基础
什么是 k8s?
kubernetes:容器的管理和编排系统
k8s 由多个组件组成,部署在一群服务器之上,将所有服务器整合成一个资源池,然后向客户端提供各种接口, 客户端只需要调用相应接口就可以管理容器,至于底层容器具体跑在哪台服务器,不可见也不需要关心
针对各种特定的业务,尤其是比较依赖工程师经验的业务(例如数据库集群宕机后的数据恢复、各种集群的扩缩容),可以将一系列复杂操作代码化,这个代码在 k8s 中就叫 operator,只要用好各种 operator,就可以方便高效的解决各种问题,这样,运维工程师的主要工作就变成了维护 k8s,确保 k8s 自身能够良好运行
k8s 内置了各种 operator,但是这些 operator 更重视通用性,很难完全匹配实际工作需要,所以就需要对 k8s 进行二次开发,编写各种 operator,这也是 SRE 工程师的必备技能之一
operator 能单独管理应用集群,实现复杂操作;controllor:控制器,只能实现简单的容器操作
开发人员为 k8s 开发应用程序的时候,通常不会完整的部署一个分布式 k8s 集群,而是使用一个叫做 MiniKube,它可以在单机上模拟出一个完整意义上的 k8s 集群
节点
资源池中的各个服务器叫做节点,节点有两种:
- Worker Node:运行 Pod,一般称 Node
- Master Node:运行控制平面组件,不运行 pod,一般称为 Master
组件
k8s 组件分为三种: 控制平面组件、Node 组件、Addons
https://kubernetes.io/docs/concepts/overview/components/
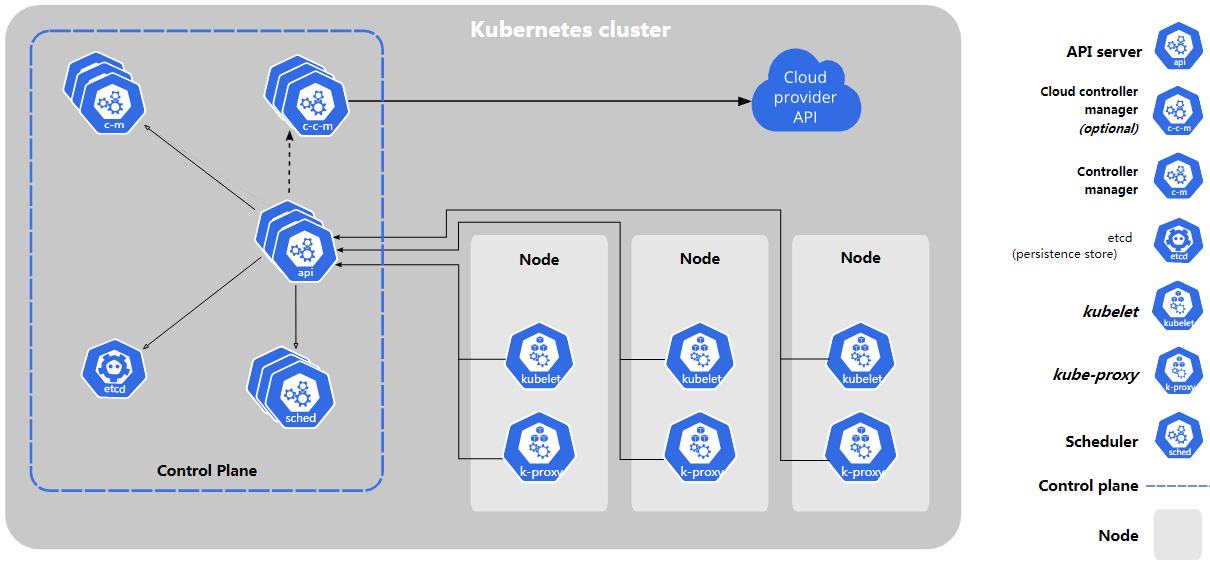
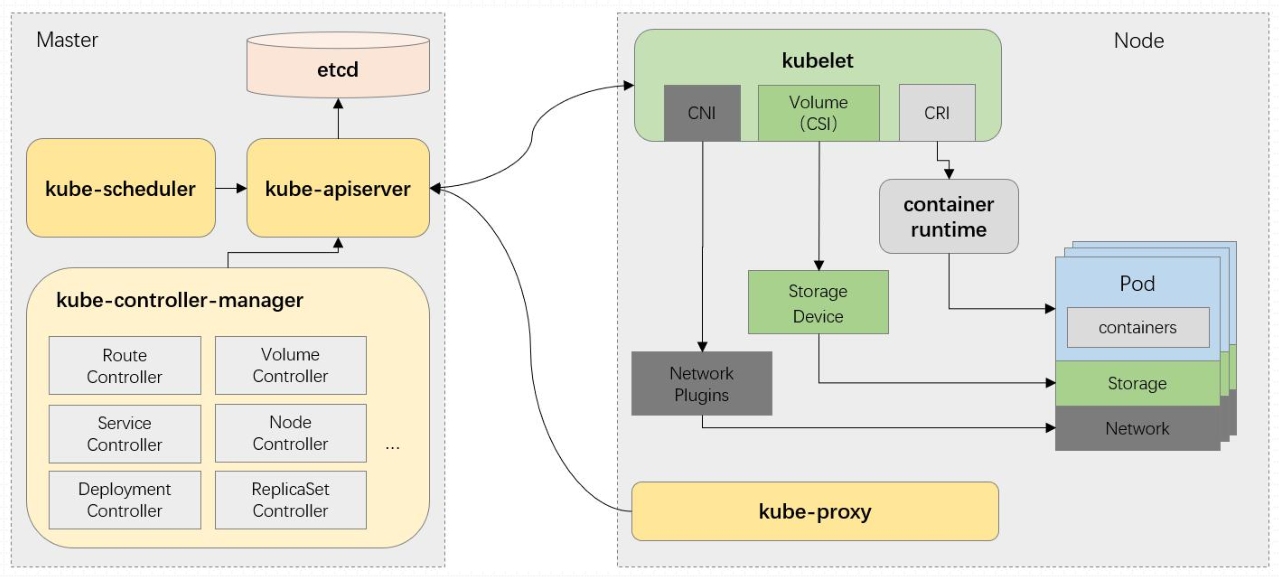
控制平面组件
控制平面(control plane)管理 Node 和 Node 上的 Pods
控制平面组件可以分别运行在任意节点上,但是为了简单,通常会将所有控制平面组件运行在同一个节点上,还可以以副本的形式运行在多个节点上,然后禁止在这种节点上运行 pod,这种节点就叫做 Master Node(后文简称 Master),当集群中只有一个 Master 时,就是单控制平面,有多个 Master 时,就是多控制平面,生产中肯定是多控制平面,但是学习中一般只使用单控制平面
kube-apiserver
https 服务器,监听在 6443 端口,它将 k8s 集群内的一切都抽象成资源,提供 RESTful 风格的 API,对资源(对象)进行增删改查等管理操作
apiserver 是整个 k8s 系统的总线,所有组件之间,都是通过它进行协同,它是唯一可以存储 k8s 集群的状态信息的组件(储存在 Etcd)
生产中,apiserver 需要做冗余,因为无状态,所以最少部署两个 apiserver,因为是 https 服务器,所以需要做四层负载,使用 Nginx、HAProxy、LVS 均可,然后搭配 keepalived 给负载均衡做高可用
关于健康监测,分为 AH(主动监测)和 PH(被动监测或者叫异常值探测)
kube-controller-manager
控制器管理器,负责管理控制器,真正意义上让 k8s 所有功能得以实现的控制中心,controller-manager 中有很多 controller(deployment 等数十种),这些 controller 才是真正意义上的 k8s 控制中心,负责集群内的 Node、Pod 副本、服务端点(Endpoint)、命名空间(Namespace)、服务账号(ServiceAccount)、资源定额(ResourceQuota)的管理
