发现 refcount=2;
数组初始化$arr = ['time'=>time()];, 打印 gc 发现 refcount=1;
这是为什么呢?
这牵扯到 PHP7 中的另一个概念,叫做 immutable array (不可变数组),在不可变数组下,使用一个伪计数值 2。类型是这种直接申明规定数组
摘抄一段 PHP7 数组开发成员的一段原话:
For arrays the not-refcounted variant is called an “immutable array”. If you use opcache, then constant array literals in your code will be converted into immutable arrays. Once again, these live in shared memory and as such must not use refcounting. Immutable arrays have a dummy refcount of 2, as it allows us to optimize certain separation paths.
写时复制:
1 | $a = 'this is string'; |
此时,$a和$b 在内存中指向同一地址, 当修改$a或者$b 的时候, 才会复制一份, 然后对复制的这份进行修改
1 | 146 typedef struct _zend_refcounted_h { |
1 |
|
4、5 行输出$a和$b 都是引用类型,$b引用$a,但是$a也会变成引用类型 zend_reference,$a 和$b 的 zval 都指向同一个 zend_reference。zend_reference 中的 zval 中的 u1.type=6,表示字符串类型, p *z.value.ref.val.value.str.val@6 string
8、9 行$a和$b 指向的 zend_reference 中的 zval 类型还是字符串,但是打印出来已经都是 helle!了
12 行 $b 指向的 zval 显示类型是 0,也就是 IS_UNDEF
13 行 $a 的 zval 的 type 依然是 10(引用类型), 打印仍然是 hello!
可以看出, 11 行 unset($b)的操作,仅仅是把$b 的 zval 中的 type 由 10 改成 0, 其他的完全不动。
zval 是一个结构体,其中包含三个联合体(共同体):value、u1、u2;vaule8 字节,u1 和 u2 都是 4 个字节,正好 8 字节对其,所以 zval 的大小是 16 字节。
zval 用 16 字节可以表示 PHP 中的任意一个变量。
如何表示的呢?
line84 typedef struct _zval_struct zval; 为_zval_struct 这个结构体定义别名为 zval, ctrl + ] 跳转到 line121 查看_zval_struct:
1 | struct _zval_struct { |
然后定位 zend_value, ctrl+]跳转:
1 | typedef union _zend_value { |
接下来我们详细说明一下 zval 的结构: 显然, 它是一个结构体,包含三个值, 其类型都是联合体。
先看 value 的这个联合体 zend_value, 包含 14 个值, 经过 tags 的 ctrl+]跳转,我们发现:
zend_long 是 int64_t 的别名, 而 int64_t 又是__int64 的别名(关于__int64 可以查看笔记: 备忘/bit B(byte) KB.md)。
zend_refcounted 是_zend_refcounted 的别名,而_zend_refcounted 是一个结构体,其中只有一个值 gc,gc 是 zend_refcounted_h 类型的数据,而 zend_refcounted_h 是一个结构体:
1 | typedef struct _zend_refcounted_h { |
uint32_t 是 unsigned int 的别名。refcount 表示。。。,u 这个联合体中包含一个结构体 v 和一个 32 位正整型 type_info。
zend_uchar 是 unsigned char 的别名。
。。。未完待续
str 是指针,zend_string 是_zend_string 的别名
1 | struct _zend_string { |
gc 和垃圾回收有关。zend_ulong 是 uint32_t 的别名,表示 hash 值,防止冲突。
关于 size_t:
size_t 是一些 C/C++标准在 stddef.h 中定义的。这个类型足以用来表示对象的大小。size_t 的真实类型与操作系统有关。
在 32 位架构中被普遍定义为:typedef unsigned int size_t;
而在 64 位架构中被定义为:typedef unsigned long size_t;
为什么有时候不用 int,而是用 size_type 或者 size_t: 与 int 固定四个字节不同有所不同,size_t 的取值 range 是目标平台下最大可能的数组尺寸,一些平台下 size_t 的范围小于 int 的正数范围,又或者大于 unsigned int. 使用 Int 既有可能浪费,又有可能范围不够大。
len 用来储存字符串的长度。
val 是一个柔性数组,用来储存字符串。
arr 是指针,zend_array 是_zend_array 的别名
1 | struct _zend_array { |
gc 与垃圾回收有关。
联合体 v。。。
。。。未完待续
obj 是指针,zend_object 是_zend_object 的别名
1 | struct _zend_object { |
。。。未完待续
res 是指针,zend_resource 是_zend_resource 的别名
1 | struct _zend_resource { |
。。。未完待续
ref 是指针,zend_reference 是_zend_reference 的别名
1 | struct _zend_reference { |
。。。未完待续
ast 是指针,zend_ast_ref 是_zend_ast_ref 的别名
1 | struct _zend_ast_ref { |
zend_ast 是_zend_ast 的别名
1 | typedef uint16_t zend_ast_kind; |
。。。未完待续
zv 是指针
。。。未完待续
ptr 是指针
。。。未完待续
ce 是指针,zend_class_entry 是_zend_class_entry 的别名
1 | struct _zend_class_entry { |
。。。未完待续
func 是指针
1 | union _zend_function { |
。。。未完待续
ww 结构体
综上可以看出,value 中存储的是变量内容,接下来我们看两个联合体 u1 和 u2。
1 | union { |
u1 中有一个结构体 v 和一个 32 位整型 type_info,这个 type_info 的作用就是获取 v 的值。这么写是一个小技巧。
zend_uchar 是 unsigned char 的别名,type 这个值表示不同的变量类型,有:
#define IS_UNDEF 0
#define IS_NULL 1
#define IS_FALSE 2
#define IS_TRUE 3
#define IS_LONG 4
#define IS_DOUBLE 5
#define IS_STRING 6
#define IS_ARRAY 7
#define IS_OBJECT 8
#define IS_RESOURCE 9
#define IS_REFERENCE 10
以上,整型就是 IS_LONG。
。。。未完待续
1 | union { |
u2 中的 next 用来解决数组中的冲突。
通过内存管理申请一个内存地址,这个内存地址属于 small 或 large 或 huge 内存,那如何判断呢?
