[root@centos7 ~]# mkfs.ext4 /dev/sdb5 mke2fs 1.42.9 (28-Dec-2013) Filesystem label= OS type: Linux Block size=1024 (log=0) Fragment size=1024 (log=0) Stride=0 blocks, Stripe width=0 blocks 128016 inodes, 512000 blocks 25600 blocks (5.00%) reserved for the super user First data block=1 Maximum filesystem blocks=34078720 63 block groups 8192 blocks per group, 8192 fragments per group 2032 inodes per group Superblock backups stored on blocks: 8193, 24577, 40961, 57345, 73729, 204801, 221185, 401409
Allocating group tables: done Writing inode tables: done Creating journal (8192 blocks): done Writing superblocks and filesystem accounting information: done
mount [-lhV] mount -a [-fFnrsvw] [-t vfstype] [-O optlist] mount [-fnrsvw] [-o option[,option]...] device|dir mount [-fnrsvw] [-t vfstype] [-o options] device dir
# 查看当前已挂载的所有设备 [root@centos7 ~]# mount sysfs on /sys type sysfs (rw,nosuid,nodev,noexec,relatime,seclabel) proc on /proc type proc (rw,nosuid,nodev,noexec,relatime) devtmpfs on /dev type devtmpfs (rw,nosuid,seclabel,size=487128k,nr_inodes=121782,mode=755) securityfs on /sys/kernel/security type securityfs (rw,nosuid,nodev,noexec,relatime) tmpfs on /dev/shm type tmpfs (rw,nosuid,nodev,seclabel) devpts on /dev/pts type devpts (rw,nosuid,noexec,relatime,seclabel,gid=5,mode=620,ptmxmode=000) ... ... ... # 通过查看/etc/mtab文件显示当前已挂载的所有设备 [root@centos7 ~]# ll /etc/mtab lrwxrwxrwx. 1 root root 17 Aug 14 19:22 /etc/mtab -> /proc/self/mounts
[root@centos7 ~]# pvcreate /dev/sdb WARNING: dos signature detected on /dev/sdb at offset 510. Wipe it? [y/n]: y Wiping dos signature on /dev/sdb. Physical volume "/dev/sdb" successfully created. [root@centos7 ~]# pvcreate /dev/sdc Physical volume "/dev/sdc" successfully created. [root@centos7 ~]# lsblk -f NAME FSTYPE LABEL UUID MOUNTPOINT sda |-sda1 xfs 25ea1f67-ee88-44b1-935e-8af77eadf856 /boot |-sda2 xfs 28eb957c-1e98-4175-9a00-3efdef247355 / |-sda3 xfs 91664c04-1540-4e35-8711-c3f183a556ca /data |-sda4 |-sda5 swap a1966abb-acf9-4f53-8a86-733a93c2d576 [SWAP] |-sda6 `-sda7 sdb LVM2_mem F4zIYp-IM1g-gJS6-ktqS-OZOD-u46a-z6YrQd sdc LVM2_mem rAL8Wi-ln8P-LmUK-FaQn-40Mk-iGw4-ocXIUe sr0 iso9660 