当某个 Node 意外宕机时,Controller Manager 会及时发现并执行自动化修复流程,确保集群始终处于预期(yaml 配置文件指定)的工作状态
k8s 可以把运维人员日常重复性的工作代码化,就是将多 controller 打包起来,单一运行
默认监听本机的 10252 端口
controller loop:控制循环
kube-scheduler
调度器,调度 pod,它的核心作用就是运行应用,scheduler 时刻关注着每个节点的资源可用量,以及运行 pod 所需的资源量,让二者达到最佳匹配,让 pod 以最好的状态运行
在整个系统中起”承上启下”作用,承上:负责接收 Controller Manager 创建的新的 Pod,为其选择一个合适的 Node;启下:Node 上的 kubelet 接管 Pod 的生命周期
1 | 通过调度算法为待调度Pod列表的每个Pod从可用Node列表中选择一个最适合的Node,并将信息写入etcd中node节点上的kubelet通过API Server监听到kubernetes Scheduler产生的Pod绑定信息,然后获取对应的Pod清 |
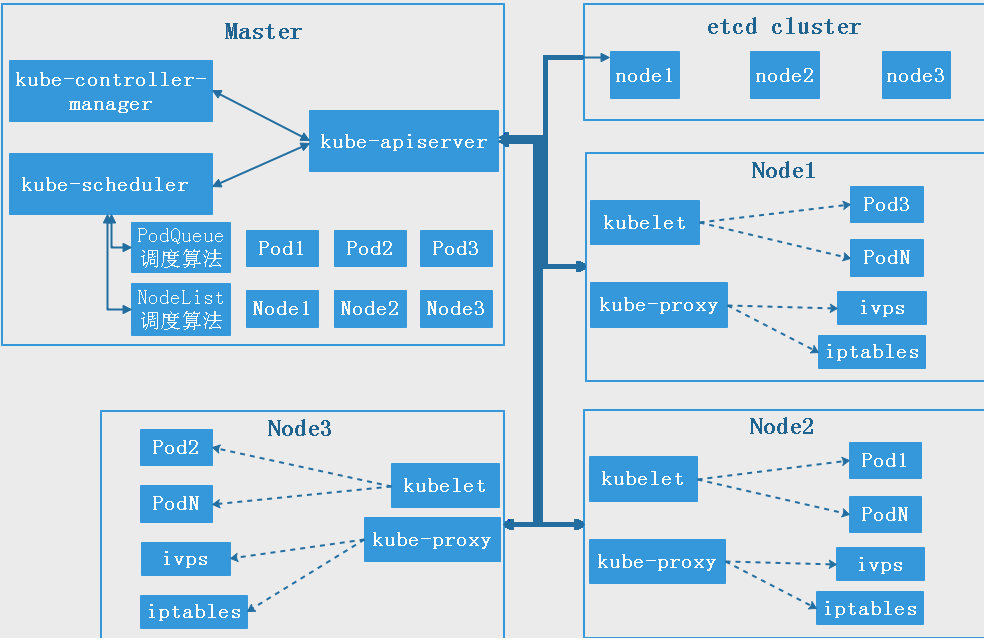
etcd
https://etcd.io/
https://github.com/etcd-io/etcd
第三方、非 k8s 内置,它的目标是构建一个高可用的分布式键值(key-value)数据库,为避免脑裂,通常部署 3 个或 5 个节点
1 | 完全复制 # 集群中的每个节点都可以使用完整的存档 |
etcd 有多个不同的 API 访问版本,v1 版本已经废弃,etcd v2 和 v3 本质上是共享同一套 raft 协议代码的两个独立的应用,接口不一样,存储不一样,数据互相隔离。也就是说如果从 Etcd v2 升级到 Etcd v3,原来 v2 的数据还是只能用 v2 的接口访问,v3 的接口创建的数据也只能访问通过 v3 的接口访问
以下以内容以 v3 为准
etcdctl 是 etcd 的命令行客户端工具
1 | etcdctl [options] command [command options] [arguments...] |
管理成员
1 | etcdctl member list |
验证成员状态:
1 | $etcdctl endpoint health \ |
增删改查
增 put
1
2
3
4
5
6
7etcdctl put [options] <key> <value> (<value> can also be given from stdin) [flags]
$etcdctl put /testkey "test data"
OK
$etcdctl get --print-value-only /testkey
test data删 del
1
2
3
4etcdctl del [options] <key> [range_end] [flags]
$etcdctl del /testkey
1改 put
直接覆盖即可
1
2$etcdctl put /testkey "test data2"
OK查 get
1
2
3
4
5
6
7
8
9
10etcdctl get [options] <key> [range_end] [flags]
$etcdctl get --print-value-only /testkey
test data2
$etcdctl get --prefix --keys-only / # 获取所有key
