ELK
配套 B 站教程:https://www.bilibili.com/video/BV1Be4y167n9
Elastic Stack 在企业的常见架构
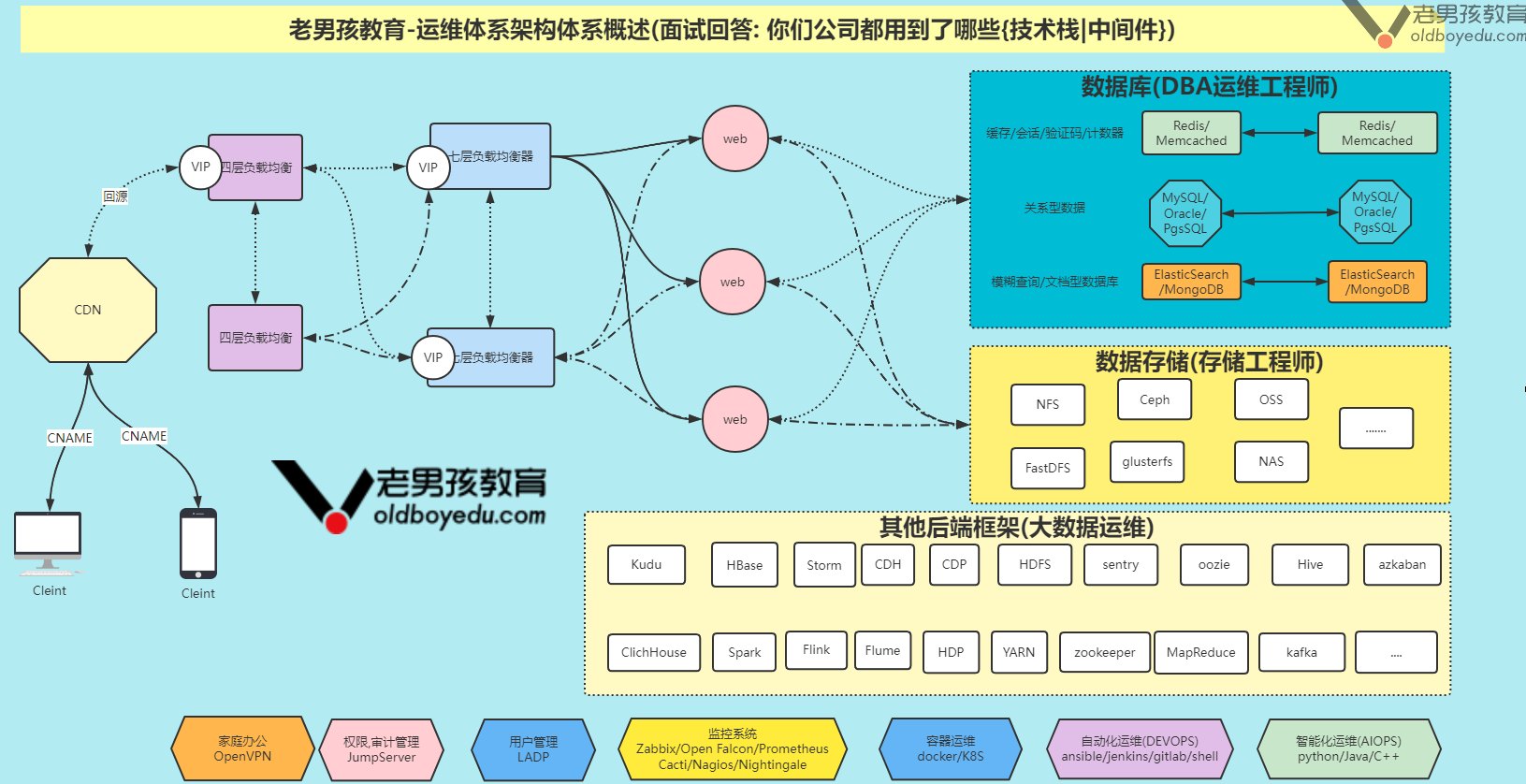
Elastic Stack 分布式⽇志系统概述

集群基础环境初始化
1.准备虚拟机
| IP 地址 | 主机名 | CPU 配置 | 内存配置 | 磁盘配置 | 角色说明 |
|---|---|---|---|---|---|
| 10.0.0.101 | elk101.oldboyedu.com | 2 core | 4G | 20G+ | ES node |
| 10.0.0.102 | elk102.oldboyedu.com | 2 core | 4G | 20G+ | ES node |
| 10.0.0.103 | elk103.oldboyedu.com | 2 core | 4G | 20G+ | ES node |
2.修改软件源
参考链接:https://mirrors.tuna.tsinghua.edu.cn/help/centos/
1 | # 对于 CentOS 7 |
3.修改终端颜色
1 | cat <<EOF >> ~/.bashrc |
4.修改 sshd 服务优化
1 | sed -ri 's@^#UseDNS yes@UseDNS no@g' /etc/ssh/sshd_config |
5.关闭防⽕墙
1 | systemctl disable --now firewalld && systemctl is-enabled firewalld |
6.禁⽤ selinux
1 | sed -ri 's#(SELINUX=)enforcing#\1disabled#' /etc/selinux/config |
7.配置集群免密登录及同步脚本
1 | # 1.修改主机列表 |
8.集群时间同步
1 | # 1.安装常⽤的Linux⼯具,您可以⾃定义哈。 |
Elasticsearch 单点部署
1.下载
https://www.elastic.co/cn/downloads/elasticsearch
2.单点部署 elasticsearch
1 | # 1.安装服务 |
Elasticsearch 分布式集群部署
1.elk101 修改配置文件
1 | egrep -v "^$|^#" /etc/elasticsearch/elasticsearch.yml |
2.同步配置⽂件到集群的其他节点
1 | # 1.elk101同步配置⽂件到集群的其他节点 |
3.所有节点删除之前的临时数据
1 | pkill java |
4.所有节点启动服务
1 | # 1.所有节点启动服务 |
5.验证集群是否正常
1 | curl elk103:9200/_cat/nodes?v |

部署 kibana 服务
1.本地安装 kibana
1 | yum -y localinstall kibana-7.17.3-x86_64.rpm |
2.修改 kibana 的配置⽂件
1 | vim /etc/kibana/kibana.yml |
3.启动 kibana 服务
1 | systemctl enable --now kibana |
4.访问 kibana 的 webUI
略。。。
filebeat 部署及基础使用
1 | $ ./filebeat --help |
1.部署 filebeat 环境
1 | yum -y localinstall filebeat-7.17.3-x86_64.rpm |
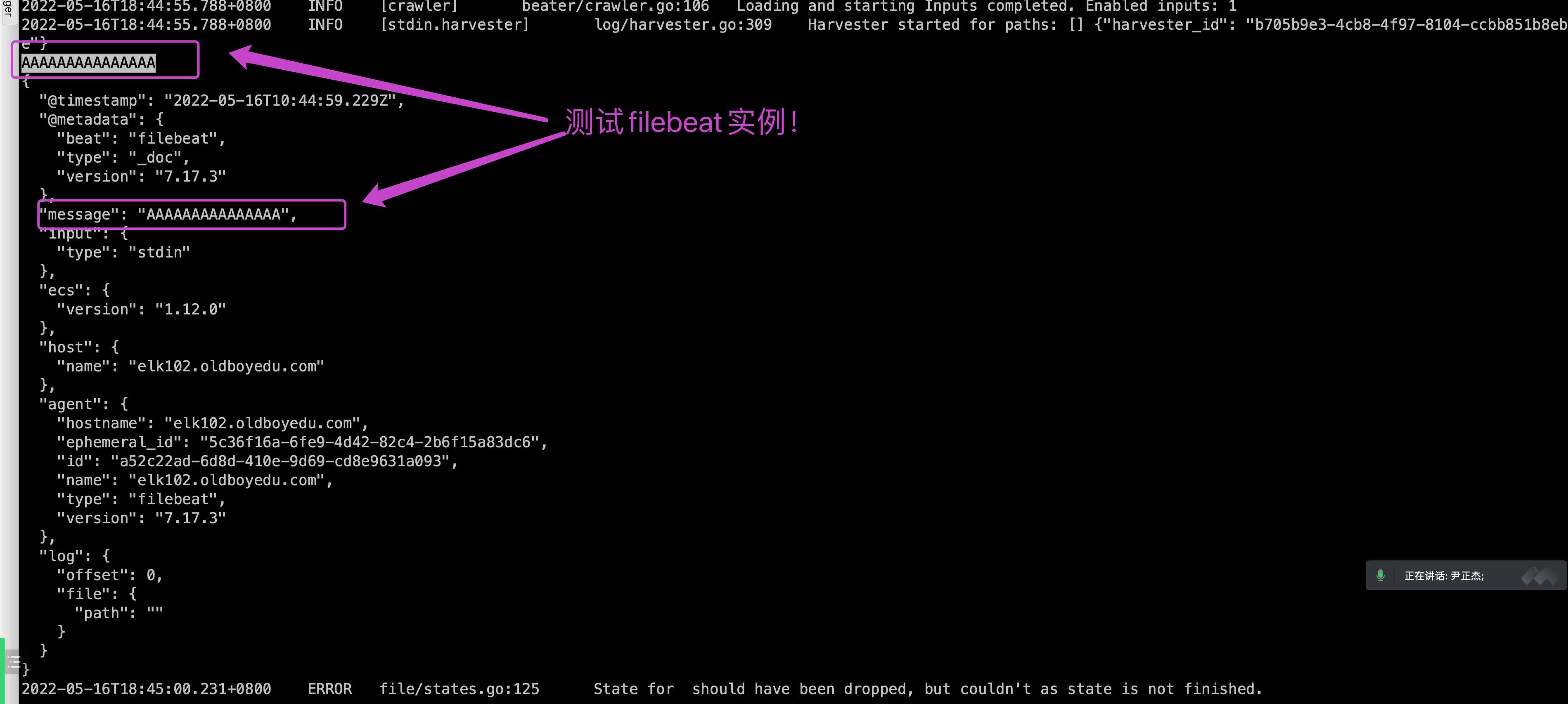
2.简单测试
2.1 编写配置文件
1 | mkdir /etc/filebeat/config |
2.2 运行 filebeat 实例
1 | $ filebeat -e -c /etc/filebeat/config/01-stdin-to-console.yml |
2.3 测试
1 | ... |
3.input 的 log 类型
1 | filebeat.inputs: |
4.input 的通配符案例
1 | filebeat.inputs: |
5.input 的通用字段案例
1 | filebeat.inputs: |
6.日志过滤案例
