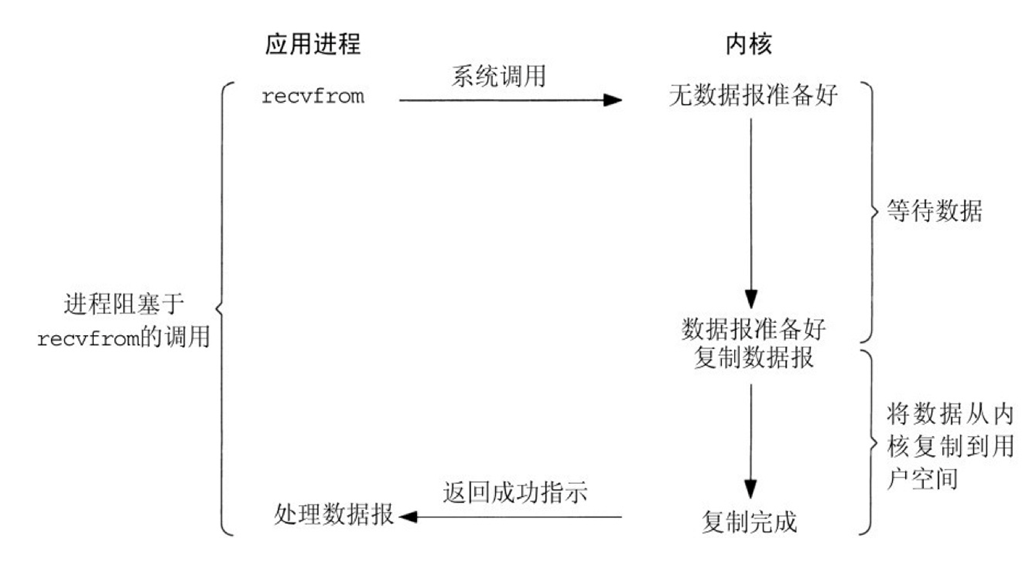
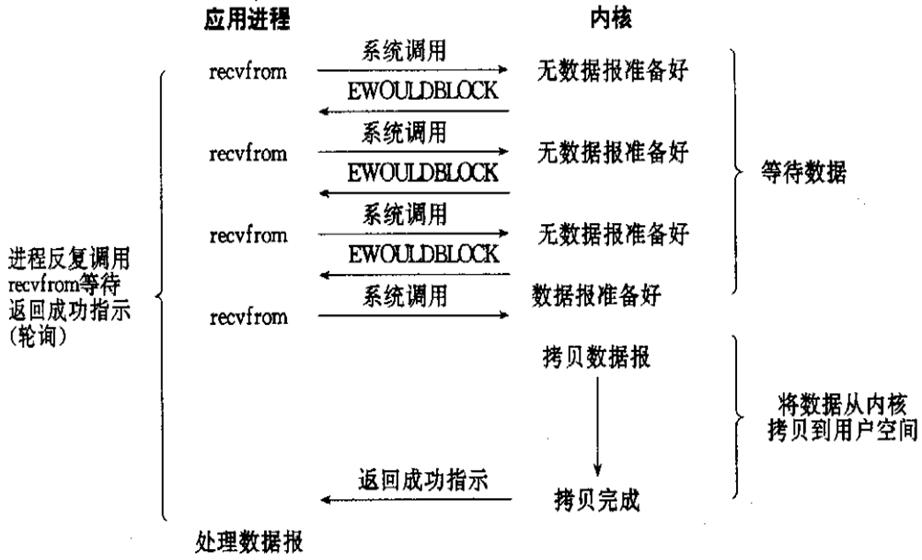
SQL语言
数据库组件(对象)
数据库、表、索引、视图、用户、存储过程、函数、触发器、事件调度器等
SQL 语言语法标准
命名规则
必须以字母开头,可包括数字和三个特殊字符(# _ $);
不要使用 MySQL 的保留字
SQL 语句分类
DDL:Data Defination Language 数据定义语言
CREATE,DROP,ALTER
DML:Data Manipulation Language 数据操纵语言
INSERT,DELETE,UPDATE
DQL:Data Query Language 数据查询语言
SELECT
DCL:Data Control Language 数据控制语言
GRANT,REVOKE,COMMIT,ROLLBACK
字符集和排序
uft8 最长占用 3 个字节,utf8mb4 最长占用 4 个字节,为了获取更好的兼容性,推荐使用 uft8mb4
以下排序规则:
utf8mb4_unicode_ci:基于标准的 Unicode 来排序和比较,能够在各种语言之间精确排序
utf8mb4_general_ci:没有实现 Unicode 排序规则,在遇到某些特殊语言或者字符集,排序结果可能不一致
utf8mb4_0900_ai_ci:比以上两种都好,mysql8.0 默认的排序规则,mysql8.0 以下版本不支持
所以:mysql8.0 使用默认排序,mysql8.0 以下版本设置 utf8mb4_general_ci
数据库
创建数据库
1
create database [if not exists] 'db_name' character set 'utf8mb4' collate 'utf8mb4_general_ci';
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
1610:20:30(root@localhost) [(none)]> create database if not exists blog character set utf8mb4 collate utf8mb4_general_ci;
Query OK, 1 row affected (0.00 sec)
10:20:36(root@localhost) [(none)]> show create database blog;
+----------+------------------------------------------------------------------+
| Database | Create Database |
+----------+------------------------------------------------------------------+
| blog | CREATE DATABASE `blog` /*!40100 DEFAULT CHARACTER SET utf8mb4 */ |
+----------+------------------------------------------------------------------+
1 row in set (0.01 sec)
10:20:40(root@localhost) [(none)]> exit
Bye
[root@centos7 script]$cat /data/mysql/blog/db.opt
default-character-set=utf8mb4
default-collation=utf8mb4_general_ci修改数据库
1
alter database 'db_name' character set 'utf8mb4';
只能修改字符集,不能修改排序
删除数据库
1
drop database [if exists] 'db_name';
查看数据库列表
1
show databases;
数据类型

选择数据类型三大原则:
- 更小的通常更好,尽量使用可正确存储数据的最小数据类型
- 简单就好,简单数据类型的操作通常需要更少的 CPU 周期
- 尽量避免 NULL,包含为 NULL 的列,对 MySQL 更难优化
1. 整数
- int(m)里的 m 表示 select 查询结果集中的显示宽度,并不影响实际的取值范围,规定了 MySQL 的一些交互工具(例如 MySQL 命令行客户端)用来显示字符的个数。对于存储和计算来说,Int(1)和 Int(20)是相同的