page 4KB
chunk 2MB
small 小于等于 3KB 的内存。
large 大于 3KB 且小于等于(2MB-4KB)的内存,可以对应整数倍的 page。
huge 大于 2MB-4KB 的内存,可以对应整数倍的 chunk。
如果是 0x8 打头,
如果是 0xc 打头的,看两段
0x4 打头的是 large 内存。
如果一个内存是 2M 的整数倍,一定是 huge 内存。
2MB=2×1024*1024=2×2^10×2^10=2×2^20
16=2^4
(2×2^20) / 2^4
最终得到 2MB 的 16 进制是 200000
所以看到 0x…00000 这种后面是 5 个 0 的,然后看一看倒数第六位能否被 2 整除,就一定是 huge 内存。
例如:0x7ffff5e00000,它属于 huge 内存。
如果一个内存地址不是 2MB 的整数倍,那我们根据地址,去掉偏移,找到一个 chunk,另外我们也可以知道,它属于哪个 page(偏移除以 4K)。
malloc 函数申请内存, 返回指针;
free 释放内存
1 | void * ptr = malloc(size); |
问题: 申请内存的时候需要传入 size, 为什么 free 的时候没有传入 size, 那么是怎么做到准确释放 size 大小的内存的呢?
其实呢, malloc 在分配内存的时候, 返回的地址的指针指向了程序可用内存的位置, 在 ptr 前面会多分配 32 位的头部, 头部的低三位表示是否分配。
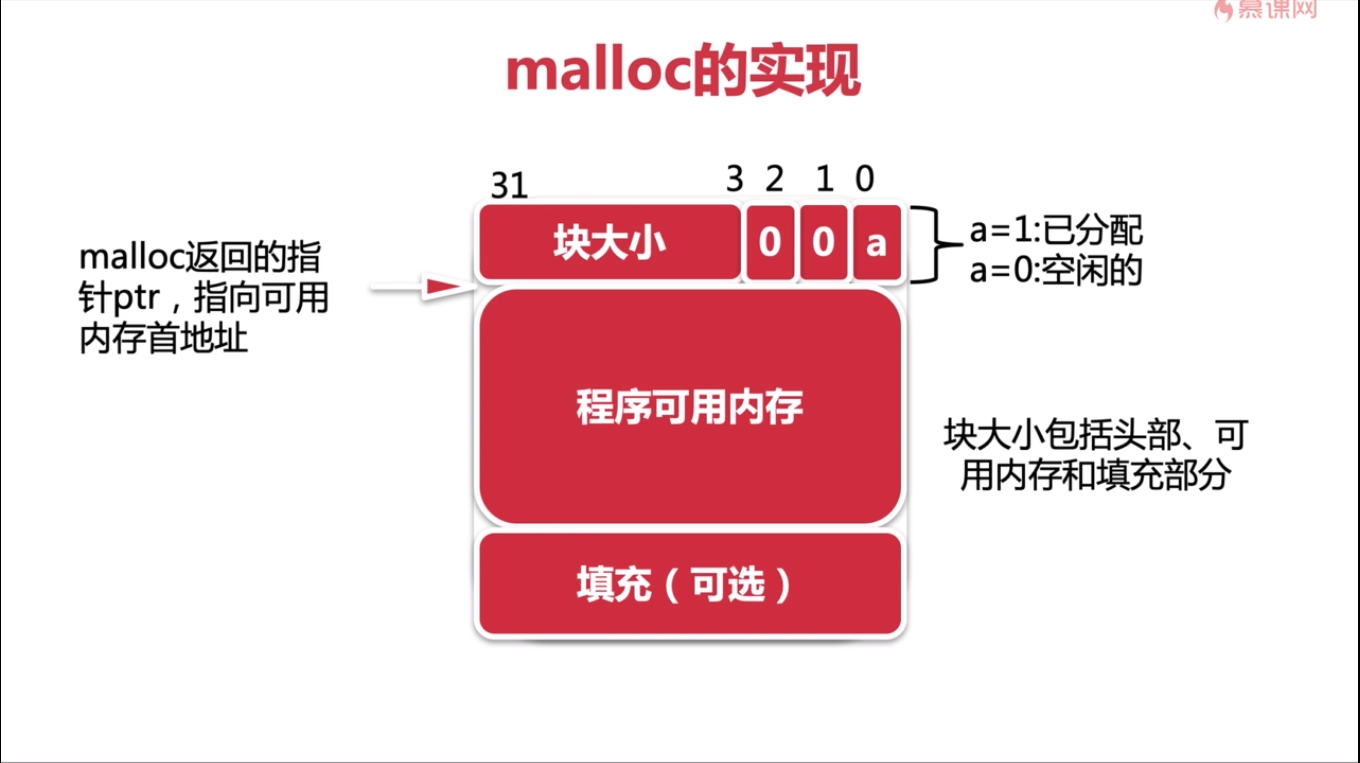
当 free 的时候,会向前搜寻 32 的头,取高 29 位为块的大小,所以 free 的时候就不需要传递 size 了,当然这只是一种 malloc 的实现,当前的 linux 的 malloc 事件已经不是这样了,但原理是一样的,也是维护了一个头部。
chunk:2MB 大小的内存;
page:4KB 大小的内存;
一个 chunk 可以分成 512 个 page。
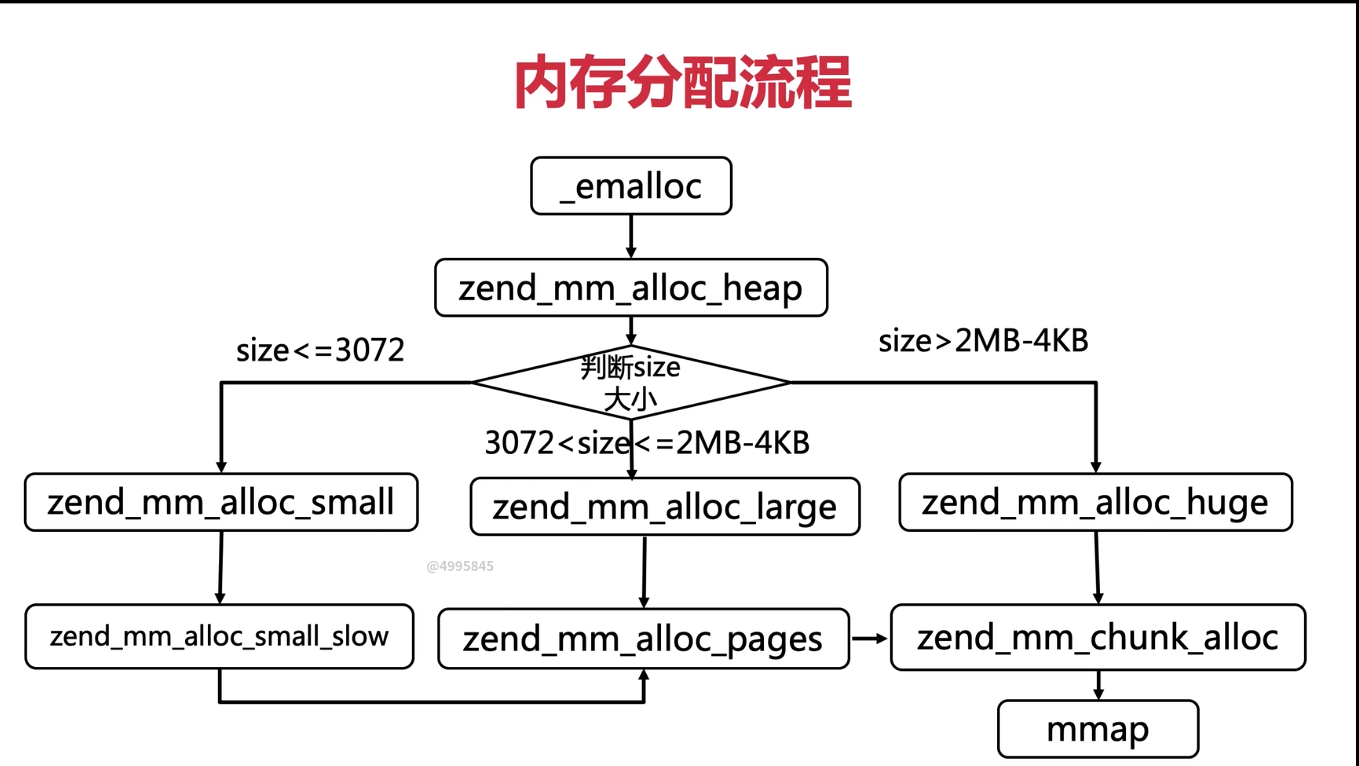
zend_mm_alloc_heap 判断申请内存的大小;
申请内存大于 2M-4K, 则属于 huge, 执行 zend_mm_alloc_huge, 调用 zend_mm_chunk_alloc, 最终调用 mmap 取申请大内存;
申请内存大于 3K 且小于 2M-4K, 则属于 large, 执行 zend_mm_alloc_large, 调用 zend_mm_alloc_pages