1 | filebeat.inputs: |
7.将数据写入 es 案例
1 | filebeat.inputs: |
8.自定义 es 索引名称
1 | filebeat.inputs: |
9.多个索引写入案例
1 | filebeat.inputs: |
10.自定义分片和副本案例
1 | filebeat.inputs: |
11.filebeat 实现日志聚合到本地
1 | filebeat.inputs: |
12.filebeat 实现日志聚合到 ES 集群
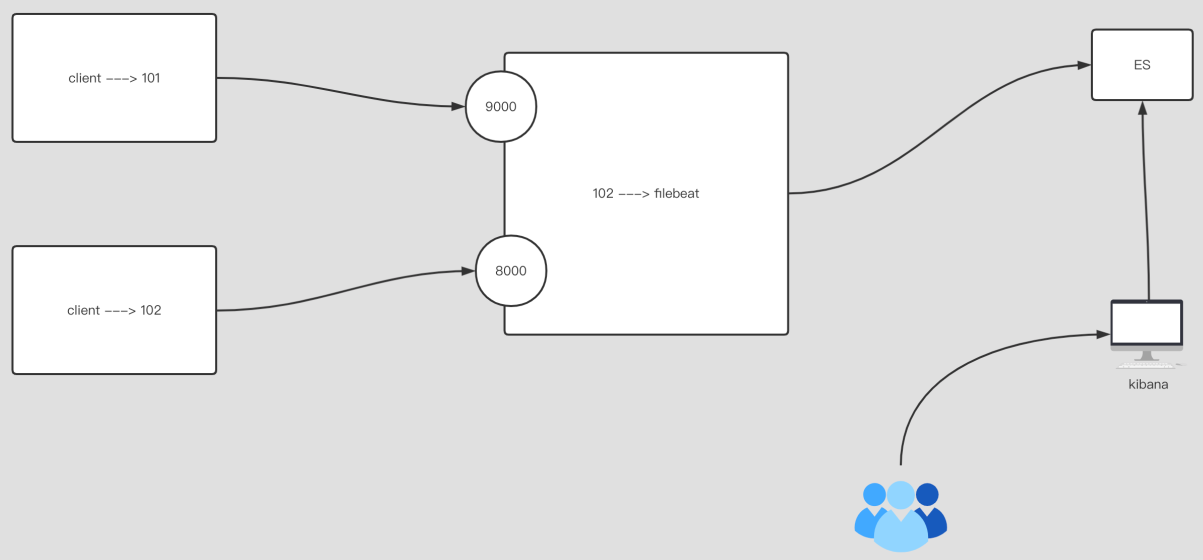
1 | filebeat.inputs: |
EFK 架构企业级实战案例
1.部署 nginx 服务
1 | # 1.配置nginx的软件源 |
2.基于 log 类型收集 nginx 原生日志
1 | filebeat.inputs: |
3.基于 log 类型收集 nginx 的 json 日志
1 | # 1. 修改nginx的源⽇志格式 |
4.基于 modules 采集 nginx 日志文件
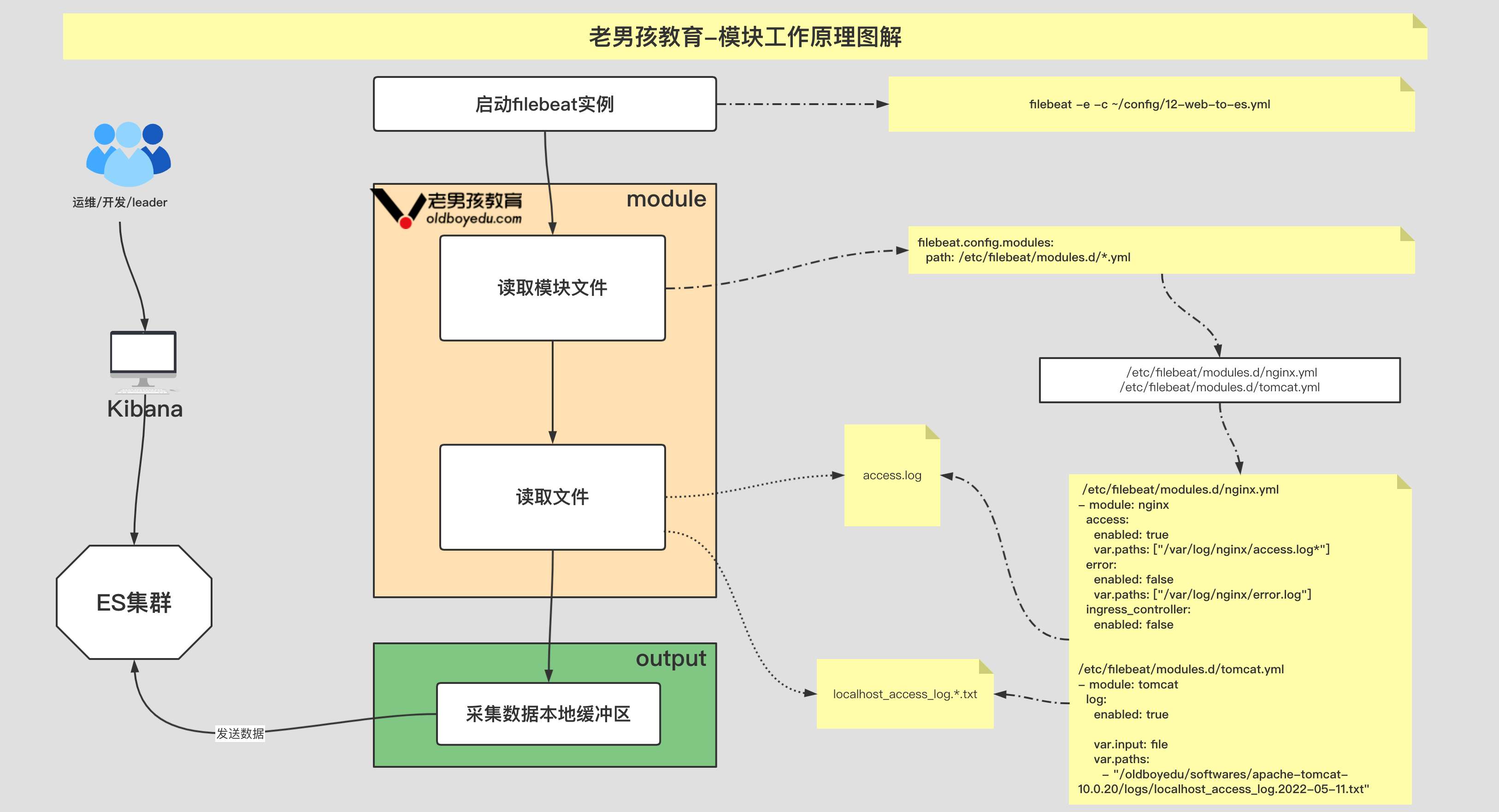
模块的基本使用
1 | # 查看模块 |
filebeat 配置⽂件(需要启⽤ nginx 模块)
1 | filebeat.config.modules: |
/etc/filebeat/modules.d/nginx.yml ⽂件内容:
1 | - module: nginx |
5.基于 modules 采集 tomcat 日志文件
1 | # 1.部署tomcat服务 |
6.基于 log 类型收集 tomcat 的原生日志
1 | filebeat.inputs: |
7.基于 log 类型收集 tomcat 的 json 日志
1 | # 1.⾃定义tomcat的⽇志格式 |
8.多⾏匹配-收集 tomcat 的错误日志
https://www.elastic.co/guide/en/beats/filebeat/current/multiline-examples.html
multiline.match
Specifies how Filebeat combines matching lines into an event. The settings are after or before. The behavior of these settings depends on what you specify for negate:
Setting for negate |
Setting for match |
Result | Example pattern: ^b |
|---|---|---|---|
false |
after |
Consecutive lines that match the pattern are appended to the previous line that doesn’t match. | 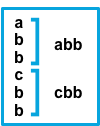 |
false |
before |
Consecutive lines that match the pattern are prepended to the next line that doesn’t match. | 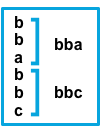 |
true |
after |
Consecutive lines that don’t match the pattern are appended to the previous line that does match. | 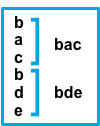 |
true |
before |
Consecutive lines that don’t match the pattern are prepended to the next line that does match. | 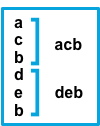 |
The
aftersetting is equivalent topreviousin Logstash, andbeforeis equivalent tonext.