- BOOL,BOOLEAN:布尔型,是 TINYINT(1)的同义词。zero 值被视为假,非 zero 值视为真
2. 浮点
float(m,d) 单精度浮点型 8 位精度(4 字节) m 总个数,d 小数位
double(m,d) 双精度浮点型 16 位精度(8 字节) m 总个数,d 小数位
3. 定点数
decimal(m,d) 十进制,精确值,总个数 m<65,小数位 d<30 且 d<\m
MySQL5.0 和更高版本将数字打包保存到一个二进制字符串中(每 4 个字节存 9 个数字)。
例如:
decimal(18,9)小数点两边将各存储 9 个数字,一共使用 9 个字节:其中,小数点前的 9 个数字用 4 个字节,小数点后的 9 个数字用 4 个字节,小数点本身占 1 个字节
浮点类型在存储同样范围的值时,通常比 decimal 使用更少的空间。float 使用 4 个字节存储。double 占用 8 个字节
因为需要额外的空间和计算开销,所以应该尽量只在对小数进行精确计算时才使用 decimal,例如存储财务数据。但在数据量比较大的时候,可以考虑使用 bigint 代替 decimal
4. 字符串
char(n):固定长度,最多 255 个字符
varchar(n):可变长度,最多 65535 个字符,很多人以为 n 最大是 255,其实不然,只是 varchar(255)是习惯性写法
tinytext:可变长度,最多 255 个字符
text:可变长度,最多 65535 个字符
mediumtext:可变长度,最多 2^24-1 个字符
longtext:可变长度,最多 2^32-1 个字符
BINARY(M):固定长度,可存储二进制或字符,长度为 0-M 字节
VARBINARY(M):可变长度,可存二进制或字符,允许长度为 0-M 字节
ENUM:枚举
SET:集合
char 和 varchar
char(n) 若存入字符数小于 n,则以空格补于其后,查询之时再将空格去掉,所以 char 类型存储的字符串末尾不能有空格,varchar 不限于此
.char(n) 固定长度,char(4)不管是存入几个字符,都将占用 4 个字节,varchar 是存入的实际字符数+1 个字节所以 varchar(4),存入 3 个字符将占用 4 个字节
char 比 varchar 快
varchar 和 text
- varchar 可指定 n,text 不能指定,内部存储 varchar 是存入的实际字符数+1 个字节(n< n>255),text 是实际字符数+2 个字节。
- text 类型不能有默认值
- varchar 可直接创建索引,text 创建索引要指定前多少个字符。varchar 查询速度快于 text
5. 二进制 BLOB
- TEXT 以文本方式存储,英文存储区分大小写,而 Blob 以二进制方式存储,不分大小写
- BLOB 存储的数据只能整体读出
- TEXT 可以指定字符集,BLOB 不用指定字符集
6. 日期时间
- date:日期 ‘2008-12-2’
- time:时间 ‘12:25:36’
- datetime:日期时间 ‘2008-12-2 22:06:44’
- timestamp:自动存储记录修改时间
- YEAR(2), YEAR(4):年份
- timestamp:字段里的时间数据会随其他字段修改的时候自动刷新,这个数据类型的字段可以存放这条记录最后被修改的时间
7. 修饰符
适用所有类型的修饰符:
- DEFAULT 默认值、
- NULL 数据列可包含 NULL 值,默认值
- NOT NULL 数据列不允许包含 NULL 值,*为必填选项
- PRIMARY KEY 主键,所有记录中此字段的值不能重复,且不能为 NULL
- UNIQUE KEY 唯一键,所有记录中此字段的值不能重复,但可以为 NULL
- CHARACTER SET name 指定一个字符集
适用数值型的修饰符:
- AUTO_INCREMENT 自动递增,适用于整数类型
- UNSIGNED 无符号
insert、update、select、delete
insert
插入单条数据
1
2insert into 表名 values(值列表, 注意: 值的顺序一定要和表结构中的顺序保持一致);
insert into 表名 (字段列表) values(值列表);注意:插入字段的个数,必须要与值的个数一致,字段的顺序可以与表结构中的字段顺序不一致,插入字段可以省略,但是省略的字段必须要有 default 值
插入多条数据
1
2insert into 表名 values(),(),()...;
insert into 表名(字段列表) values(),(),()...;从其他表中 copy 数据
1