CentOS 7 x86_64 2020-04-22-00-51-40-00 /data/repo/ [root@centos7 ~]# pvs PV VG Fmt Attr PSize PFree /dev/sdb lvm2 --- 10.00g 10.00g /dev/sdc lvm2 --- 5.00g 5.00g [root@centos7 ~]# pvdisplay "/dev/sdb" is a new physical volume of "10.00 GiB" --- NEW Physical volume --- PV Name /dev/sdb VG Name PV Size 10.00 GiB Allocatable NO PE Size 0 Total PE 0 Free PE 0 Allocated PE 0 PV UUID F4zIYp-IM1g-gJS6-ktqS-OZOD-u46a-z6YrQd
"/dev/sdc" is a new physical volume of "5.00 GiB" --- NEW Physical volume --- PV Name /dev/sdc VG Name PV Size 5.00 GiB Allocatable NO PE Size 0 Total PE 0 Free PE 0 Allocated PE 0 PV UUID rAL8Wi-ln8P-LmUK-FaQn-40Mk-iGw4-ocXIUe
POSIX:Portable Operating System Interface 可移植操作系统接口,定义了操作系统应该为应用程序 提供的接口标准,是 IEEE 为要在各种 UNIX 操作系统上运行的软件而定义的一系列 API 标准的总称。 Linux 和 windows 都要实现基本的 posix 标准,程序就在源代码级别可移植了
C 语言程序的实现过程
源代码->预处理->编译->汇编->链接
预处理:略 编译:将 C 转译成汇编 汇编:将汇编转译成机器指令 链接:调用链接器 ld 来链接程序运行需要的一大堆目标文件,以及所依赖的其它库文件,最后生成可执行文件
yum history [info|list|packages-list|packages-info|summary|addon-info|redo|undo|rollback|new|sync|stats]
范例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
[root@centos8 ~]# dnf history ID | Command line | Date and time | Action(s) | Altered ------------------------------------------------------------------------------- 4 | install lrzsz | 2020-08-15 09:58 | Install | 1 3 | install -y autofs | 2020-08-15 09:05 | Install | 1 2 | install vim wget -y | 2020-08-15 08:03 | Install | 5 1 | | 2020-07-29 05:12 | Install | 455 EE [root@centos8 ~]# dnf history info 4 Transaction ID : 4 Begin time : Sat 15 Aug 2020 09:58:11 AM EDT Begin rpmdb : 455:2fec96053059825d1e35cd07ef7f27130b90a171 End time : Sat 15 Aug 2020 09:58:11 AM EDT (0 seconds) End rpmdb : 456:d9d289d9345ad932d7563415cf622772184a6e92 User : root <root> Return-Code : Success Releasever : 8 Command Line : install lrzsz Packages Altered: Install lrzsz-0.12.20-43.el8.x86_64 @BaseOS