申请内存小于等于 3K, 则属于 small, 执行 zend_mm_alloc_small 函数, 如果当前有 small 内存, 则直接返回, 如果没有, 则执行 zend_mm_alloc_small_slow, 需要先去 zend_mm_alloc_pages 看看, 如果 large 也没有余量了, 就去 zend_mm_chunk_alloc 开辟新的内存。
4k 对其:申请的内存只能是 4K 的整数倍;
内存对其的好处,当已知一个内存地址,就可以算出此内存(page)的起始地址;例如有一内存地址 0x103c61120,4k 对齐,通过宏计算,此内存所在 page 的起始地址为 0x103c61000,在此 page 的偏移量是 0x120,能过快速定位内存地址所在的 page,提高效率。
内存管理的代码比较多,但是我们只需要掌握两个核心:当我们 free 的时候,不需要传递 size,
参考链接:https://www.cnblogs.com/wuyuegb2312/archive/2013/06/08/3126510.html
大端 => 高尾端
小端 => 低尾端
计算机系统中,以字节为单位,每个地址单元都对应这一个字节,一个字节为 8bit。
大端:(Big-Endian):就是把数值的高位字节放在内存的低位地址上,把数值的低位字节放在内存的高位地址上。
小端:(Little-Endian):就是把数值的高位字节放在高位的地址上,低位字节放在低位地址上。
1 |
|
输出:0x7fff86f78684
【注】不管是大端法还是小端法存储,计算机在内存中存放数据的顺序都是从低地址到高地址。
小端规则
| 地址 | 0x7fff86f78684 | 0x7fff86f78685 | 0x7fff86f78686 | 0x7fff86f78687 |
|---|---|---|---|---|
| 数值 | 0x78 | 0x56 | 0x34 | 0x12 |
大端规则
| 地址 | 0x7fff86f78684 | 0x7fff86f78685 | 0x7fff86f78686 | 0x7fff86f78687 |
|---|---|---|---|---|
| 数值 | 0x12 | 0x34 | 0x56 | 0x78 |
通过上面的表格,可以看出来大小端的不同。(注:其实在计算机内存中并不存在所谓的数据类型,比如 char,int 等的。这个类型在代码中的作用就是让编译器知道每次应该从那个地址起始读取多少位的数据,赋值给相应的变量。)
1 |
以# define ZEND_ENDIAN_LOHI_4(a, b, c, d) d; c; b; a;为例,这里涉及到一个大小端的问题:
正向代理和反向代理的本质区别是是什么?