2insert into 目标表 select * from 数据来源表;
insert into 目标表(字段列表) select 字段列表 from 数据来源表;蠕虫复制:将自己表中的数据插入到自己表中,可以用来测试数据库性能
replace into
主要是用来解决在添加数据时, 与主键或唯一键冲突的情况下,数据如何变化的问题
update
1 | update 表名 set 字段1= 值1, 字段2= 值2,... where 条件; |
注意:一定要指定更新的条件,如果没有指定则更新的是整张表
delete
1 | delete from 表名 where 条件; # 如果不加条件,则为清空表 |
另外:
1 | truncate 表名; # 清空表,主键也会被摧毁,重新开始 |
select
单表操作
select 五子句,每个子句都可以省略, 但是位置不能乱
1
2
3
4
5
6select 字段列表 from 表名 where 条件 group by 字段 having 条件 order by ASC | DESC limit m,n;
# group by : 按照字段进行分组, 目的是为了统计, 通常配合MySQL中的聚合函数来使用。
# having : 对分组之后的结果, 在进行一次过滤。
# order by : asc是升序,desc是降序
# limit: limit n 是显示n条数据, limit m,n 是从m开始(不包含m),显示n条数据。别名: as
运算符: =,>,<,<=,>=,!=
is null 和 is not null
in 和 not in
between and 和 not between and
逻辑判断: and(&&) or(||)
聚合函数:聚合函数对一组值执行计算并返回单一的值。除了 count 以外,聚合函数会忽略空值。聚合函数经常和 group by 子句一起使用1
2
3
4
5count(*) 统计数量
sum(字段) 求和
avg(字段) 平均值
min(字段) 求最小值
max(字段) 求最大值多表操作
join
1
2
3
4Select * from 表A cross|inner |left outer|right outer | natural | join 表B on 表A.字段名= 表B.字段名
# 最常用的是左连接
select * from 表A left join 表B on 表A.字段名 = 表B.字段名;
select 语句处理顺序:

练习:
练习
导入 hellodb.sql 生成数据库
- 在 students 表中,查询年龄大于 25 岁,且为男性的同学的名字和年龄
- 以 ClassID 为分组依据,显示每组的平均年龄
- 显示第 2 题中平均年龄大于 30 的分组及平均年龄
- 显示以 L 开头的名字的同学的信息
- 显示 TeacherID 非空的同学的相关信息
- 以年龄排序后,显示年龄最大的前 10 位同学的信息
- 查询年龄大于等于 20 岁,小于等于 25 岁的同学的信息
- 以 ClassID 分组,显示每班的同学的人数
- 以 Gender 分组,显示其年龄之和
- 以 ClassID 分组,显示其平均年龄大于 25 的班级
- 以 Gender 分组,显示各组中年龄大于 25 的学员的年龄之和
- 显示前 5 位同学的姓名、课程及成绩
- 显示其成绩高于 80 的同学的名称及课程
- 取每位同学各门课的平均成绩,显示成绩前三名的同学的姓名和平均成绩
- 显示每门课程课程名称及学习了这门课的同学的个数
- 显示其年龄大于平均年龄的同学的名字
- 显示其学习的课程为第 1、2,4 或第 7 门课的同学的名字
- 显示其成员数最少为 3 个的班级的同学中年龄大于同班同学平均年龄的同学
- 统计各班级中年龄大于全校同学平均年龄的同学
SHOW 语句
常用 show 语句:
显示所有数据库
显示数据库中所有表
1
2
3show databases;
show tables;
show tables from database_name;显示数据表中所有列
1
show columns from database_name.table_name
显示一个用户的权限,结果显示类似 grant 命令
1
2
3
4
5
6
7
808:04:50(root@localhost) [(none)]> show grants for root@localhost;
+---------------------------------------------------------------------+
| Grants for root@localhost |