$etcdctl get --prefix --keys-only /calico
$etcdctl get --prefix --keys-only /registry
$etcdctl get --prefix --keys-only /registry/services
$etcdctl get /calico/ipam/v2/handle/ipip-tunnel-addr-k8s-master.ljk.local
watch 机制
etcd v3 的 watch 机制支持 watch 某个固定的 key,也支持 watch 一个范围,发生变化就主动触发通知客户端
相比 Etcd v2, Etcd v3 的一些主要变化:
1 | 1. 接口通过grpc提供rpc接口,放弃了v2的http接口,优势是长连接效率提升明显,缺点是使用不如以前方便,尤其对不方便维护长连接的场景。 |
watch 测试:
1 | # 在 etcd node1 上watch一个key,没有此 key 也可以执行 watch,后期可以再创建 |
数据备份与恢复机制
v2 版本数据备份与恢复:
1 | # 备份 |
v3 版本数据备份与恢复:
1 | etcdctl snapshot <subcommand> [flags] |
1 | $etcdctl snapshot save snapshot.db # 备份 |
cloud-controller-manager
略…
Node 组件
Node 组件运行在所有的节点上,包括 Master
kubelet
与 api server 建立联系,监视 api server 中与自己 node 相关的 pod 的变动信息,执行指令操作
在 kubernetes 集群中,每个 Node 节点都会启动 kubelet 进程,处理 Master 节点下发到本节点的任务,管理 Pod 和其中的容器。kubelet 会在 API Server 上注册节点信息,定期向 Master 汇报节点资源使用情况,并通过 cAdvisor(顾问)监控容器和节点资源,可以把 kubelet 理解成 Server/Agent 架构中的 agent,kubelet 是 Node 上的 pod 管家
kube-porxy
https://kubernetes.io/zh/docs/concepts/services-networking/service/
https://kubernetes.io/zh/docs/reference/command-line-tools-reference/kube-proxy/
守护进程,管理当前节点的 iptables 或 ipvs 规则,而且管理的只是和 service 相关的规则
监控 service,把集群上的每一个 service 的定义转换为本地的 ipvs 或 iptables 规则
kube-proxy 是运行在集群中的每个节点上的网络代理,实现了 Kubernetes 服务概念的一部分
kube-proxy 维护节点上的网络规则。这些网络规则允许从集群内部或外部的网络会话到 Pods 进行网络通信
kube-proxy 使用操作系统包过滤层(如果有的话)并且它是可用的。否则,kube-proxy 将自己转发流量
Container runtime
通常是 docker,其他类型的容器也支持
Addons
附加组件扩展了 Kubernetes 的功能
插件使用 Kubernetes 资源(DaemonSet, Deployment,等等)来实现集群特性。因为它们提供了集群级的特性,所以插件的命名空间资源属于 kube-system 命名空间
DNS
CoreDNS,k8s 中,DNS 是至关重要的,所有的访问都不会基于 ip,而是基于 name,name 再通过 DNS 解析成 ip