https://www.zhihu.com/question/36412304
正向代理:客户机必须指定代理服务器,并将本来要直接发送到 Web 服务器上的 http 请求发送到代理服务器中
反向代理:代理服务器接受 Internet 上的连接请求,然后将请求转发给内部网络的服务器;并将从服务器上得到的结果返回给 Internet 上请求连接的客户端,此时代理服务器对外就表现为一个服务器
正向代理对客户端负责,反向代理对其代理的服务器负责,搭梯子就是典型的正向代理,而 LVS、haproxy、nginx 等都是反向代理
我数据库版本为 5.7.16
新建表结构:
1 | DROP TABLE IF EXISTS `yx_test`; |
报错信息:ERROR 1067 (42000): Invalid default value for 'deleted_at'
解决方案:
使用 root 登陆数据库
1 | select @@sql_mode; |
获得结果:
ONLY_FULL_GROUP_BY,STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION
NO_ZERO_IN_DATE, NO_ZERO_DATE 是无法默认为‘0000-00-00 00:00:00’的根源,去掉之后再次新建表就可以了
1 | SET GLOBAL sql_mode='ONLY_FULL_GROUP_BY,STRICT_TRANS_TABLES,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION'; |
注:
NO_ZERO_IN_DATE:在严格模式下,不允许日期和月份为零
NO_ZERO_DATE:设置该值,mysql 数据库不允许插入零日期,插入零日期会抛出错误而不是警告。
测试新建表,ok
分区
/boot 300MB 逻辑分区
/ 自动补全 主分区
其他的不用设置
更新
不要勾选更新,等安装完系统,更新源之后再更新比较快
装完系统后第一件事就是更新国内源
将 apt 的源更换为国内的源,我选择的是阿里云
https://developer.aliyun.com/mirror/ubuntu?spm=a2c6h.13651102.0.0.3e221b11OyziSW
让更新后的源生效
1 | sudo apt-get update // 更新软件列表 |
可以通过 ubuntu 软件 搜索安装,或者
1 | sudo apt install gnome-tweaks |
https://www.wps.cn/product/wpslinux/
下载.dep 包,然后双击安装即可
下载.dep 包,然后双击安装即可
https://code.visualstudio.com/
下载.dep 包,然后双击安装即可
1 | # or run: |
https://www.sublimetext.com/docs/3/linux_repositories.html
1 | wget -qO - https://download.sublimetext.com/sublimehq-pub.gpg | sudo apt-key add - |
https://www.jetbrains.com/phpstorm/download/#section=linux
两种安装方式:
1 | sudo snap install phpstorm --classic |
或者直接下载 .tar.gz 包,然后将解压后的目录移动到 /opt 下,再执行 phpstorm.sh 即可
1 | tar -zxvf PhpStorm-2019.2.3.tar.gz |
激活码:百度搜一个
删除: 删除 /opt/PhpStorm 和 ~/.PhpStorm2019.2 即可
重装:删除~/.PhpStorm2019.2 然后重新执行 phpstorm.sh 即可
两种安装方式:
1 | sudo snap install pycharm-professional --classic |
或者
或者直接下载 .tar.gz 包,然后将解压后的目录移动到 /opt 下,再执行 pycharm.sh 即可
1 | tar -zxvf pycharm-professional-2019.2.3.tar.gz |
激活码:百度搜一个
删除: 删除 /opt/pycharm 和 ~/.PyCharm2019.2 即可
重装:删除~/.PyCharm2019.2 然后重新执行 pycharm.sh 即可
奇怪的是,pycharm 不会自己生成快捷方式,所以需要自己手动添加
1 | cd /usr/share/applications/ |
将以下代码添加到 PyCharm.desktop
1 | [Desktop Entry] |
https://www.vandyke.com/cgi-bin/releases.php?product=securecrt
下载之前需要先注册,这个有点麻烦
两种安装方式,.dep 或者.tar.gz,这里选择 .tar.gz,将下载的 scrt-8.5.4.1942.ubuntu18-64.tar.gz 解压到/opt 下
1 | tar -zxvf scrt-8.5.4.1942.ubuntu18-64.tar.gz |