+---------------------------------------------------------------------+
| GRANT ALL PRIVILEGES ON *.* TO 'root'@'localhost' WITH GRANT OPTION |
| GRANT PROXY ON ''@'' TO 'root'@'localhost' WITH GRANT OPTION |
+---------------------------------------------------------------------+
2 rows in set (0.00 sec)显示表的索引
1
show index from mysql.user;
显示一些系统特定资源的信息,例如,正在运行的线程数量
1
show status;
显示系统变量的名称和值
1
show variables;
显示系统中正在运行的所有进程,也就是当前正在执行的查询。大多数用户可以查看他们自己的进程,但是如果他们拥有 process 权限,就可以查看所有人的进程,包括密码
1
show processlist;
显示 database 中的每个表的信息。信息包括表类型和表的最新更新时间
1
show table status from mysql;
示服务器所支持的不同权限
1
show privileges;
显示创建数据库的语句
显示创建数据表的语句
1
208:16:18(root@localhost) [(none)]> show create database mysql;
08:16:18(root@localhost) [(none)]> show create table mysql.user;显示可用的存储引擎和默认引擎
1
08:19:02(root@localhost) [(none)]> show engines;
显示 innoDB 存储引擎的状态
1
08:21:11(root@localhost) [(none)]> show engine innodb status;
显示最后一个执行的语句所产生的错误、警告和通知
显示最后一个执行语句所产生的错误
1
2show warnings;
show errors;查看视图定义
VIEW 视图
虚拟表,保存实表的查询结果,相当于别名
创建视图:
1
2
3create view 视图名称 as 查询语句;
# 例如
create view v_age as * from tb_stu where age < 25;查看视图
1
2SHOW CREATE VIEW view_name #只能看视图定义
SHOW CREATE TABLE view_name # 可以查看表和视图删除视图
1
DROP VIEW [IF EXISTS] view_name
FUNCTION 函数
分为系统内置函数和自定义函数
内置函数
参考:mysql8.0、mysql5.7,注意:从 mysql5.7 开始,取消了 password()函数
常见内置函数:
database():当前所在数据库
now()
1
2
3
4
5
6
708:53:59(root@localhost) [mysql]> select now();
+---------------------+
| now() |
+---------------------+
| 2020-10-19 20:56:46 |
+---------------------+
1 row in set (0.00 sec)curdate():当前日期
curtime():当前时间
datediff():时间差
1
2
3
4
5
6
708:53:42(root@localhost) [mysql]> select datediff('2020-10-19','2020-7-27');
------------------------------------+
| datediff('2020-10-19','2020-7-27') |
+------------------------------------+
| 84 |
+------------------------------------+
1 row in set (0.00 sec)version()
from_unixtime():时间戳转日期
1
2
3
4
5
6
7
8
9
10
11
12
13
1408:48:39(root@localhost) [mysql]> select from_unixtime(1603111741);
+---------------------------+
| from_unixtime(1603111741) |