1 | filebeat.inputs: |
9.多⾏匹配-收集 elasticsearch 的错误日志
1 | filebeat.inputs: |
10.nginx 错误日志过滤
1 | filebeat.inputs: |
11.nginx 和 tomcat 同时采集案例
1 | filebeat.inputs: |
12.log 类型切换 filestream 类型注意事项
12.1.filestream 类型 json 解析配置
1 | filebeat.inputs: |
12.2.filestream 类型多行匹配
1 | filebeat.inputs: |
13.收集日志到 redis 服务
13.1.部署 redis
1 | yum -y install epel-release |
13.2.修改配置⽂件
1 | vim /etc/redis.conf |
13.3.启动 redis 服务
1 | systemctl start redis |
13.4.其他节点连接测试 redis 环境
1 | redis-cli -a oldboyedu -h 10.0.0.101 -p 6379 --raw -n 5 |
13.5.将 filebeat 数据写入到 redis 环境
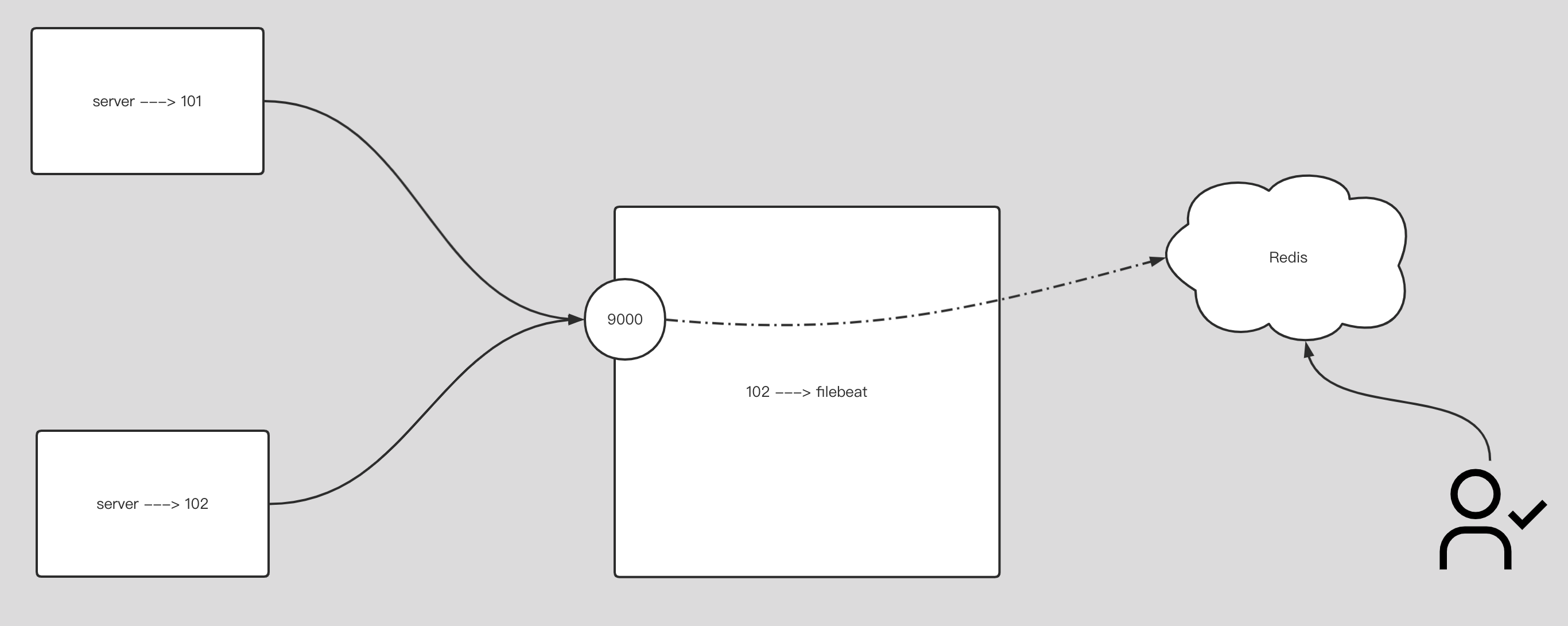
1 | filebeat.inputs: |
13.6.测试写入数据
1 | # 写⼊数据: |
14.今日作业
1 | # 1. 完成课堂的所有练习; |
⽅案⼀:filebeat 多实例
filebeat 实例⼀:
1 | filebeat.inputs: |
filebeat 实例二:
1 | filebeat.inputs: |
方案二:基于 rsyslog 案例
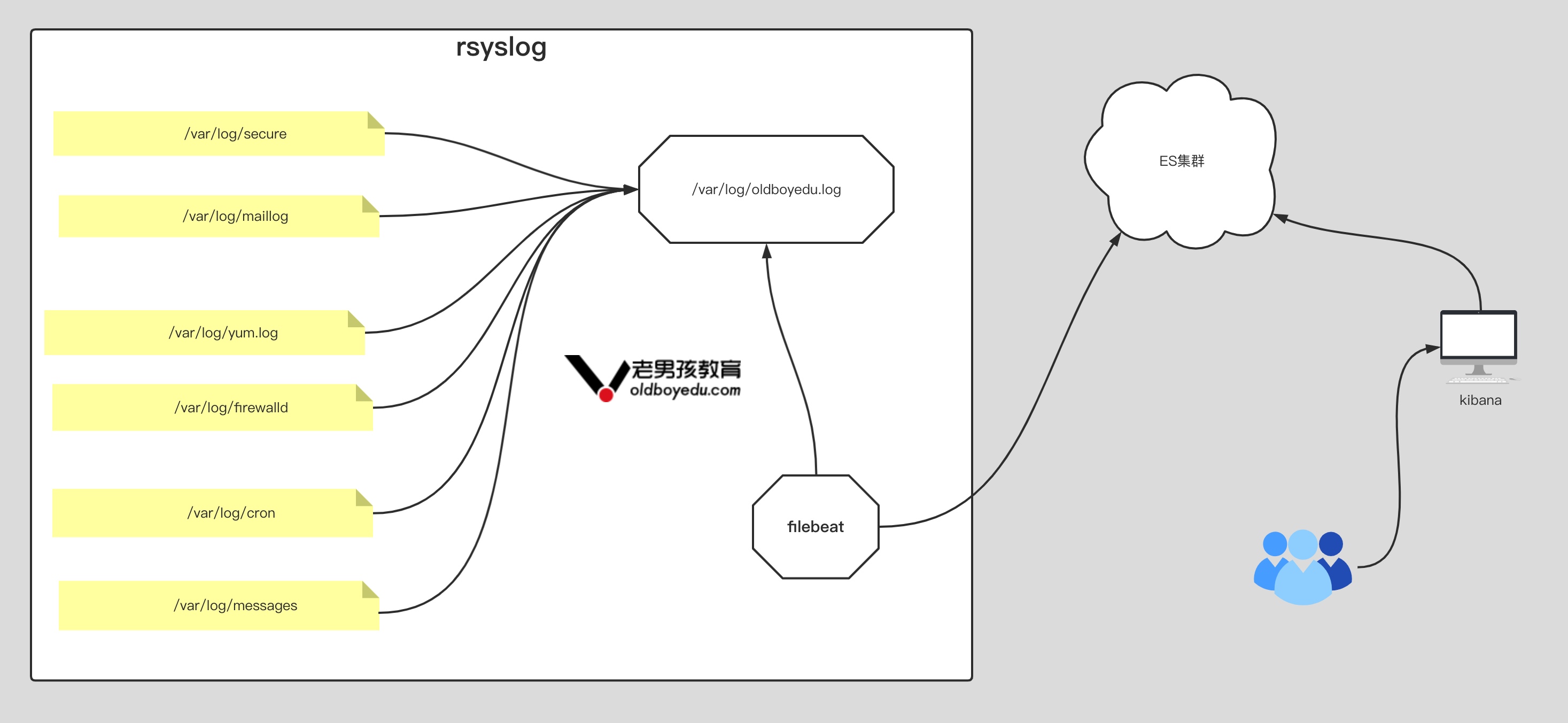
1 | filebeat.inputs: |
部署 logstash 环境及基础使用
1.部署 logstash 环境
1 | yum -y localinstall logstash-7.17.3-x86_64.rpm |
2.修改 logstash 的配置⽂件
1 | # (1)编写配置⽂件 |
3.input 插件基于 file 案例
1 | input { |
4.input 插件基于 tcp 案例
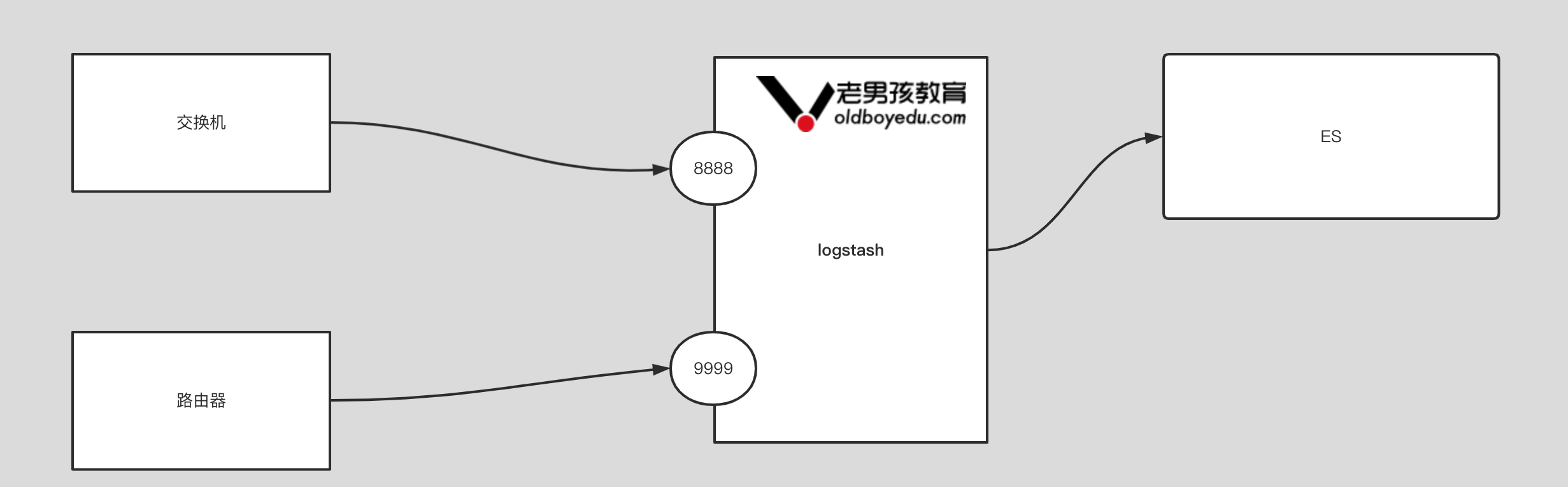
1 | input { |
5.input 插件基于 http 案例
1 | input { |
6.input 插件基于 redis 案例
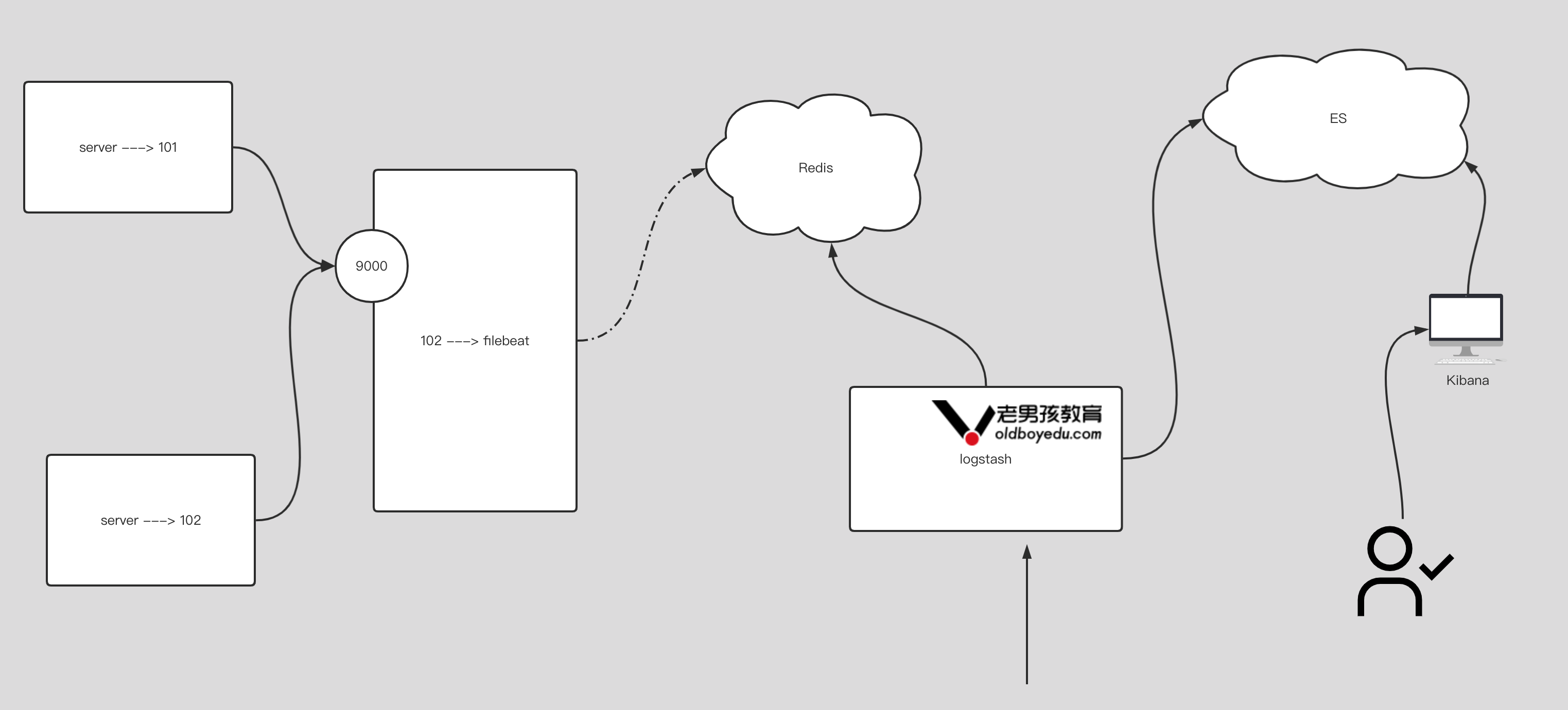
1 | # filebeat的配置:(仅供参考) |
7.input 插件基于 beats 案例
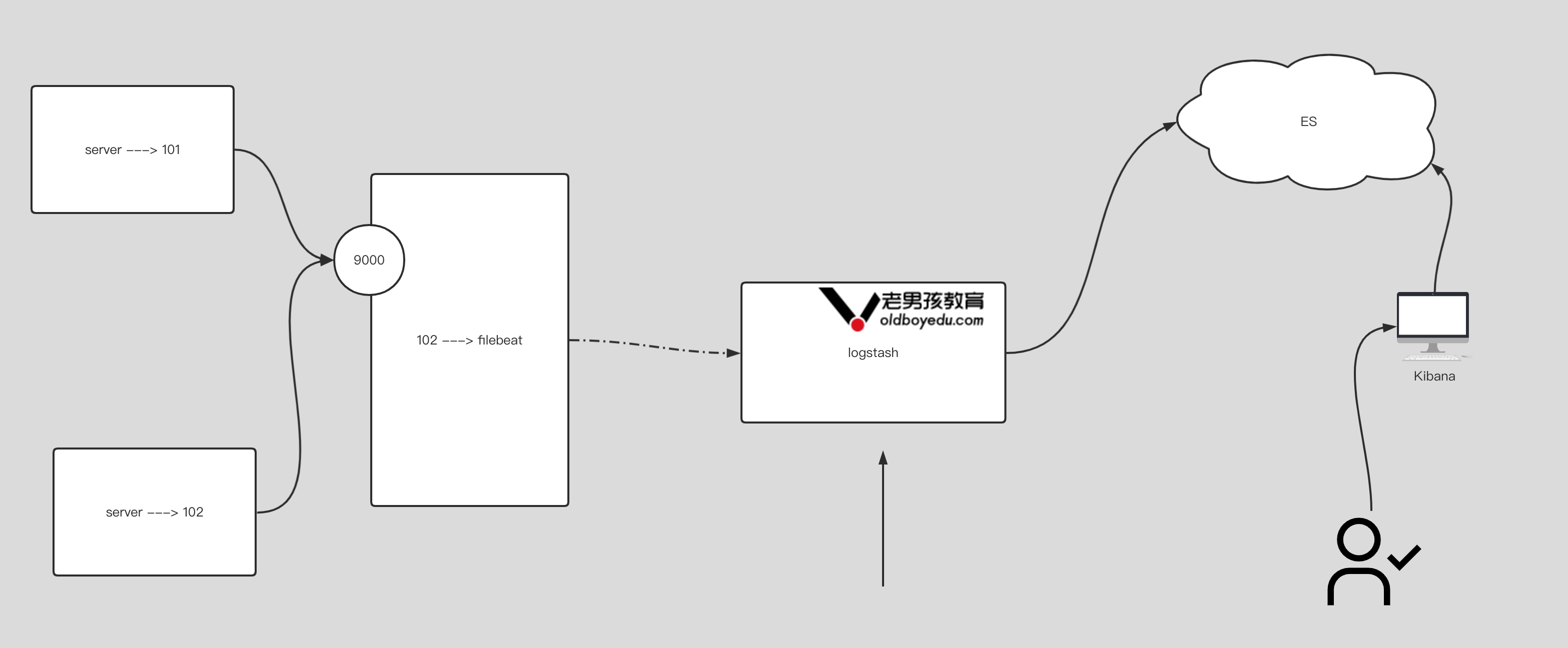
1 | # filbeat配置: |
8.output 插件基于 redis 案例

1 | input { |
9.output 插件基于 file 案例
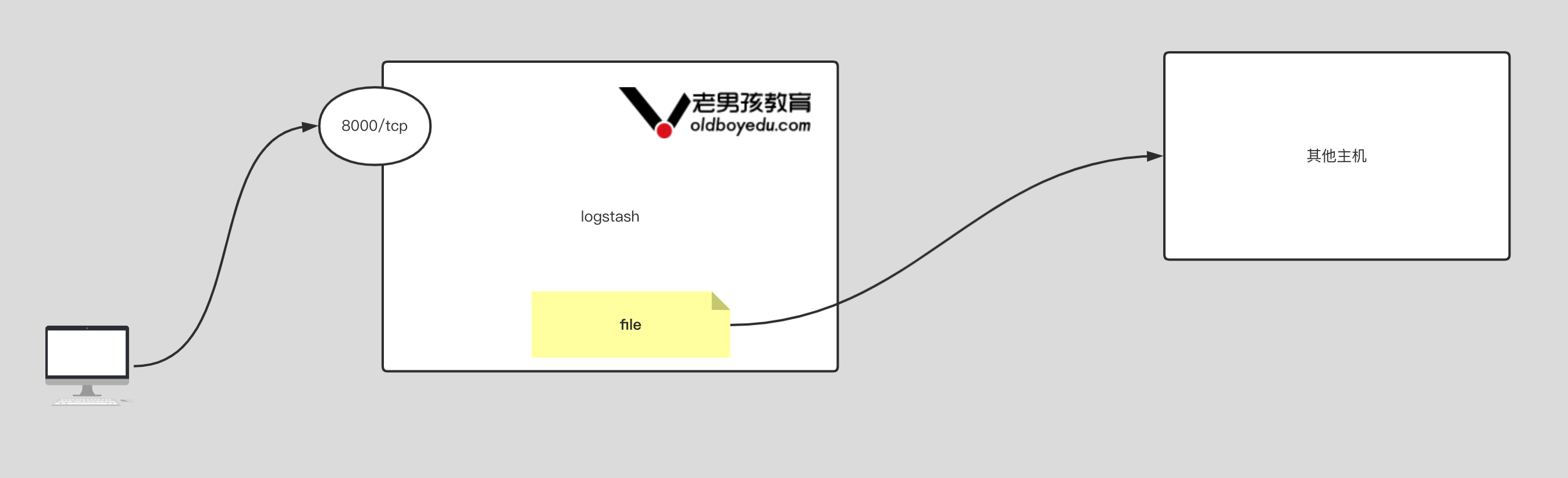
1 | input { |
