Pod 的生命周期:https://kubernetes.io/zh/docs/concepts/workloads/pods/pod-lifecycle/
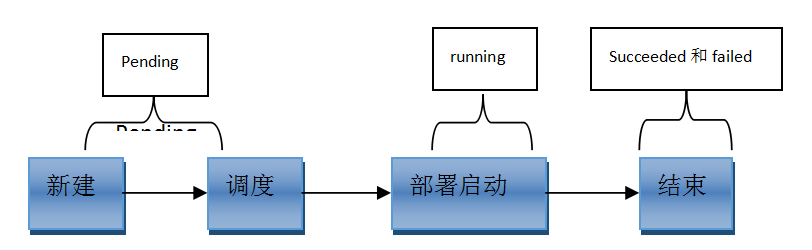
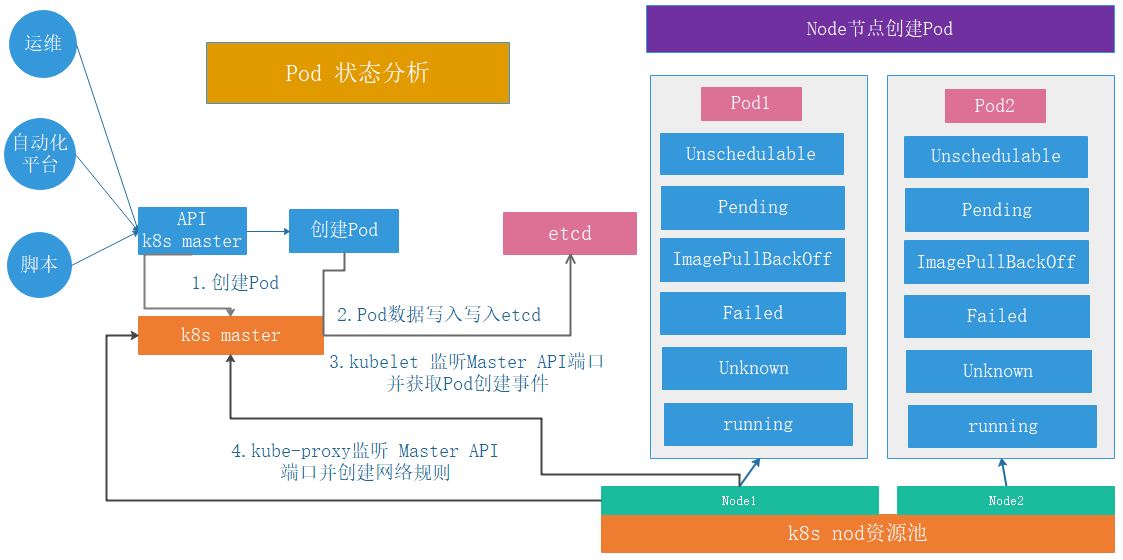
Pod 状态
![]()
第一阶段
1
2
3
4
| Pending
Failed
Unknown
Succeeded
|
第二阶段
1
2
3
4
5
6
| Unschedulable
PodScheduled
Initialized
ImagePullBackOff
Running
Ready
|
第三阶段
![]()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| Error
NodeLost
Unkown
Waiting
Pending
Terminating:
CrashLoopBackOff
InvalidImageName
ImageInspectError
ErrImageNeverPull
ImagePullBackOff
RegistryUnavailable
ErrImagePull
CreateContainerConfigError
CreateContainerError
PreStartContainer
PostStartHookError
RunContainerError
ContainersNotInitialized
ContainersNotReady
ContainerCreating
PodInitializing
DockerDaemonNotReady
NetworkPluginNotReady
|
Pod 调度过程
参考:kube-scheduler
Pod 探针
https://kubernetes.io/zh/docs/concepts/workloads/pods/pod-lifecycle/#container-probes
探针是 kubelet 对容器执行的定期诊断,以保证 Pod 的状态始终处于运行状态,要执行诊断,kubelet 调用由容器实现的 Handler(处理程序),有三种类型的处理程序:
1
2
3
| ExecAction
TCPSocketAction
HTTPGetAction
|
每次探测都将获得以下三种结果之一:
1
2
3
| 成功:容器通过了诊断
失败:容器未通过诊断
未知:诊断失败,因此不会采取任何行动
|
探针类型
1
2
3
| livenessProbe
readinessProbe
|
livenessProbe 和 readinessProbe 的对比:
1
2
3
4
5
6
7
| 1. 配置参数一样
2. livenessProbe用于控制是否重启pod,readinessProbe用于控制pod是否添加至service
3. livenessProbe连续探测失败会重启、重建pod,readinessProbe不会执行重启或者重建Pod操作
4. livenessProbe连续检测指定次数失败后会将容器置于(Crash Loop BackOff)且不可用,readinessProbe不会
5. readinessProbe 连续探测失败会从service的endpointd中删除该Pod,livenessProbe不具备此功能,但是会将容器挂起livenessProbe
建议:两个探针都配置
|
探针配置
探针有很多配置字段,可以使用这些字段精确的控制存活和就绪检测的行为:
1
2
3
4
5
| initialDelaySeconds: 120
periodSeconds: 60
timeoutSeconds: 5
successThreshold: 1
failureThreshold: 3
|
HTTP 探测器可以在 httpGet 上配置额外的字段:
1
2
3
4
5
| host:
scheme: http
path: /monitor/index.html
httpHeaders:
port: 80
|
HTTP 探针示例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
|
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
replicas: 1
selector:
matchLabels:
app: ng-deploy-80
template:
metadata:
labels:
app: ng-deploy-80
spec:
containers:
- name: ng-deploy-80
image: nginx:1.17.5
ports:
- containerPort: 80
livenessProbe:
httpGet:
path: /index.html
port: 80
initialDelaySeconds: 5
periodSeconds: 3
timeoutSeconds: 5
successThreshold: 1
failureThreshold: 3
---
apiVersion: v1
kind: Service
metadata:
name: ng-deploy-80
spec:
ports:
- name: http
port: 81
targetPort: 80
nodePort: 40012
protocol: TCP
type: NodePort
selector:
app: ng-deploy-80
|
TCP 探针示例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
|
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
replicas: 1
selector:
matchLabels:
app: ng-deploy-80
template:
metadata:
labels:
app: ng-deploy-80
spec:
containers:
- name: ng-deploy-80
image: nginx:1.17.5
ports:
- containerPort: 80
livenessProbe:
tcpSocket:
port: 80
initialDelaySeconds: 5
periodSeconds: 3
timeoutSeconds: 5
successThreshold: 1
failureThreshold: 3
---
apiVersion: v1
kind: Service
metadata:
name: ng-deploy-80
spec:
ports:
- name: http
port: 81
targetPort: 80
nodePort: 40012
protocol: TCP
type: NodePort
selector:
app: ng-deploy-80
|
ExecAction 探针
基于指定的命令对 Pod 进行特定的状态检查
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
|
apiVersion: apps/v1
kind: Deployment
metadata:
name: redis-deployment
spec:
replicas: 1
selector:
matchLabels:
app: redis-deploy-6379
template:
metadata:
labels:
app: redis-deploy-6379
spec:
containers:
- name: redis-deploy-6379
image: redis
ports:
- containerPort: 6379
livenessProbe:
exec:
command:
- /usr/local/bin/redis-cli
- quit
initialDelaySeconds: 5
periodSeconds: 3
timeoutSeconds: 5
successThreshold: 1
failureThreshold: 3
---
apiVersion: v1
kind: Service
metadata:
name: redis-deploy-6379
spec:
type: NodePort
ports:
- name: http
port: 6379
targetPort: 6379
nodePort: 40016
protocol: TCP
selector:
app: redis-deploy-6379
|
Pod 重启策略
k8s 在 Pod 出现异常的时候会自动将 Pod 重启,以恢复 Pod 中的服务
1
2
3
4
| restartPolicy:
Always
OnFailure
Never
|
镜像拉取策略
配置最佳实践 | Kubernetes
1
2
3
4
| imagePullPolicy:
IfNotPresent
Always
Never
|