+---------------------------+
| 2020-10-19 20:49:01 |
+---------------------------+
1 row in set (0.00 sec)
08:50:10(root@localhost) [mysql]> select from_unixtime(1603111741,'%Y-%m-%d %T');
+-----------------------------------------+
| from_unixtime(1603111741,'%Y-%m-%d %T') |
+-----------------------------------------+
| 2020-10-19 20:49:01 |
+-----------------------------------------+
1 row in set (0.00 sec)
文本处理函数:
- trim():去除两边的空格
- upper():返回大写字符
- lower():返回小写字符
- concat():返回连接字符串 ★★★
- substring():返回截取的字符
- repace(str, str1, str2):在 str 中, 将字符串 str1 替换为 str2
数学函数:
- abs(x):返回 x 的绝对值
- bin(x):返回 x 的二进制(oct 八进制, hex 返回十六进制)
- ceiling(x):向上取整
- floor(x):向下取整
- mod(被除数, 除数):返回余数, 取模
- pow(底数, 指数):返回求指数值
自定义函数
user-defined function,UDF,保存在 mysq.proc 表中
…
变量
两种变量:系统内置变量和用户自定义变量
- 系统变量:MySQL 数据库中内置的变量,可用@@var_name 引用
- 用户自定义变量分为以下两种
- 普通变量:在当前会话中有效,可用@var_name 引用
- 局部变量:在函数或存储过程内才有效,需要用 DECLARE 声明,之后直接用 var_name 引用
PROCEDURE 存储过程
多表 SQL 语句的集合,可以独立执行,存储过程保存在 mysql.proc 表中
流程控制
存储过程 和 函数 中可以使用流程控制来控制语句的执行
- IF:用来进行条件判断。根据是否满足条件,执行不同语句
- CASE:用来进行条件判断,可实现比 IF 语句更复杂的条件判断
- LOOP:重复执行特定的语句,实现一个简单的循环
- LEAVE:用于跳出循环控制,相当于 SHELL 中 break
- ITERATE:跳出本次循环,然后直接进入下一次循环,相当于 SHELL 中 continue
- REPEAT:有条件控制的循环语句。当满足特定条件时,就会跳出循环语句
- WHILE:有条件控制的循环语句
TRIGGER 触发器
触发器是由事件来触发某个操作, 这些事件包括 insert、update 和 delete 语句。当执行这些事件时,就会激活触发器执行响应的操作
Event 事件
用户管理
用户创建,新建用户默认权限:USAGE
1
CREATE USER [IF NOT EXISTS] 'USERNAME'@'HOST' [IDENTIFIED BY 'password'];
用户重命名
1
RENAME USER old_user_name TO new_user_name;
删除用户
1
DROP USER [IF EXISTS] 'USERNAME'@'HOST'
修改密码
如果 mysql.user 表的 authentication_string 和 password 字段都保存密码,authentication_string 优先生效
1
2
3# 方法一
ALTER USER [IF EXISTS] 'root'@'localhost' IDENTIFIED BY \"${rootpwd}\";
# 其他方法,略...忘记管理员密码的解决方法
- 重启 mysqld 时,使用选项
--skip-grant-tables --skip-networking - 使用 update 命令修改 mysql.user 表,把管理员密码去掉
- 移除上述两个选项,然后重启
- 使用
ALTER USER 'root'@'localhost' IDENTIFIED BY \"${rootpwd}\";设置密码
1
2
3
4
5
6
7
8
9
10
11
12
13
14[root@c71 ~]$vim /etc/my.cnf
[mysqld]
skip-grant-tables
skip-networking # MySQL8.0不需要此选项
...