deb http://mirrors.aliyun.com/ubuntu/ bionic main restricted universe multiverse deb-src http://mirrors.aliyun.com/ubuntu/ bionic main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ bionic-security main restricted universe multiverse deb-src http://mirrors.aliyun.com/ubuntu/ bionic-security main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ bionic-updates main restricted universe multiverse deb-src http://mirrors.aliyun.com/ubuntu/ bionic-updates main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ bionic-proposed main restricted universe multiverse deb-src http://mirrors.aliyun.com/ubuntu/ bionic-proposed main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ bionic-backports main restricted universe multiverse deb-src http://mirrors.aliyun.com/ubuntu/ bionic-backports main restricted universe multiverse
-newerXY reference X 和 Y 是占位符,主要是查找 X 时间戳比 reference 的 Y 时间戳更新的文件。 reference 可以是时间字符串(参考 date -d 格式,推荐使用 yyyy-MM-dd hh:mm:ss),也可以是 X 可以是 a、B、c、m,Y 可以是 a、B、c、m、t。 a:atime; B:birth time 文件的出生日期,不是所有系统都支持这个参数; c:ctime; t:代表 reference 本身,此时 reference 必须是时间,不能是文件,显然只有 Y 可以设为 t,X 设为 t 是没有意义的
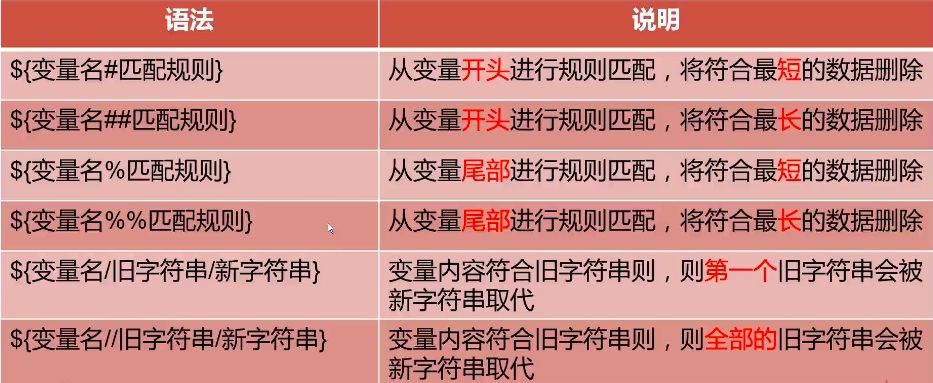
f # 显示已定义的函数 F # 显示已定义的函数名 g # 声明一个全局变量,name="value" 这种方式就是省略参数g,完整的写法是declare -g name="value",所以在函数中请使用 declare name="value",不要使用 name="value",除非你想声明一个全局变量 -p # 显示所有变量及其属性和值,不包括函数
为变量设置属性,如果没有声明变量,则显示设置此属性的变量: a # 声明索引数组 A # 声明关联数组 i # 声明整数,可以进行算数运算 l # 声明变量为小写字母 n # 为value设置引用属性 r # 声明只读变量,相当于 readonly,当前进程内,只能定义,不能修改,不能删除 t # 为变量设置trace属性,跟踪函数从调用shell继承DEBUG和RETURN类型的。trace属性对变量没有特殊意义 u # 声明变量为大写字母 x # 声明环境变量,相当于 export
# 范例一 lujinkai@Z510:~$ echo {a..z} a b c d e f g h i j k l m n o p q r s t u v w x y z lujinkai@Z510:~$ echo {a..z} | tr -d ' ' abcdefghijklmnopqrstuvwxyz lujinkai@Z510:~$ words="echo {a..z} | tr -d ' '" lujinkai@Z510:~$ echo$words echo {a..z} | tr -d ' ' lujinkai@Z510:~$ echo `echo$words` echo {a..z} | tr -d ' ' lujinkai@Z510:~$ eval$words abcdefghijklmnopqrstuvwxyz
注意:$@ 和 $* 只有在被双引号包起来的时候才会有差异,在 for in 循环中,不加引号的时候,$* 和 $@ 都可以正常遍历,加双引号的时候,$* 只有一个字符串变量
清空所有位置变量:
1
set --
范例:利用软链接实现同一个脚本不同功能
1
退出状态码
用于无条件终止当前脚本的执行 exit n
1 2 3 4 5 6 7 8 9 10
n == 0 #脚本执行成功 n == 1-125 #出错,这些对应的错误值由用户在脚本中定义 n == 1 #一般未知错误 n == 2 #不合适的shell命令 n == 126 #文件不可执行 n == 127 #不存在该命令 n == 128 #无效的退出参数 n == 128+x #与linux信号x相关的严重错误 n == 130 #通过ctrl+c终止的命令 n > 255 #正常范围之外的退出状态码
1-125 这些错误值可以由用户自定义 如果不给定 n 的值,而直接使用 exit,那么返回 exit 之前最后一条语句的状态,等于 exit $?