添加快捷方式到启动器
1 | sudo mv /opt/scrt-8.5.4/SecureCRT.desktop /usr/share/applications/ |
安装完毕
如果采用双击.dep 安装包的方式,安装完成后,双击 SecureCTR 图标, 打不开也不报错
1 | lujinkai@lujinkai-TM1703:/usr/lib/x86_64-linux-gnu$ whereis SecureCRT |
回车执行:
1 | /usr/bin/SecureCRT |
报错: error while loading shared libraries: libpython2.7.so.1.0: cannot open shared object file: No such file or directory
检测:
1 | locate libpython2.7.so.1.0 |
显示正常: /usr/lib/x86_64-linux-gnu/libpython2.7.so.1.0
奇怪, 但是查找不到这文件
所以直接安装这个库:
1 | sudo apt-get install libpython2.7-dev |
问题解决
https://pinyin.sogou.com/linux/?r=pinyin
因为搜狗输入法依赖 fcitx,所以要先安装 fcitx
1 | sudo apt install fcitx |
下载搜狗输入法,使用 dpkg 安装
1 | sudo dpkg -i sogoupinyin_2.2.0.0108_amd64.deb |
报错,解决依赖关系
1 | sudo apt --fix-broken install |
启动器打开 输入法,配置为 fcitx。
设置 -> 区域和语言 -> 输入源:删除多余语言,只保留一个 汉语-> 管理已安装的语言 -> 添加或删除语言… :只安装一个 中文简体
重启
注:搜狗输入法目前支持 ubuntu18.04,在 ubuntu20.04 上推荐使用谷歌输入法
https://music.163.com/#/download
下载全部客户端,选择 Linux 版,双击下载的.dep 安装包即可
https://pan.baidu.com/download
下载.dep 包,然后双击安装即可
软件中心搜索 “Remmina”
软件中心搜索 “Rhythmbox”
这个有点麻烦,没有可视化客户端,只能用命令行了
1 | sudo apt-get install subversion |
先略过。。。
1 | sudo apt install nfs-common |
这个有点麻烦,暂时略过,用坚果云代替先
https://www.jianguoyun.com/s/downloads
下载 Linux 版,双击.dep 安装包即可
1 | sudo vim /etc/ssh/ssh_config // 修改配置文件 |
修改&&添加
1 | GSSAPIAuthentication no // 默认yes,修改为no |
重启
1 | service ssh restart |
如果无法重启,则安装openssh-server后再重启
1 | sudo apt-get install openssh-server |
因为 phpMyAdimin 默认只能访问本地数据库,但是我们的需求是可以连接远程服务器的数据库。
打开/phpmyadmin/libraries 目录,
修改 config.default.php 文件
1 | $cfg['AllowArbitraryServer'] = false; 修改成:$cfg['AllowArbitraryServer'] = true; |
然后把 phpMyAdmin 目录移动到/data/wwwroot 下,单独给它配置访问域名,因为如果通过二级目录去访问,有时候会报如下的错误:
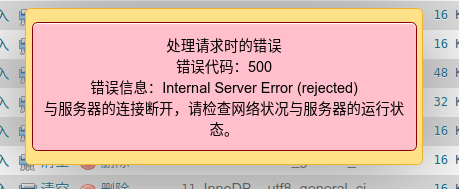
https://www.getpostman.com/downloads/
解压,进入解压后的目录,直接执行 Postman 即可
但是没有桌面图标,这个我就不添加图标了,只在 /ust/local/bin 目录下添加一个软链接指向 /opt/Postman/Postman
未完待续。。。
安装为双系统后,默认为 ubuntu 启动
现在将其设为,默认启动上次选择启动的系统(让 grub 记住上次启动时选择的系统):
1 | sudo vim /etc/default/grub |
GRUB_DEFAULT=0(0 为 ubuntu 启动)改为 GRUB_DEFAULT=saved
文件末尾添加 GRUB_SAVEDEFAULT=true(这行命令可以修复只修改“grub_deault=saved”,但是启动时依然不能记住上次的启动的 GRUB2 的 bug)
保存退出
终端更新配置文件:sudo update-grub
sudo reboot 重启
注:
GRUB_TIMEOUT=10 可调整自动进入时间
要固定默认启动系统,只需调整 GRUB_DEFAULT=0 为 windows10 所在序号(ubuntu 为 0 以此类推),然后更新配置文件