[root@c71 ~]$systemctl restart mysqld.service
[root@c71 ~]$msyql -e "update mysql.user set authentication_string='' where user='root' and host='localhost';"
[root@c71 ~]$vim /etc/my.cnf
[mysqld]
# skip-grant-tables
# skip-networking # MySQL8.0不需要此选项
...
[root@c71 ~]$systemctl restart mysqld.service
[root@c71 ~]$mysql -e "alter user 'root'@'localhost' IDENTIFIED BY \"123456\";"- 重启 mysqld 时,使用选项
角色管理
给账户分配角色,更加方便管理多个同样权限的账户
| 语句 | 作用 |
|---|---|
CREATE ROLE 和 DROP ROLE |
创建和删除角色 |
GRANT 和 REVOKE |
给角色授权和取消授权 |
SHOW GRANTS |
查看角色权限 |
SET DEFAULT ROLE |
设置账户默认使用什么角色 |
SET ROLE |
改变当前会话角色 |
CURRENT_ROLE()函数 |
显示当前会话的角色 |
| mandatory_roles 和 activate_all_roles_on_login 系统变量 | 允许定义用户登陆时强制的或者激活授权的角色 |
权限管理 GRANT/REVOKE
三种授权方式:
给用户分配权限
1
2
3
4
5
6
7
8
9
10
11
12
13
14GRANT
priv_type [(column_list)][, priv_type [(column_list)]] ...
ON [object_type] priv_level
TO user_or_role [, user_or_role] ...
[WITH GRANT OPTION]
[AS user
[WITH ROLE
DEFAULT
| NONE
| ALL
| ALL EXCEPT role [, role ] ...
| role [, role ] ...
]
]- priv_type:权限类型,有很多种
- column_list:有些权限作用与数据表的字段
- object_type:表(TABLE)|函数(FUNCTION)|存储过程(PROCEDURE)
- priv_level:
- * | *.*:所有数据库
- db_name.*:指定数据库中所有表
- db_name.tbl_name:指定数据库的指定数据表
- db_name.routine_name:指定数据库的函数、存储过程、触发器
- priv_level:
- with_option:设置权限某些参数,例如:
- MAX_QUERIES_PER_HOUR count
- MAX_UPDATES_PER_HOUR count
- MAX_CONNECTIONS_PER_HOUR count
- MAX_USER_CONNECTIONS count
- priv_type:权限类型,有很多种
给用户分配角色
1
2
3GRANT role [, role] ...
TO user_or_role [, user_or_role] ...
[WITH ADMIN OPTION]代理其他用户:这种情况暂时不研究
查看用户权限:
1 | SHOW GRANTS FOR 'user'@'host'; |
示例:
1 | mysql> show grants for root@localhost; |
取消授权:
1 | REVOKE |
设置权限后需要刷新权限:
1 | FLUSH PRIVILEGES; |
权限类型:
所有权限、管理类、程序类、数据库级别、表级别、字段级别
所有权限:
ALL PRIVILEGES或ALL管理类:
CREATE USER、FILE、SUPER、SHOW DATABASES、RELOAD、SHUTDOWN、REPLICATION SLAVE、REPLICATION CLIENT、LOCK TABLES、PROCESS、CREATE TEMPORARY TABLES程序类:针对 FUNCTION、PROCEDURE、TRIGGER
CREATE、ALTER、DROP、EXCUTE库和表级别:针对 DATABASE、TABLE
ALTER、CREATE、CREATE VIEW、DROP INDEX、SHOW VIEW、WITH GRANT OPTION:能将自己获得的权限转赠给其他用户数据操作:
SELECT、INSERT、DELETE、UPDATE字段级别:
SELECT(col1,col2,...)、UPDATE(col1,col2,...)、INSERT(col1,col2,...)