h #hashall,外部命令使用过一次后就会被hash下来,后面再使用这个命令就优先从hash中获取,通过`set +h`将h选项关闭 i #interactive-comments,说明当前shell是交互式shell,在脚本中,i选项是被关闭的 m #monitor,打开监控 B #braceexpand,大括号扩展 H #history,H选项打开,可以展开历史列表中的命令,可以通过!来完成,例如!!返回上一个历史命令,!n返回第n个历史命令
if []; then code... elif []; then code... elif []; then code... ... else code... fi
case
类似 php 中的 switch
case/esac
1 2 3 4 5 6 7 8 9 10 11 12 13
#! /bin/sh echo"Is it morning? Please answer yes or no." read YES_OR_NO case"$YES_OR_NO"in yes|y|Yes|YES) echo"Good Morning!";; [nN]*) echo"Good Afternoon!";; *) echo"Sorry, $YES_OR_NO not recognized. Enter yes or no." exit 1;; esac exit 0
case 支持 glob 风格的通配符:*、?、[]、|
流程控制 - 循环
for in
for in/do/done
递归遍历当前目录下的所有文件
1 2 3 4 5 6 7 8 9 10 11 12
#!/bin/bash dir=$(dirname"`readlink -f $0`") fn() { for filename in `ls$1`; do file=${1}/${filename} echo -e "$file\n" if [ -d "$file" ]; then fn $file fi done } fn $dir
while
while/do/done
无限循环
1 2 3
whiletrue; do 循环体 done
验证密码,限制尝试输入不超过 5 次
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
#!/bin/bash echo'enter password:' read -s try num=1 while [[ $try != '123456' ]]; do num=$(($num+1)) if [[ $num > 5 ]]; then echo'no change' break fi echo'try again' read -s try done if [[ $try == '123456' ]]; then echo'yes' fi
while read
while 循环的特殊用法,遍历文件或文本的每一行
1 2 3 4
# 依次读取file文件中的每一行,且将行赋值给变量X whileread X; do 循环体 done < file
lujinkai@Z510:~/data/test$ array=("Allen""Mike""Messi""Jerry""Hanmeimei""Wang") # 打印数组长度 lujinkai@Z510:~/data/test$ echo${#array[@]} 6 # 打印元素长度 lujinkai@Z510:~/data/test$ echo${#array[1]}# 打印第1个元素 Mike的长度 4 # 分片访问 lujinkai@Z510:~/data/test$ echo${array[@]:1:2} Mike Messi # 元素内容替换 lujinkai@Z510:~/data/test$ echo${array[@]/e/E} AllEn MikE MEssi JErry HanmEimei Wang lujinkai@Z510:~/data/test$ echo${array[@]//e/E} AllEn MikE MEssi JErry HanmEimEi Wang # 数组的遍历 forin${array[@]} do echo$val done
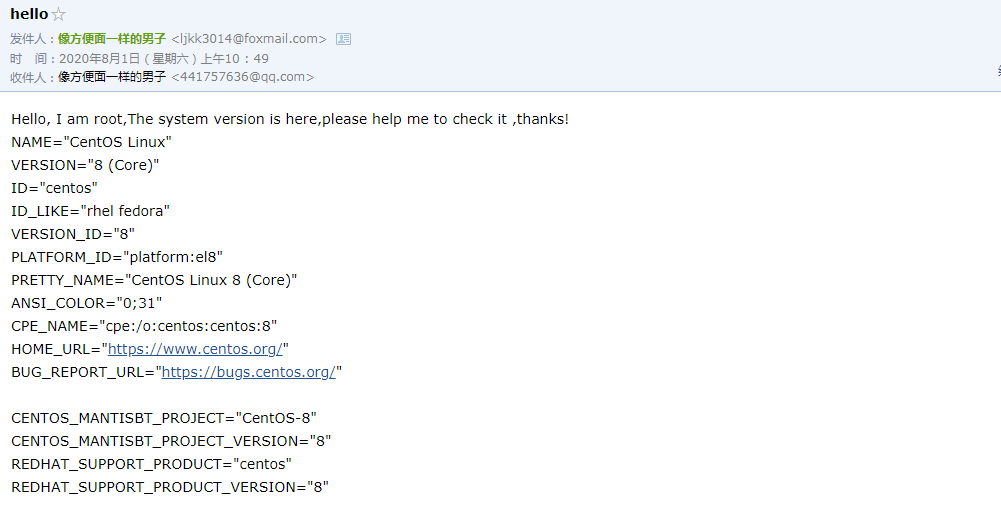
# 配置/etc/mail.rc set from=ljkk3014@foxmail.com set smtp=smtp.qq.com set smtp-auth-user=ljkk3014@foxmail.com set smtp-auth-password=jwopcmnpmawddbbg # 随便写的
1 2
# 发送邮件 [root@centos8 ~]# echo -e "Hello, I am `whoami`,The system version is here,please help me to check it ,thanks! \n`cat /etc/os-release`" | mail -s hello 441757636@qq.com
sed 是从文件或管道中读取一行,处理一行,输出一行;再读取一行,再处理一行,再输出一行,直到最后一行。每当处理一行时,把当前处理的行存储在临时缓冲区中,称为**模式空间(PatternSpace)**,接着用 sed 命令处理缓冲区中的内容,处理完成后,把缓冲区的内容送往屏幕。接着处理下一行,这样不断重复,直到文件末尾。一次处理一行的设计模式使得 sed 性能很高,sed 在读取大文件时不会出现卡顿的现象。如果使用 vi 命令打开几十 M 上百 M 的文件,明显会出现有卡顿的现象,这是因为 vi 命令打开文件是一次性将文件加载到内存,然后再打开。Sed 就避免了这种情况,一行一行的处理,打开速度非常快,执行速度也很快
1
sed [OPTION]... 'script;script;...' [input-file]...