10.logstash 综合案例
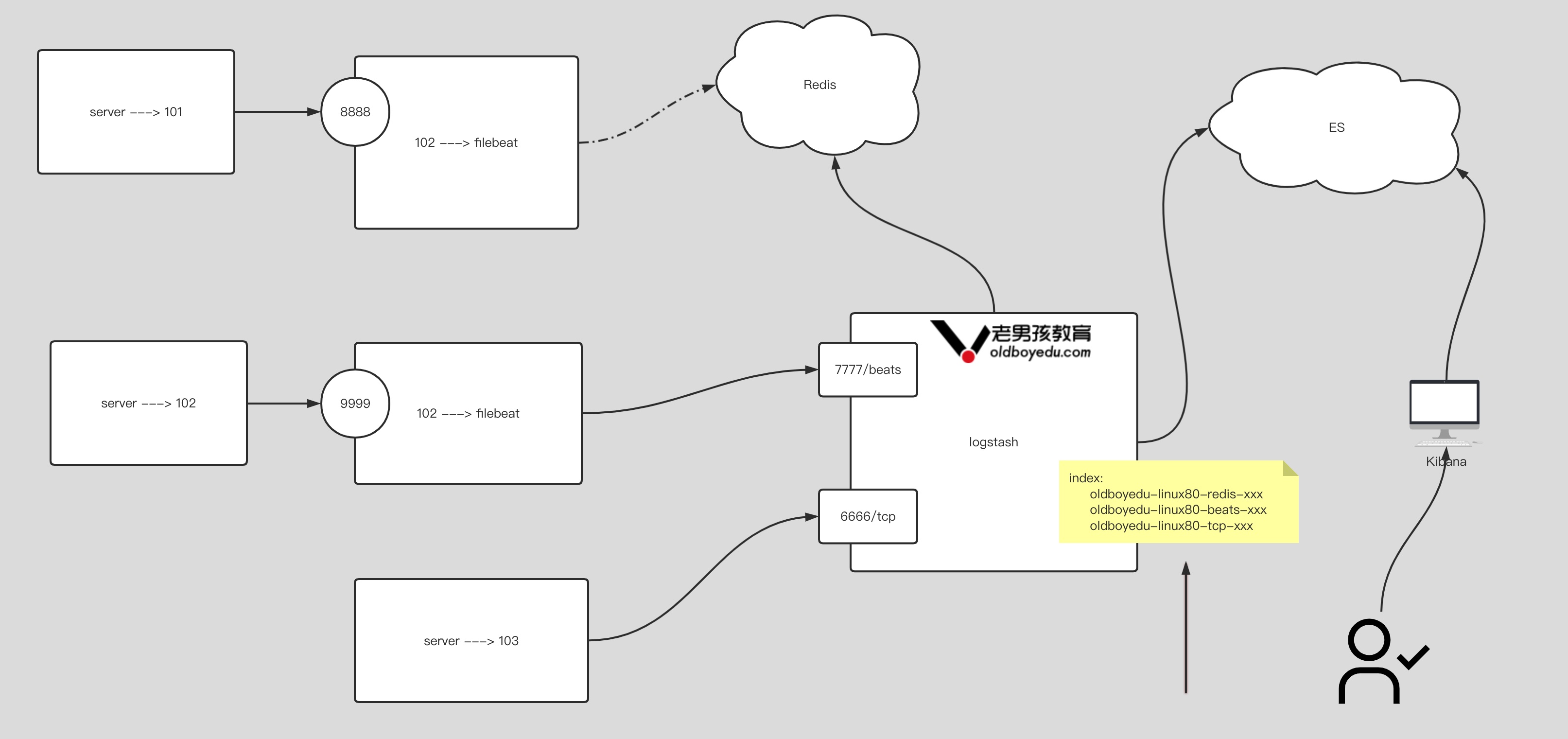
1.filebeat-to-redis 参考笔记
1 | filebeat.inputs: |
2.filebeat-to-logstash 参考笔记
1 | filebeat.inputs: |
3.logstash 配置⽂件
1 | input { |
11.今日作业
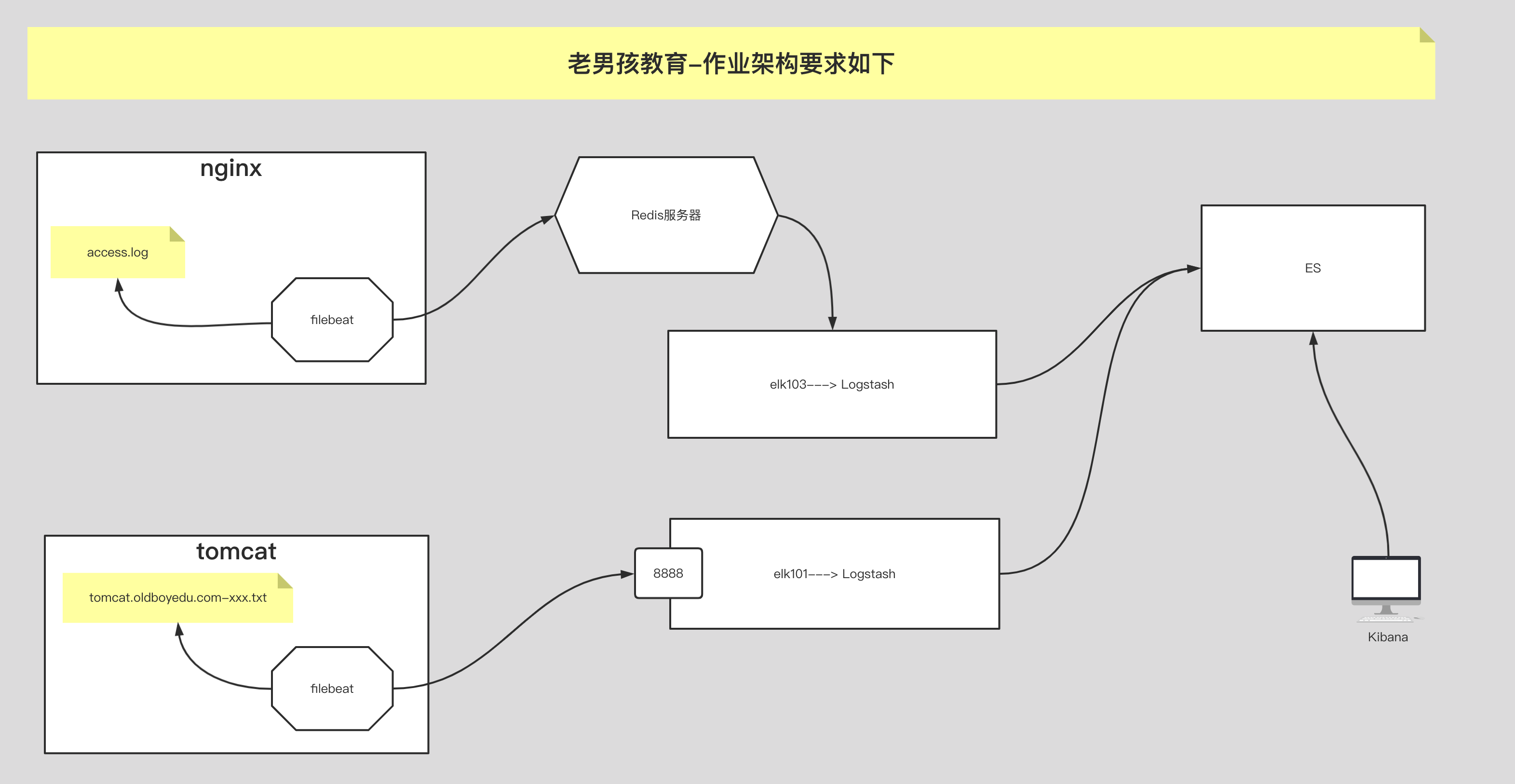
1 | (1)完成课堂的所有练习,要求能够⼿绘架构图; |
11.1 运行一个 logsash 版本
1 | [root@elk101.oldboyedu.com ~]$ cat config-logstash/11-many-to-es.conf |
11.2.运行两个 logstash 版本
1 | # logstash接受redis示例: |
logstash 企业级插件案例(ELFK 架构)
1.gork 插件概述
Grok 是将⾮结构化⽇志数据解析为结构化和可查询的好⽅法。底层原理是基于正则匹配任意⽂本格式。
该⼯具⾮常适合 syslog ⽇志、apache 和其他⽹络服务器⽇志、mysql ⽇志,以及通常为⼈类⽽⾮计算机消耗⽽编写的任何⽇志格式。
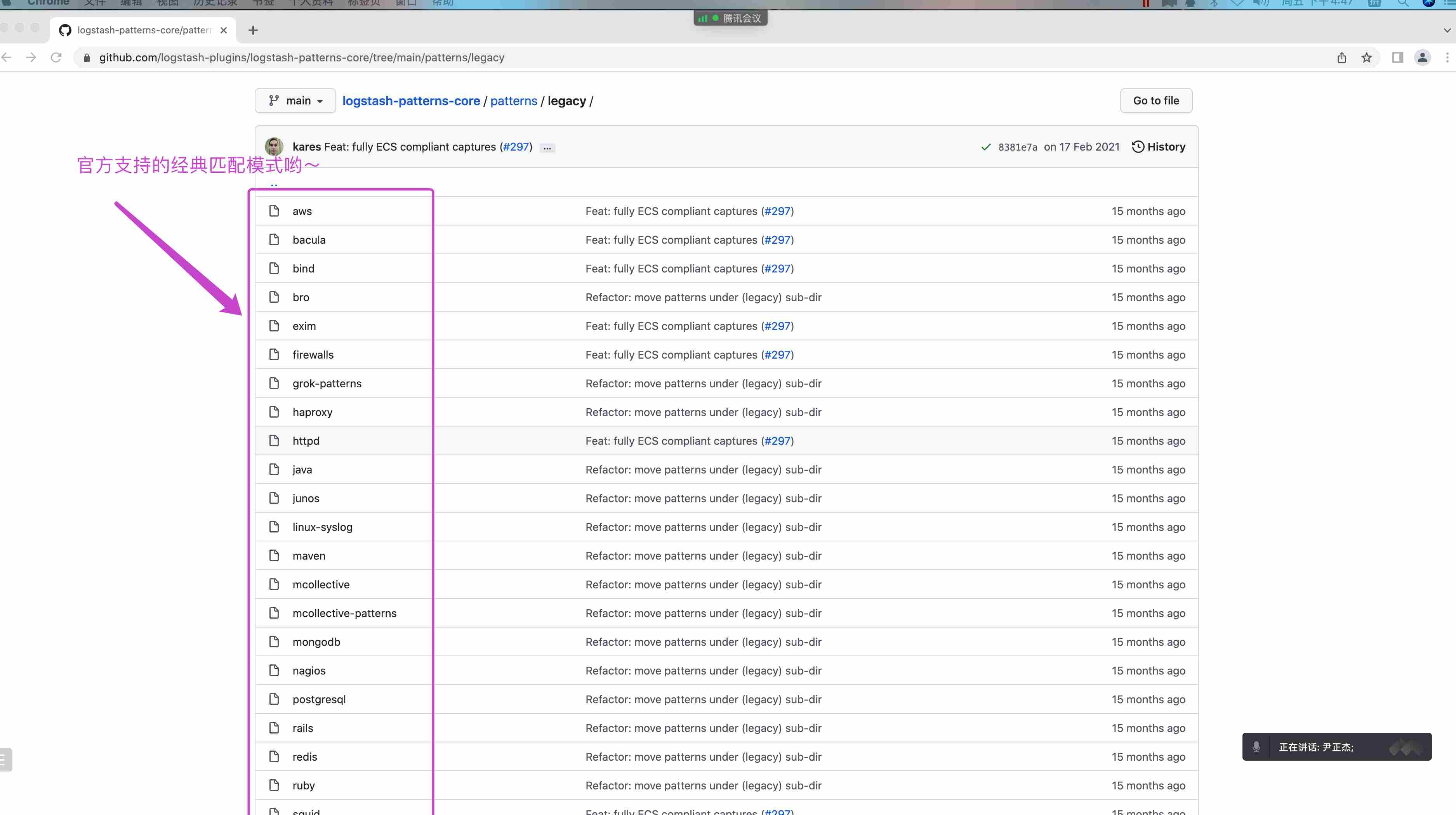
内置 120 种匹配模式,当然也可以⾃定义匹配模式:
https://github.com/logstash-plugins/logstash-patterns-core/tree/master/patterns