Web UI
集群监控系统
prometheus
集群日志系统
EFK、LG
Ingress Controller
入栈流量控制器,是对集群中服务的外部访问进行管理的 API 对象,典型的访问方式是 HTTP。
…
附件千千万,按需部署
CNI
CNI:Container Network Interface,容器网络接口
kubernetes 的网络插件遵从 CNI 规范的 v0.4.0 版本
网络插件有很多,最常用的是 flannel 和 Project Calico,生产环境用后者的最多
跨主机 pod 之间通信,有两种虚拟网络,有两种:overlay 和 underlay
- overlay:叠加网络 ,搭建隧道
- underlay:承载网络,设置路由表
overlay
OverLay 其实就是一种隧道技术,VXLAN,NVGRE 及 STT 是典型的三种隧道技术,它们都是通过隧道技术实现大二层网络。将原生态的二层数据帧报文进行封装后在通过隧道进行传输。总之,通过 OverLay 技术,我们在对物理网络不做任何改造的情况下,通过隧道技术在现有的物理网络上创建了一个或多个逻辑网络即虚拟网络,有效解决了物理数据中心,尤其是云数据中心存在 的诸多问题,实现了数据中心的自动化和智能化
以 flannel 为例,默认网段 10.224.1.0/16,flannel 在每个节点创建一个网卡 flannel.1,这是一个隧道,网段 10.2441.0/32 - 10.244.255/32,而每个节点上的容器的 ip 为 10.244.x.1/24 - 10.244.x.254/24,也就是说 flannel 默认支持最多 256 个节点,每个节点上又最多支持 256 个容器
underlay
UnderLay 指的是物理网络,它由物理设备和物理链路组成。常见的物理设备有交换机、路由器、防火墙、负载均衡、入侵检测、行为管理等,这些设备通过特定的链路连接起来形成了一个传统的物理网络,这样的物理网络,我们称之为 UnderLay 网络
UnderLay 是底层网络,负责互联互通而 Overlay 是基于隧道技术实现的,overlay 的流量需要跑在 underlay 之上
资源
Pod、Deployment、Service 等等,反映在 Etcd 中,就是一张张的表
kube-apiserver 以群组分区资源,群组化管理的 api 使得其可以更轻松地进行扩展,常用的 api 群组分为两类:
- 命名群组:
/apis/$GROUP_NAME/$VERSION,例如/apis/apps/v1 - 核心群组 core:简化了路径,
/api/$VERSION,即/api/v1
打印 kube-apiserver 支持的所有资源:
1 | kubectl api-resources |
对象
资源表中的每一条数据项就是一个对象,例如 Pod 表中的数据项就是 Pod 对象。所以资源表通常不叫 Pod 表、Deployment 表…,而是叫做 PodList、DeploymentList…
创建对象
三种方式
- 命令式命令:命令,全部配置通过选项指定
- 命令式配置文件:命令,加载配置文件
- 声明式配置文件:声明式命令,加载配置清单,推荐使用
配置清单:
1 | # 配置清单的规范叫做资源规范,范例: |
资源清单是 yml 格式,api-server 会自动转成 json 格式
如果实际状态和期望状态有出入,控制器的控制循环就会监控到差异,然后将需要做出的更改提交到 apiserver,调度器 scheduler 监控到 apiserver 中有未执行的操作,就会去找适合执行操作的 node,然后提交到 apiserver,kubelet 监控到 apiserver 中有关于自己节点的操作,就会执行操作,将执行结果返回给 apiserver,apiserver 再更新实际状态