p # print 打印查询的行 Ip # 忽略大小写输出 d # 删除匹配到的行 a # append,追加内容到下一行,支持使用\n实现多行追加; 如果要解析空格,需要用反斜杠\ i text # insert,在行前面插入内容 c text # change,替换行 w file # 保存模式匹配的行到指定文件 r file # 从file中读取内容,插入到匹配到的行的下一行 = # 打印匹配到行的行号 ! 命令 # 对没有匹配到的行进行处理,例如 !p 是打印未匹配到的行、!atext 是在未匹配到的行的下一行添加text
s/pattern/string/修饰符 # 查找替换 修饰符: g # 一行里如果由多个匹配到的内容,全部替换。默认只替换第一个。 p # 打印替换成功的行 w file # 将成功替换的行保存至文件中 I,i # 忽略大小写
练习
1.将 php.ini-production 中的无关信息去掉
1
sed -E '/^; /d;/^;+;$/d' /usr/local/src/php-7.4.8/php.ini-production | uniq > php.ini
2.获取分区利用率
1
lujinkai@Z510:~$ df | sed -En '/^\/dev\/sd/s/.* ([0-9]+)%.*/\1/p'
# 第一步: 判断命令为内部命令还是外部命令, 如果二者都是, 则查询内部命令 [root@4710419222 ~]# type -a echo echo is a shell builtin echo is /usr/bin/ech # 第二步: 使用whatis查询man的分组 [root@4710419222 ~]# whatis echo echo (1) - display a line of text echo (3x) - curses input options # 第三步 [root@4710419222 ~]# man 1 echo # 如果是外部命令, 简单的查询可以省略第二步, 直接 --help [root@4710419222 ~]# type hostname hostname is /usr/bin/hostname [root@4710419222 ~]# hostname --help
范例二:
1 2 3 4 5 6 7 8
[root@centos8 ~]# type -a history history is a shell builtin [root@centos8 ~]# whatis history history (1) - bash built-in commands, see bash(1) [root@centos8 ~]# man 1 history # 此时发现找不到history # 可以使用 /keyword 进行搜索, 使用 n 和 N 进行上下查找 # 然后很容易就找到了history的man手册
man 页面分组
不同类型的帮助称为不同的“章节”,统称为 Linux 手册
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
1 Executable programs or shell commands 2 System calls (functions provided by the kernel) 3 Library calls (functions within program libraries) 4 Special files (usually found in /dev) 5 File formats and conventions eg /etc/passwd 6 Games 7 Miscellaneous (including macro packages and conventions), e.g. man(7), groff(7) 8 System administration commands (usually only for root) 9 Kernel routines [Non standard] 1:用户命令 2:系统调用 3:C库调用 4:设备文件及特殊文件 5:配置文件格式 6:游戏 7:杂项 8:管理类的命令 9:Linux 内核API