2.使⽤ grok 内置的正则案例 1
1 | [root@elk101.oldboyedu.com ~]$ cat config-logstash/14-beat-grok-es.conf |
3.使用 grok 内置的正则案例 2
1 | [root@elk101.oldboyedu.com ~]$ cat config-logstash/15-stdin-grok-stdout.conf |
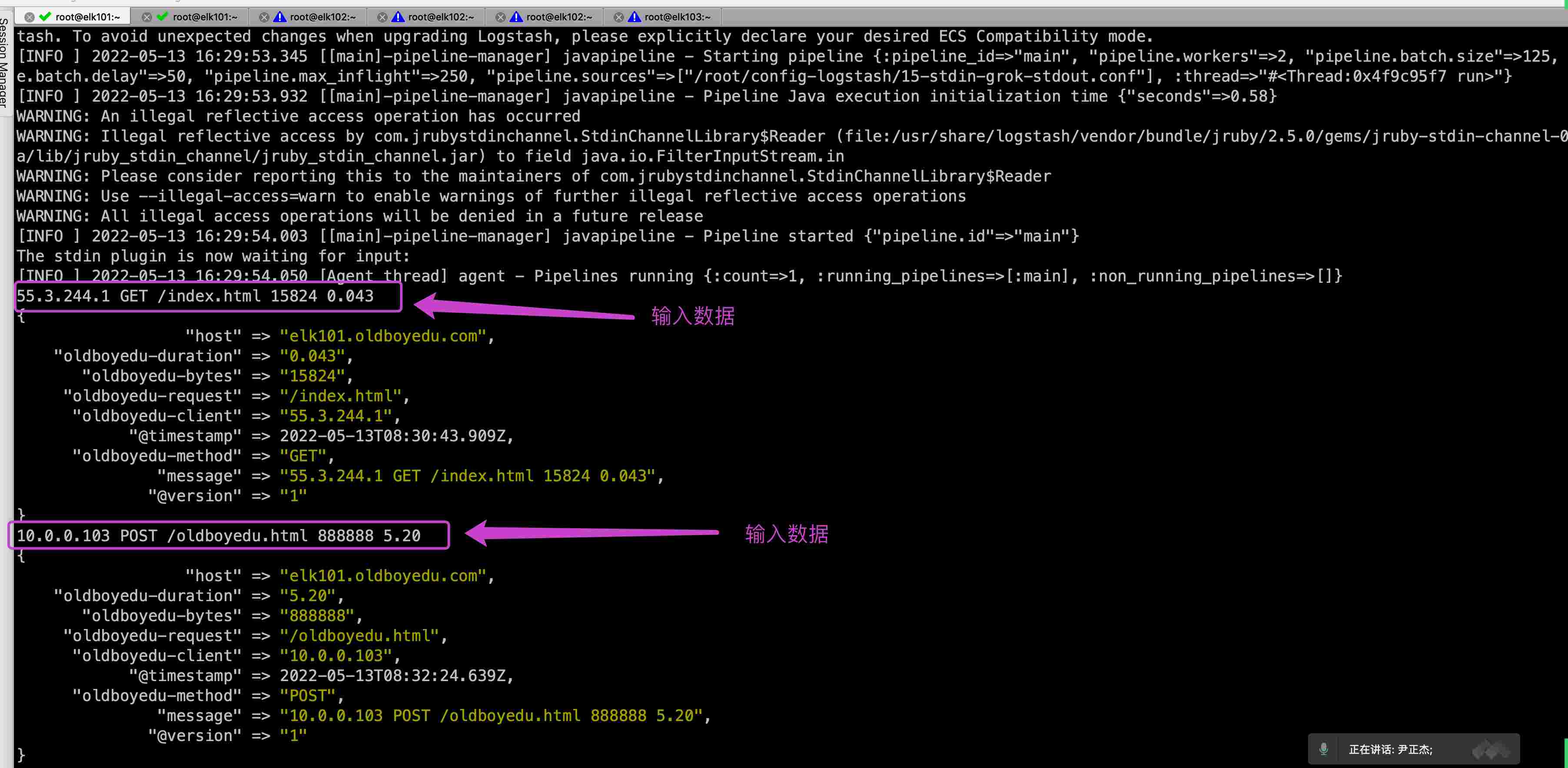
4.使用 grop 自定义的正则案例
1 | [root@elk101.oldboyedu.com ~]$ cat config-logstash/16-stdin-grok_custom_patterns-stdout.conf |
5.filter 插件通用字段案例
1 | [root@elk101.oldboyedu.com ~]$ cat config-logstash/17-beat-grok-es.conf |
6.date 插件修改写入 ES 的时间
1 | [root@elk101.oldboyedu.com ~]$ cat config-logstash/18-beat-grok_date-es.conf |
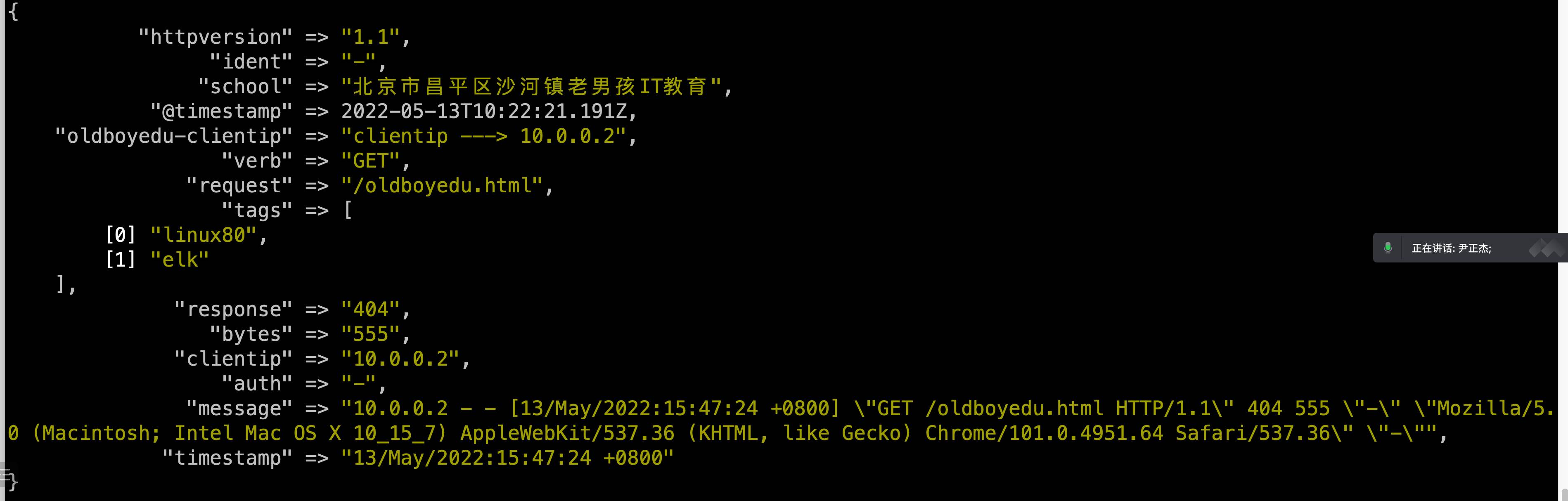
7.geoip 分析源地址的地址位置
1 | [root@elk101.oldboyedu.com ~]$ cat config-logstash/19-beat-grok_date_geoip-es.conf |