附/etc/default/grub 配置文件详解:
1 | # 设定默认启动项,推荐使用数字 |
参考资料:
cmake 的构建模式
1 | CMAKE_BUILD_TYPE=Debug | Release | RelWithDebInfo | MinSizeRel |
mysql 的安装目录
1 | CMAKE_INSTALL_PREFIX = /usr/local/mysql |
是否为社区版本
1 | COMMUNITY_BUILD = ON |
是否从下载开源 boost
1 | DOWNLOAD_BOOST = 1 |
This CMake script will look for boost in
1 | DWITH_BOOST = <directory> |
下载 boost 的超时时间, 单位 秒
1 | DOWNLOAD_BOOST_TIMEOUT = 600 |
是否启用查询分析代码 参考
1 | ENABLED_PROFILING = ON |
是否包括 gcov 支持, 不太懂这是什么, 默认关闭.
1 | ENABLE_GCOV = OFF |
启用 gprof, (仅优化 Linux 版本), 不太懂, 默认关闭
1 | ENABLE_GPROF = OFF |
不太懂, 默认关闭
1 | ENABLE_MEMCACHED_SASL = OFF |
不太懂, 看起来和上面一起是配套的, 也默认关闭
1 | ENABLE_MEMCACHED_SASL_PWDB:BOOL=OFF |
这也不太懂, 默认就好了, 它的注释说这个选项好像已经被弃用了
1 | FEATURE_SET=community |
选择预定义的安装布局, STANDALONE
STANDALONE:与用于.tar.gz和.zip 包的布局相同 。这是默认值。RPM:布局类似于 RPM 包SVR4:Solaris 包布局DEB:DEB 封装布局(实验)1 | INSTALL_LAYOUT = STANDALONE |
默认的 mysql 数据目录
1 | MYSQL_DATADIR = /usr/local/mysql/data |
默认的 mysql 手册目录
1 | MYSQL_KEYRINGDIR=/usr/local/mysql/keyring |
optimizer_trace 是 mysql5.6 之后加入的新功能, explain 是各种执行计划选择的结果, 如果想看整个执行计划以及对于多种索引方案之间是如何选择的, 就使用 optimizer_trace 这个功能
1 | OPTIMIZER_TRACE=ON |
不太懂, 默认关闭
1 | REPRODUCIBLE_BUILD = OFF |
临时文件的目录,P_tmpdir 的值可以在 /usr/include/stdio.h 中查看,默认 /tmp
1 | TMPDIR = P_tmpdir |
1 | WITH_ARCHIVE_STORAGE_ENGINE=ON |
分别开启 ARCHIVE 、BLACKHOLE 、FEDERATED、INNOBASE、PARTITION 引擎,默认都是开启的
是否启用 AddressSanitizer , 不太懂, 默认是关闭的
1 | WITH_ASAN = OFF |
不太懂, 看起来像是和上面一个选项是配套的, 默认关闭
1 | WITH_ASAN_SCOPE = OFF |
是否将客户端协议跟踪框架构建到客户端库中。默认情况下,此选项被启用
1 | WITH_CLIENT_PROTOCOL_TRACING = ON |
是否包括调试支持,默认关闭
1 | WITH_DEBUG=OFF |
是否使用默认的编译器来编译, 也就是 cmake
1 | WITH_DEFAULT_COMPILER_OPTIONS=ON |
是否使用 cmake 的特性集
1 | WITH_DEFAULT_FEATURE_SET=ON |
要使用 哪个libedit/ editline库。允许的值为 bundled(默认值)和 system。WITH_EDITLINE被添加到 MySQL 5.7.2 中。它取而代之WITH_LIBEDIT,已被删除
1 | WITH_EDITLINE = bundled |
是否构建libmysqld嵌入式服务器库。 注意: 从libmysqldMySQL 5.7.17 起,嵌入式服务器库已被弃用,MySQL 8.0 中将被删除
1 | WITH_EMBEDDED_SERVER=ON |
哪些额外的字符集包括: all, complex, none
1 | WITH_EXTRA_CHARSETS=all |
是否生成 memcached 共享库(libmemcached.so和 innodb_engine.so)
1 | WITH_INNODB_MEMCACHED=OFF |
1 | WITH_LZ4 = bundled |
是否启用 MemorySanitizer,支持它的编译器。默认是关闭。对于此选项,如果启用该功能,则所有连接到 MySQL 的库也必须已经通过启用该选项进行编译。此选项已添加到 MySQL 5.7.4 中
1 | WITH_MSAN=OFF |
是否构建快速开发周期插件
1 | WITH_RAPID=ON |
不太懂
