当需要创建的子进程数量不多时,可以直接利用 multiprocessing 中的 Process 动态成生多个进程,但如果是上百甚至上千个目标,手动的去创建进程的工作量巨大,此时就可以用到 multiprocessing 模块提供的 Pool 方法。 初始化 Pool 时,可以指定一个最大进程数,当有新的请求提交到 Pool 中时,如果池还没有满,那么就会创建一个新的进程用来执行该请求;但如果池中的进程数已经达到指定的最大值,那么该请求就会等待,直到池中有进程结束,才会用之前的进程来执行新的任务。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
from multiprocessing import Pool defworker(msg): print(msg) po=Pool(3) #定义一个进程池,最大进程数3 for i inrange(10): po.apply_async(worker,(i)) print("----start----") po.close() #关闭进程池,关闭后po不再接收新的请求 po.join() #等待po中所有子进程执行完成,必须放在close语句之后 print("-----end-----")
如果要使用 Pool 创建进程,就需要使用 multiprocessing.Manager()中的 Queue(),而不是 multiprocessing.Queue(),否则会得到一条如下的错误信息:RuntimeError: Queue objects should only be shared between processes through inheritance.
假设由协程执行,在执行 A 的过程中,可以随时中断,去执行 B,B 也可能在执行过程中中断再去执行 A,结果可能是:
1 2 3 4 5 6
1 2 x y 3 z
但是在 A 中是没有调用 B 的,所以协程的调用比函数调用理解起来要难一些。 看起来 A、B 的执行有点像多线程,但协程的特点在于是一个线程执行,那和多线程比,协程有何优势?
最大的优势就是协程极高的执行效率。因为子程序切换不是线程切换,而是由程序自身控制,因此,没有线程切换的开销,和多线程比,线程数量越多,协程的性能优势就越明显。 第二大优势就是不需要多线程的锁机制,因为只有一个线程,也不存在同时写变量冲突,在协程中控制共享资源不加锁,只需要判断状态就好了,所以执行效率比多线程高很多。 因为协程是一个线程执行,那怎么利用多核 CPU 呢?最简单的方法是多进程+协程,既充分利用多核,又充分发挥协程的高效率,可获得极高的性能。


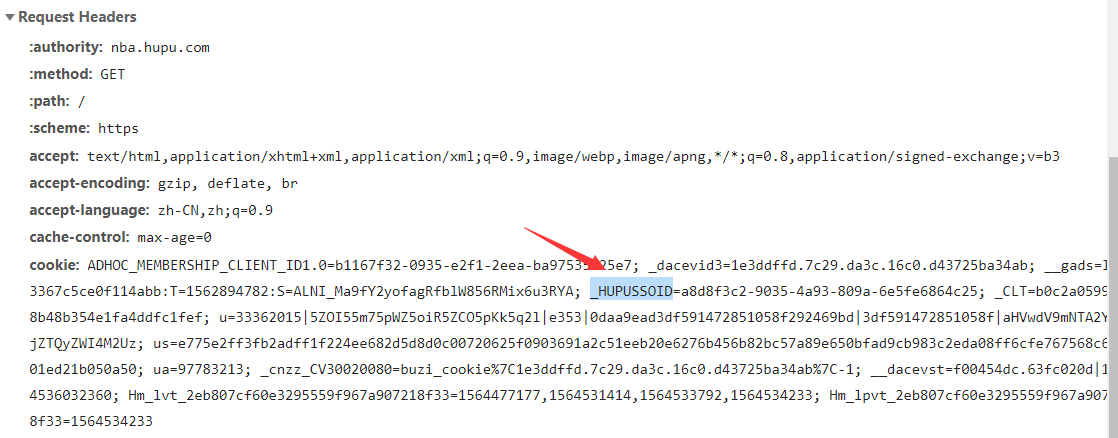
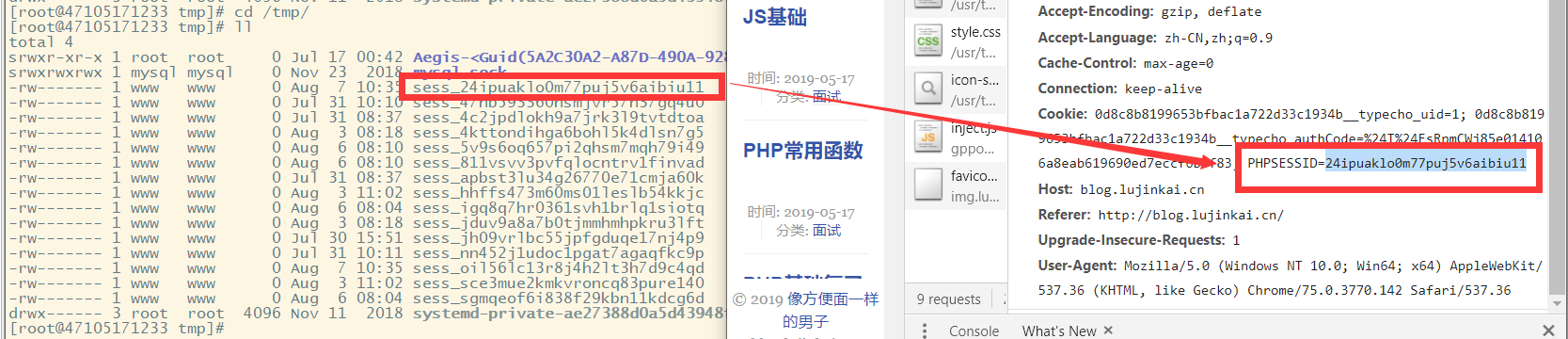 然后在发送给浏览器的数据包头部中的 Set-Cookie 字段中指定 session 的名称和对应的 sessionid,浏览器则根据该字段的信息在内存中创建一个 Cookie,严格来说叫 SessionCookie。下一次浏览器再访问服务器的时候便会在数据包头部的 Cookie 字段中加入该 Cookie。若服务器发现浏览器请求包头部中“Cookie”字段包含了名为 session.name 的 sessionid,就会根据该 sessionid 到 session.savepath 指定的路径下找到名称为“sess”+sessionid 的文件,对文件进行读取或写入操作,开始了和客户端之间的会话。
然后在发送给浏览器的数据包头部中的 Set-Cookie 字段中指定 session 的名称和对应的 sessionid,浏览器则根据该字段的信息在内存中创建一个 Cookie,严格来说叫 SessionCookie。下一次浏览器再访问服务器的时候便会在数据包头部的 Cookie 字段中加入该 Cookie。若服务器发现浏览器请求包头部中“Cookie”字段包含了名为 session.name 的 sessionid,就会根据该 sessionid 到 session.savepath 指定的路径下找到名称为“sess”+sessionid 的文件,对文件进行读取或写入操作,开始了和客户端之间的会话。