8.useragent 分析客户端的设备类型
1 | [root@elk101.oldboyedu.com ~]# cat config-logstash/20-beat-grok_date_geoip_useragent-es.conf |
9.mutate 组件数据准备-python 脚本
1 | cat > generate_log.py <<EOF |
9.mutate 组件常⽤字段案例

1 | [root@elk101.oldboyedu.com ~]# cat config-logstash/21-mutate.conf |
10.logstash 的多 if 分支案例
1 | [root@elk101.oldboyedu.com ~]# cat config-logstash/22-beats_tcp-filter-es.conf |
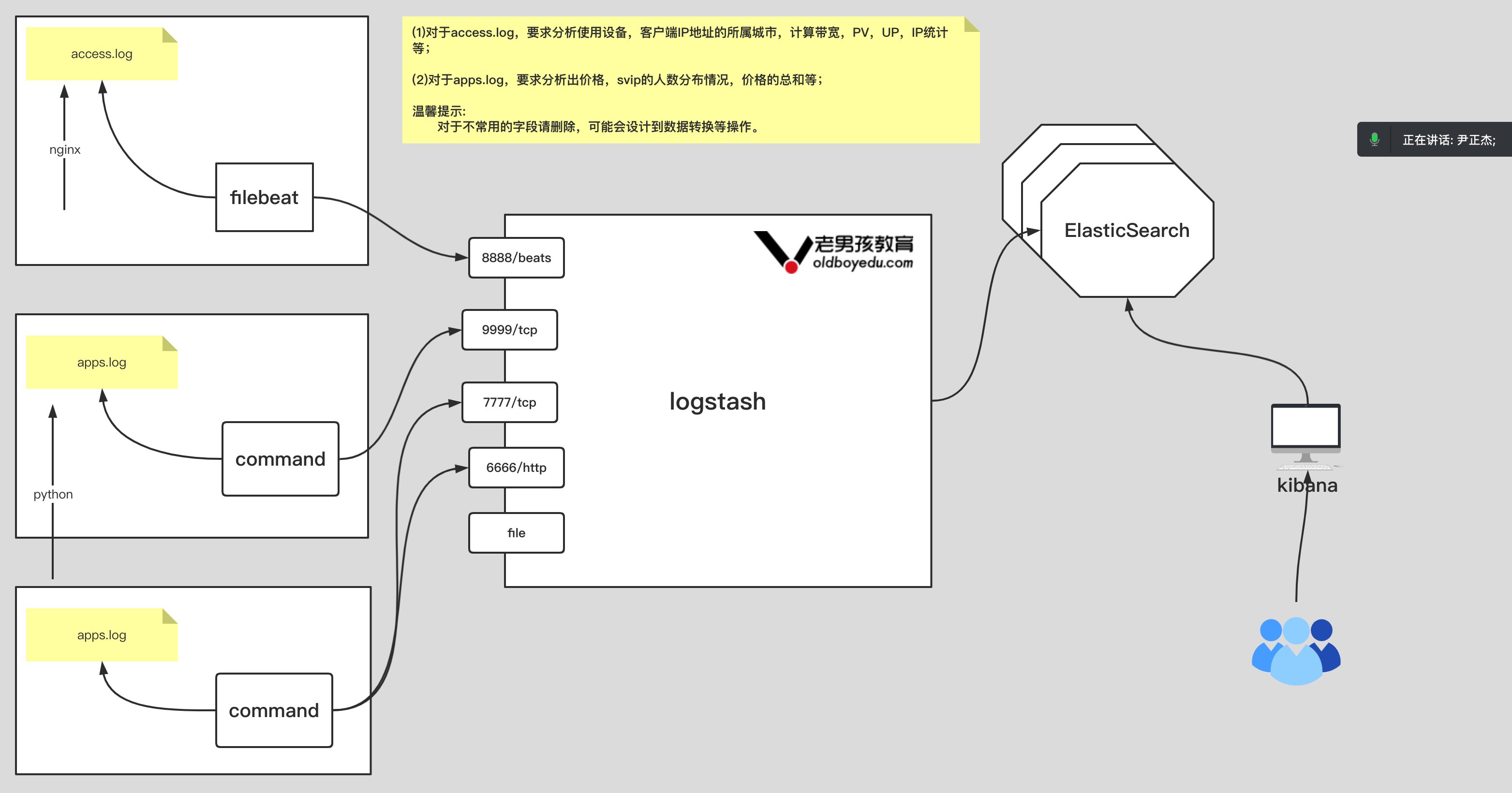
11.今日作业
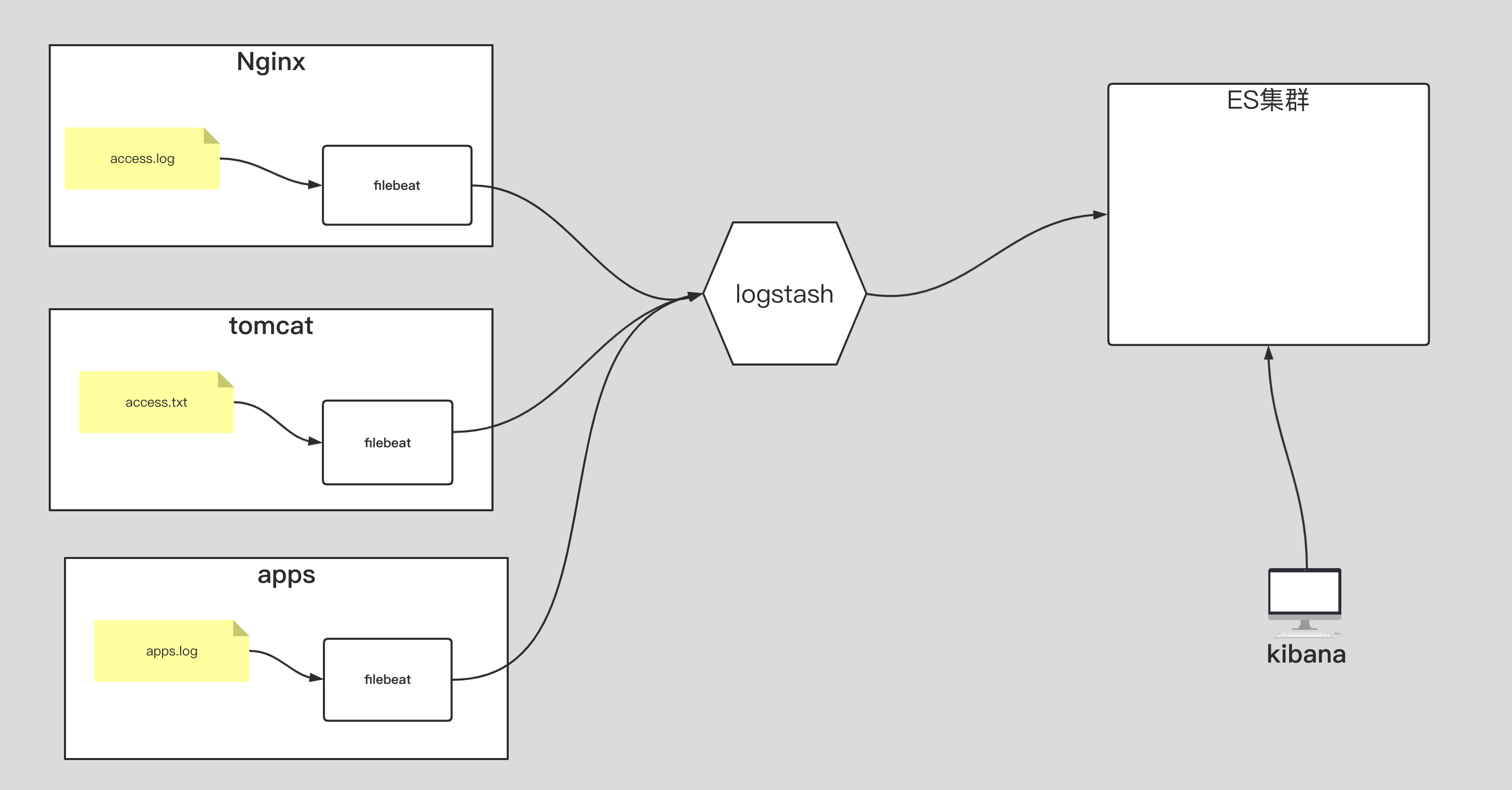
1 | 如上图所示,要求完成以下内容: |
filebeat 手机 tomcat 日志
1 | [root@elk102.oldboyedu.com ~]# cat ~/config/38-tomcat-to-logstash.yml |
filebeat 收集 nginx 日志
1 | [root@elk102.oldboyedu.com ~]# cat ~/config/37-nginx-to-logstash.yml |