1 | WITH_SASL = system |
要包含的 SSL 支持类型或要使用的 OpenSSL 安装的路径名。
ssl_type 可以是以下值之一:yes:使用系统 SSL 库(如果存在),否则与发行版捆绑在一起的库bundled:使用与发行版捆绑在一起的 SSL 库。这是默认值system:使用系统 SSL 库path_name是要使用的 OpenSSL 安装的路径名。使用这个可能比使用这个ssl_type值 更好 system,因为它可以防止 CMake 检测并使用系统上安装的较旧或不正确的 OpenSSL 版本。(另一个允许的方式做同样的事情是设置 CMAKE_PREFIX_PATH选项 path_name。)1 | WITH_SSL = ssl_type | path_name |
是否构建测试协议跟踪客户端插件. 默认情况下,此选项被禁用。启用此选项不起作用,除非该WITH_CLIENT_PROTOCOL_TRACING 选项被启用。如果 MySQL 配置启用了这两个选项,libmysqlclient客户端库将内置测试协议跟踪插件构建,所有标准的 MySQL 客户端都会加载该插件。但是,即使启用测试插件,默认情况下也不起作用。使用环境变量来控制插件; 请参见第 28.2.4.11.1 节“使用测试协议跟踪插件”。
不要启用
WITH_TEST_TRACE_PLUGIN,如果你想使用自己的协议跟踪的插件,因为只有一个这样的插件可以在同一时间被加载并出现错误尝试加载第二个选项。如果您已经使用启用了测试协议跟踪插件的 MySQL 来构建 MySQL,以了解它是如何工作的,那么在使用自己的插件之前,您必须重新构建 MySQL。
1 | WITH_TEST_TRACE_PLUGIN = OFF |
是否为支持它的编译器启用 Undefined Behavior Sanitizer。默认是关闭。此选项已添加到 MySQL 5.7.6
1 | WITH_UBSAN=OFF |
如果启用,则使用单元测试编译 MySQL。默认值为 ON,除非服务器未被编译
1 | WITH_UNIT_TESTS=ON |
是否在 Valgrind 头文件中编译,这将 Valgrind API 暴露给 MySQL 代码。默认是 OFF
要生成一个 Valgrind 感知的调试构建, -DWITH_VALGRIND=1通常与之结合-DWITH_DEBUG=1。请参阅 构建调试配置
1 | WITH_VALGRIND=OFF |
某些功能要求服务器使用压缩库支持(如功能COMPRESS()和 UNCOMPRESS()功能)以及客户端/服务器协议的压缩来构建 。这 WITH_ZLIB表明zlib支持的来源:
bundled:使用zlib与发行版捆绑在一起的 库。这是默认值。system:使用系统 zlib库。1 | WITH_ZLIB=bundled |
按 resful 风格设计接口: 按资源来设置接口的请求地址, 通过不同的请求类型来区分要对这个资源进行什么操作
get 语义是获取数据
post 语义是添加信息
delete 语义是删除数据
put 语义是更新数据(是更新这个数据的【所有信息】)
patch 语义是更新数据(是更新数据的【部分信息】)
假如要做注册
请求类型: post
请求地址: ‘/users’ (必须表示的是资源)
假如要做登录
请求类型: post (因为登录之后服务器的变化就添加了一个 session)
请求地址: ‘/sessions’
假如要做退出登录
请求类型: delete
请求地址: ‘/sessions/id’ (退出登录就是服务器删除 session)
假如要判断用户有没有登录
请求类型: get
请求地址 ‘/sessions’
总结: restful 风格 api
我们使用一个能够表示资源的地址(资源是数据库里的一条数据, 或是数组里的一个元素, 或者文件夹中的一个文件)
我们通过不同的请求类型(get, post, delete, put, patch), 对这个地址对应的资源进行 CRUL, 让后端代码根据不同的请求类型, 对数据做不同的操作
1 | /** |
1 |
WebSocket 是 HTML5 出的东西(协议)
WebSocket 协议的目标是在一个独立的持久连接上提供全双工双向通信。客户端和服务器可以向对方主动发送和接受数据。在 JS 中创建 WebSocket 后,会有一个 HTTP 请求发向浏览器以发起请求。在取得服务器响应后,建立的连接会使用 HTTP 升级将 HTTP 协议转换为 WebSocket 协议。也就是说,使用标准的 HTTP 协议无法实现 WebSocket,只有支持那些协议的专门浏览器才能正常工作。
由于 WebScoket 使用了自定义协议,所以 URL 与 HTTP 协议略有不同。未加密的连接为 ws://,而不是 http://。加密的连接为 wss://,而不是 https://。
WebSocket 是应用层协议,是 TCP/IP 协议的子集,通过 HTTP/1.1 协议的 101 状态码进行握手。也就是说,WebSocket 协议的建立需要先借助 HTTP 协议,在服务器返回 101 状态码之后,就可以进行 websocket 全双工双向通信了,就没有 HTTP 协议什么事情了。