查看对象
外部访问
1 | domain:6643/apis/$GROUP_NAME/$VERSION/namespaces/$NAMESPACE/$NAME/$API_RESOURCE_NAME |
内部访问
以下三种访问方式是一样的:
1 | # 方式一,这种方式最方便 |
注:1.20 之前的版本可以直接curl 127.0.0.1:8080,并且通过--insecure-port可以修改默认的 8080 端口,1.20.4 之后的版本取消了这种不安全的访问方式,只能通过以上方式三,先kubectl proxy代理一下,默认端口也改成了 8001
The kube-apiserver ability to serve on an insecure port, deprecated since v1.10, has been removed. The insecure address flags
--addressand--insecure-bind-addresshave no effect in kube-apiserver and will be removed in v1.24. The insecure port flags--portand--insecure-portmay only be set to 0 and will be removed in v1.24. (#95856, @knight42, [SIG API Machinery, Node, Testing])
1 | $kubectl get pods net-test1 -o yaml |
以上返回的数据,每个字段表示的意义可以通过 kubectl explain 查询帮助
1 | kubectl explain <type>.<fieldName>[.<fieldName>] |
1 | $kubectl explain pod.apiVersion |
lease 租约
lease 是分布式系统中一个常见的概念,用于代表一个分布式租约。典型情况下,在分布式系统中需要去检测一个节点是否存活的时,就需要租约机制。
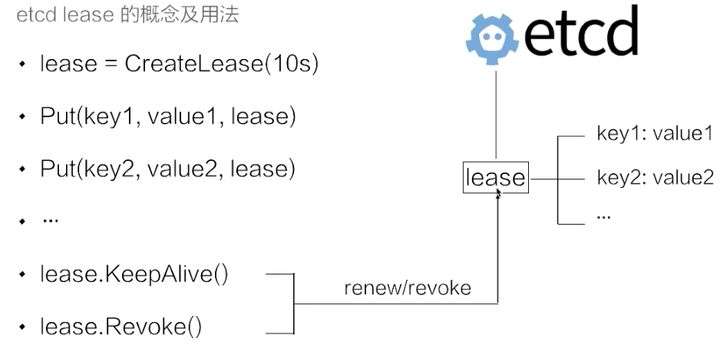
上图示例中的代码示例首先创建了一个 10s 的租约,如果创建租约后不做任何的操作,那么 10s 之后,这个租约就会自动过期。接着将 key1 和 key2 两个 key value 绑定到这个租约之上,这样当租约过期时 etcd 就会自动清理掉 key1 和 key2,使得节点 key1 和 key2 具备了超时自动删除的能力。
如果希望这个租约永不过期,需要周期性的调用 KeeyAlive 方法刷新租约。比如说需要检测分布式系统中一个进程是否存活,可以在进程中去创建一个租约,并在该进程中周期性的调用 KeepAlive 的方法。如果一切正常,该节点的租约会一致保持,如果这个进程挂掉了,最终这个租约就会自动过期。
在 etcd 中,允许将多个 key 关联在同一个 lease 之上,这个设计是非常巧妙的,可以大幅减少 lease 对象刷新带来的开销。试想一下,如果有大量的 key 都需要支持类似的租约机制,每一个 key 都需要独立的去刷新租约,这会给 etcd 带来非常大的压力。通过多个 key 绑定在同一个 lease 的模式,我们可以将超时间相似的 key 聚合在一起,从而大幅减小租约刷新的开销,在不失灵活性同时能够大幅提高 etcd 支持的使用规模。