WebSocket 是基于 TCP 的,TCP 的握手和 WebSocket 的握手是不同层次的。
TCP 的握手用来保证链接的建立,WebSocket 的握手是在 TCP 链接建立后告诉服务器这是个 WebSocket 链接,服务器你要按 WebSocket 的协议来处理这个 TCP 链接。
https://pan.lanzoui.com/b0f1c6hzc
1 | slmgr /skms kms.digiboy.ir |
1 | Windows Registry Editor Version 5.00 |
将以上内容复制到 reg 后缀的文件中, 双击, 然后重启电脑即可
1 | echo '/usr/bin/setxkbmap -option "caps:escape"' >> ~/.profile |
或者:
修改 /etc/default/keyboard
1 | XKBOPTIONS="caps:escape" |
将体积大而且不需要按需加载的包通过CDN的方式加载, 不参与打包, 例如: vue、axios、vue-router , 通过CDN加载的包不能使用Vue.use()
在 index.html 中通过 link 和 script 方法引入所需的 js 和 css

在 webpack.dev.conf.js 和 webpack.prod.conf.js 的module下均添加externals, 这样webpack编译打包时不处理它, 却可以 import 引用到它。
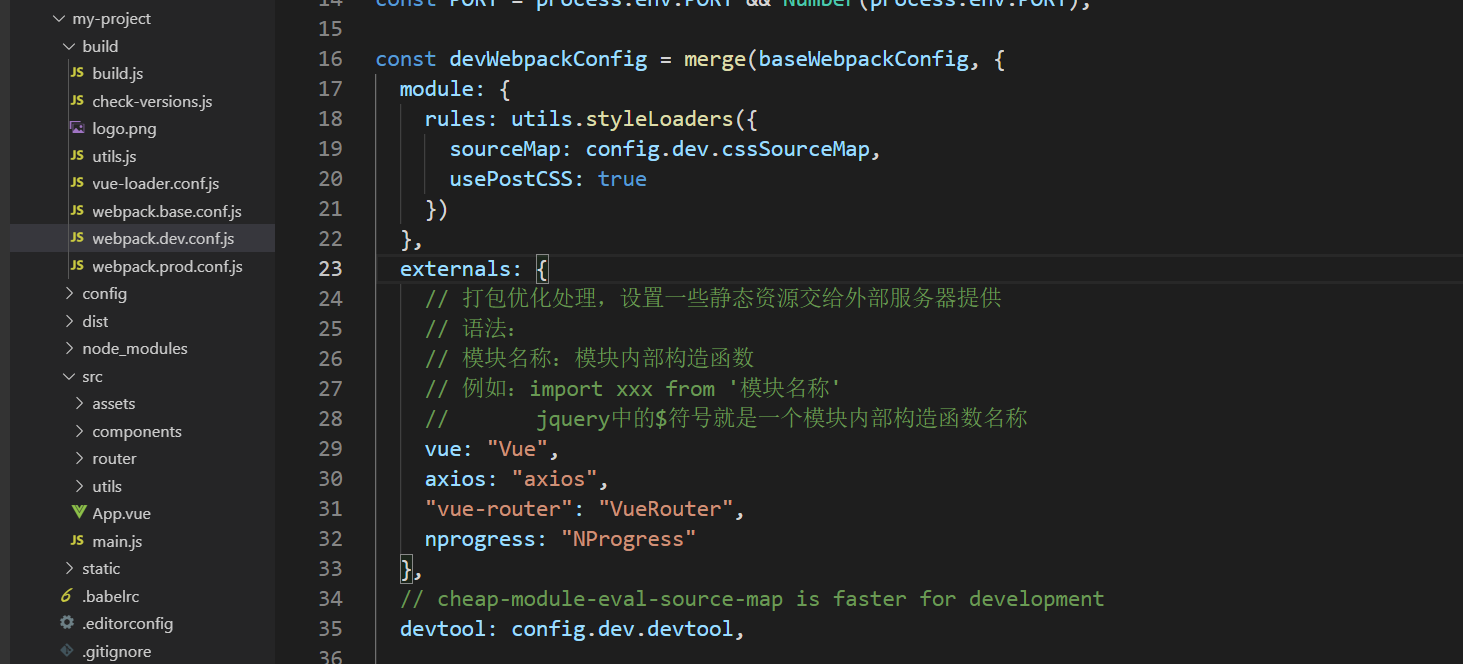
vue-cli3.0 不需要以上此配置。
每个包按需加载的方式都不同, 这里以 element-ui 为例, 在main.js主入口文件中给element-ui组件库做按需导入设置,去除没有使用的组件,进一步精简项目的总代码量。
参考: https://element.eleme.cn/#/zh-CN/component/quickstart
babel-plugin-component1 | npm install babel-plugin-component -D |
.babelrc 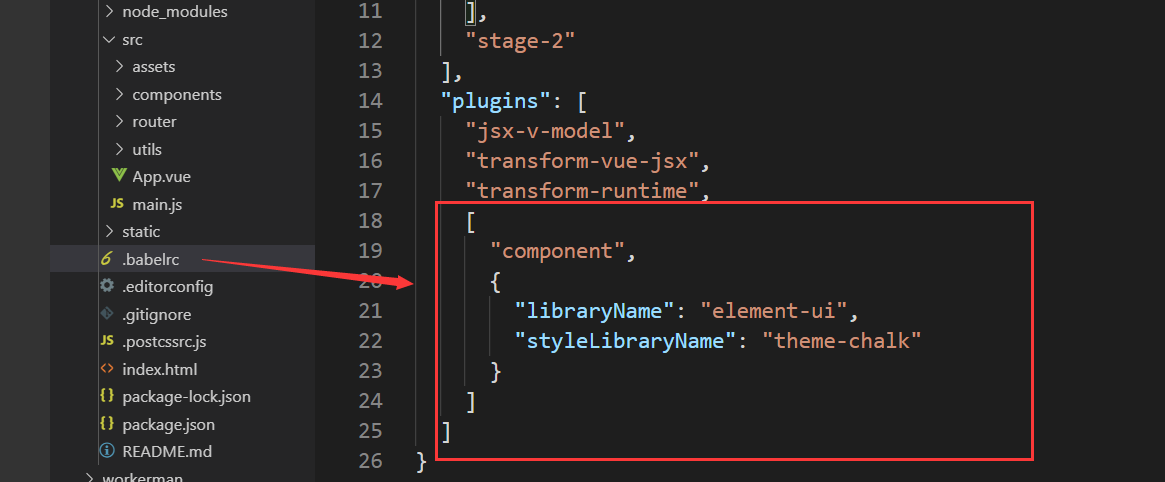
完整组件列表和引入方式(完整组件列表以 components.json 为准)
1 | import Vue from "vue" |
Vuex是实现组件之间数据共享的一种机制
父子传值或者兄弟传值,不好管理,而且有些需求实现不了
vuex提供了一种全新的数据共享管理机制, 该模式相比较简单的组件传值更加高端、大气、上档次
1 | npm i vuex -S |
1 | import Vuex from "vuex"; |
在 main.js 文件中添加:
1 | const store = new Vuex.Store({ |
1 | new Vue({ |
1 | this.$store.state.xxx; |
不要直接修改this.$store.state.xxx,容易造成数据混乱
同步
1 | mutations:{ |
异步
store 中存储的数据,不要放到 data 中, 而是要放到计算你属性中,因为:
1 | npm install -g vue-cli |
1 | vue init webpack my-project |
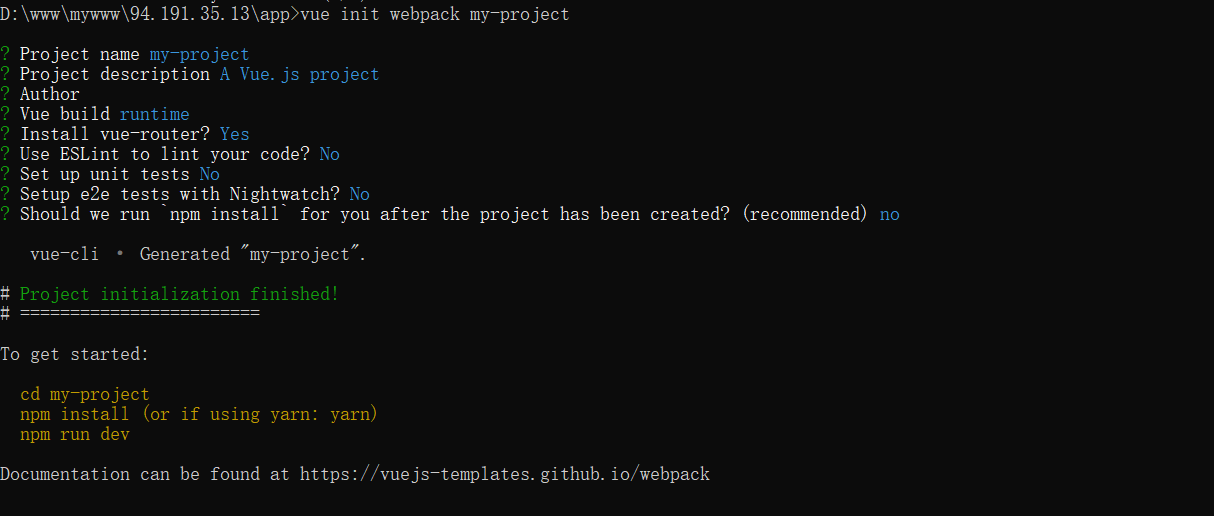
Vue build 选择 Runtime-only 选项Use ESLint to lint your code? 这个本应该应该 yes, 但是作为个人开发者, 选择 no 比较方便Should we run npm install for you after the project has been created? 选择 No, I will handle that myself
1 | cd my-project // 切换到项目根目录下 |
webpack做简单的配置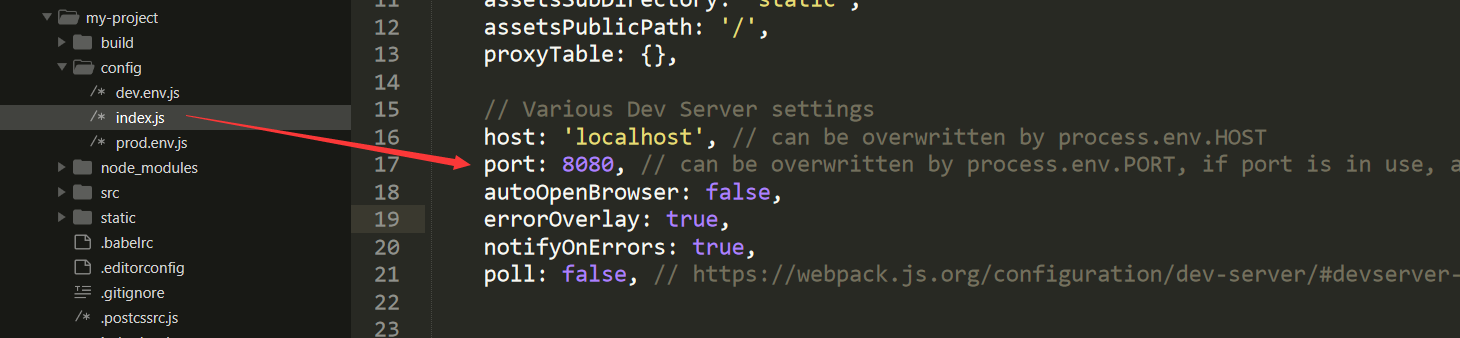
build 下的 webpack.prod.conf.js 中得 output 中添加 publicPath。
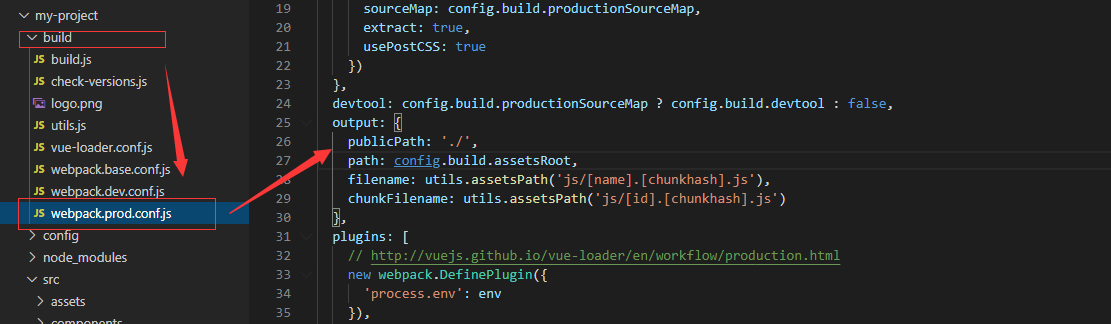
webpack.dev.conf.js 中添加如下配置:
1 | new HtmlWebpackPlugin({ |
1 | { |
1 | npm run dev |
1 | npm run build |
开发过程中, 用到的包需要安装
1 | npm i -D // 工程构建(开发时、“打包”时)依赖 ;例:xxx-cli , less-loader , babel-loader... |
npm i less-loader less -Djsx支持v-modelnpm i babel-plugin-jsx-v-model -D.babelrc的"plugins"下添加"jsx-v-model" 以上 1-7 是从零开始构建项目, 如果是已有项目拷贝复制, 肯定不能把 node_modules 目录一同复制, 所以我们可以复制除了node_modules以外的所有文件, 然后再执行 npm install 即可