filebeat 收集 apps 日志
1 | [root@elk102.oldboyedu.com ~]# cat ~/config/39-apps-to-logstash.yml |
logstash 收集 nginx 日志
1 | [root@elk101.oldboyedu.com ~]# cat config-logstash/24-homework-01-to-es.conf |
logstash 收集 tomcat 日志
1 | [root@elk101.oldboyedu.com ~]# cat config-logstash/24-homework-02-to-es.conf |
logstash 收集 apps 日志
1 | [root@elk101.oldboyedu.com ~]# cat config-logstash/24-homework-03-to-es.conf |
kibana 自定义 dashboard 实战案例
1.统计 pv(指标)
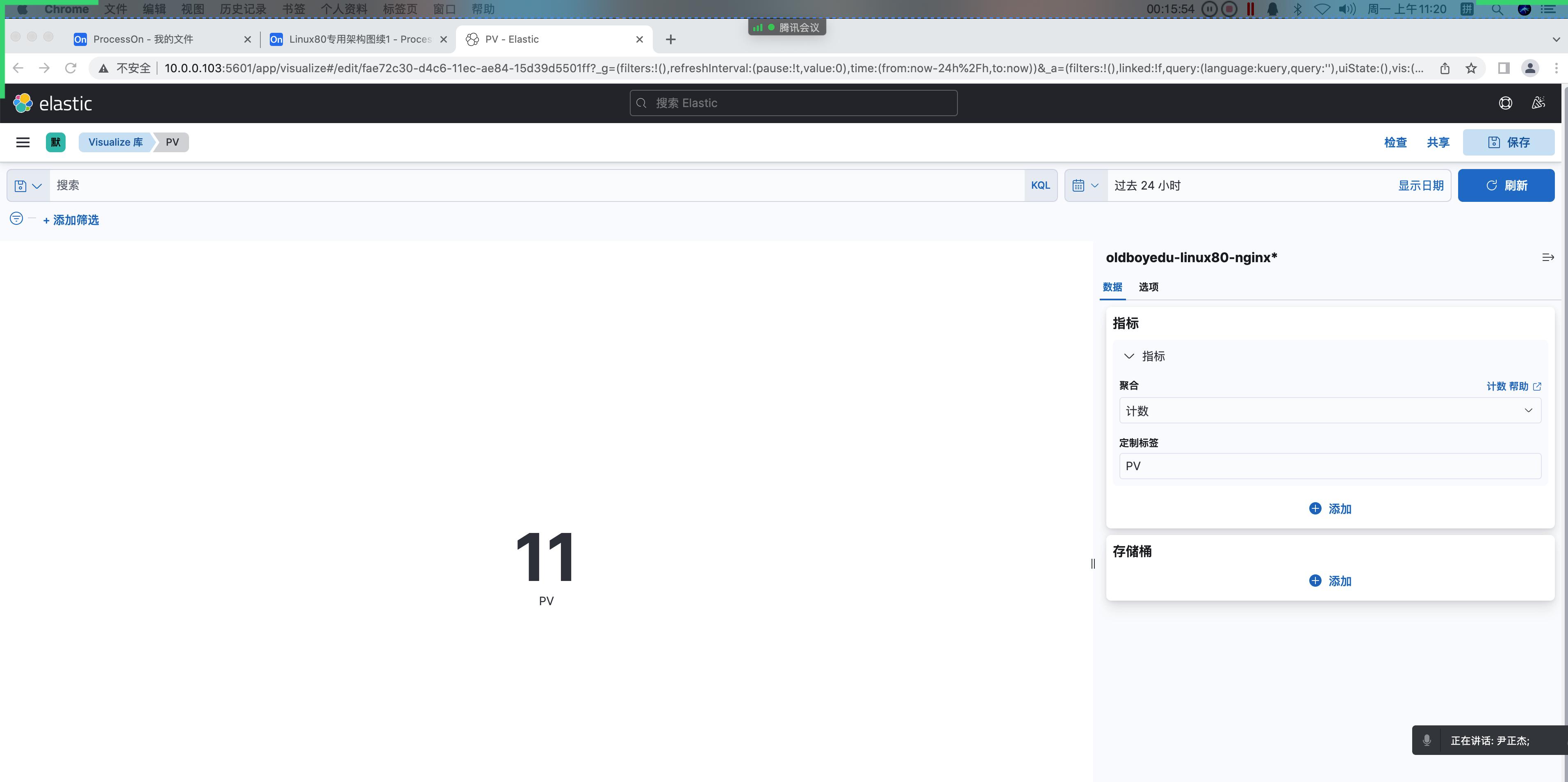
1 | Page View(简称:"PV") |
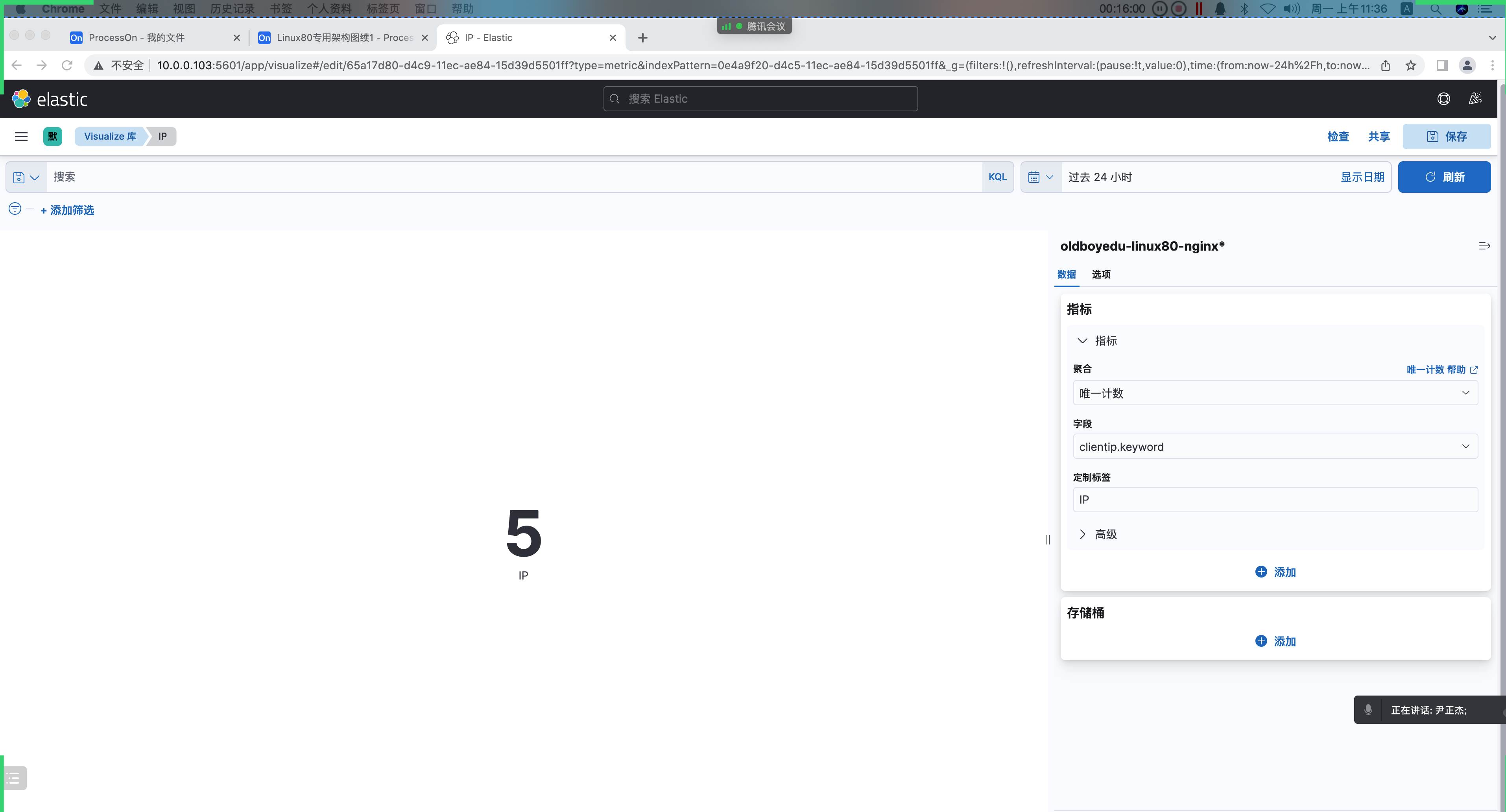
2.统计客户端 IP(指标)
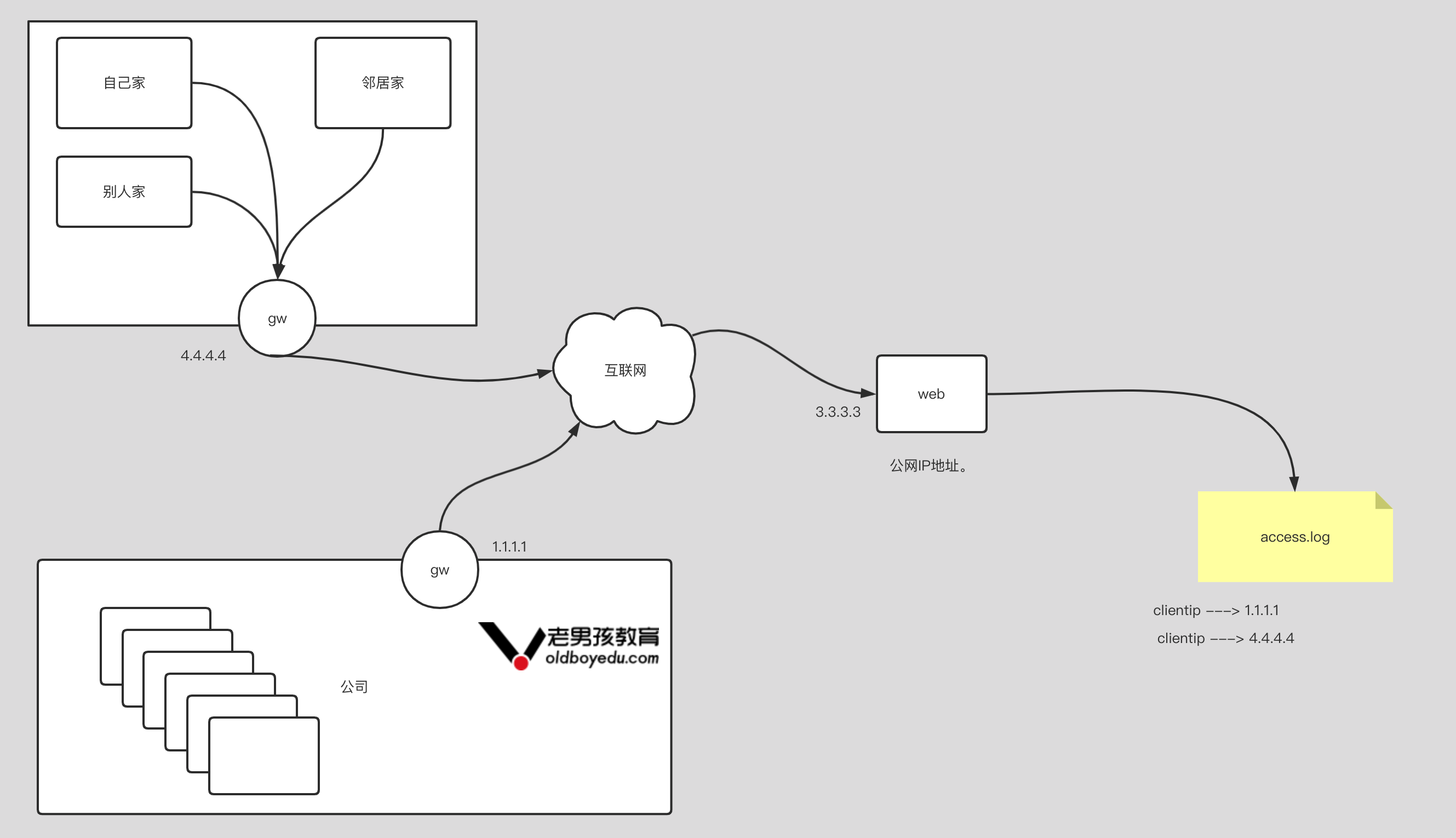
1 | 客户端IP: |
3.统计 web 下载带宽(指标)
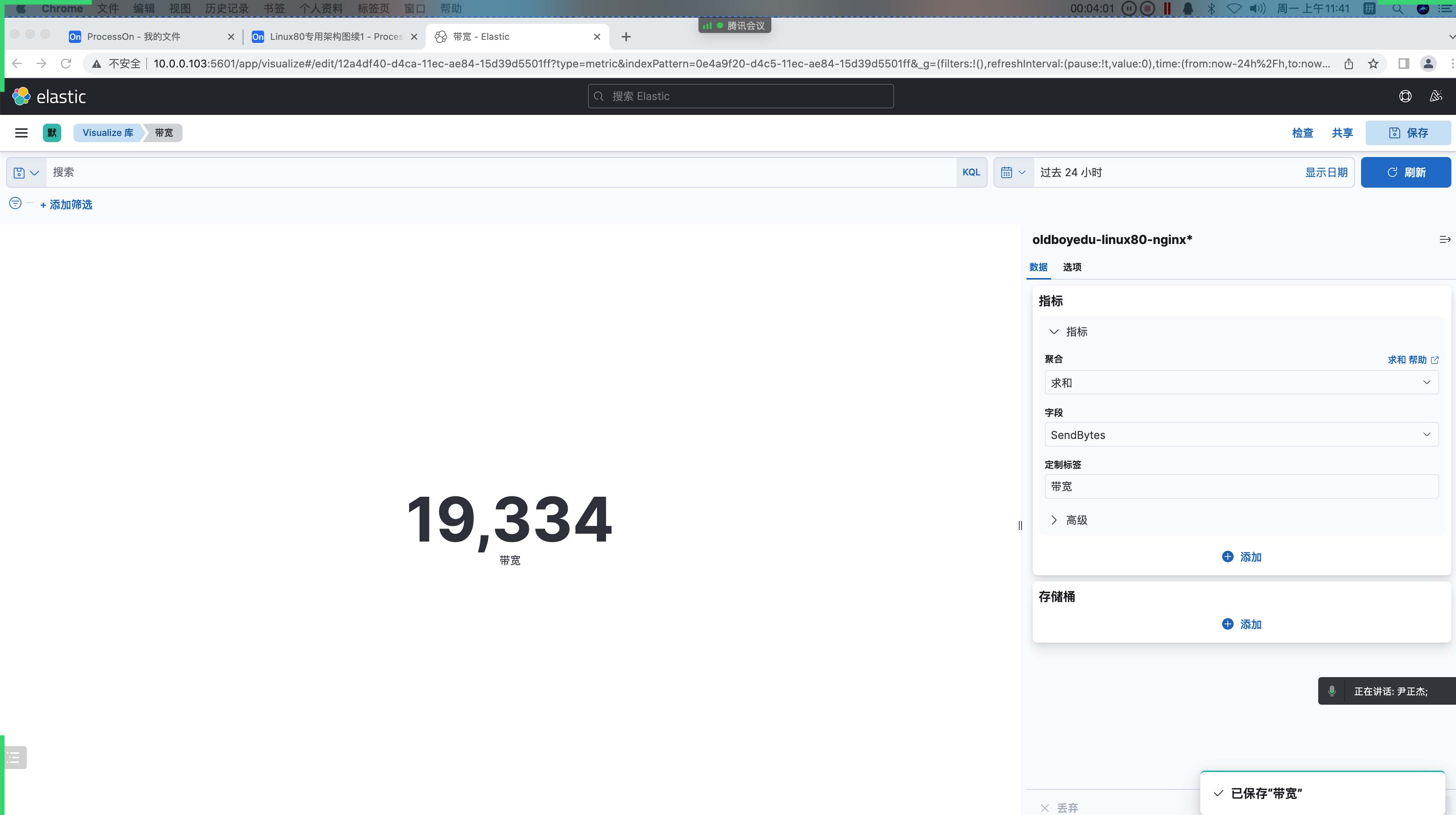
1 | 带宽: |
4.访问页面统计(水平条形图)
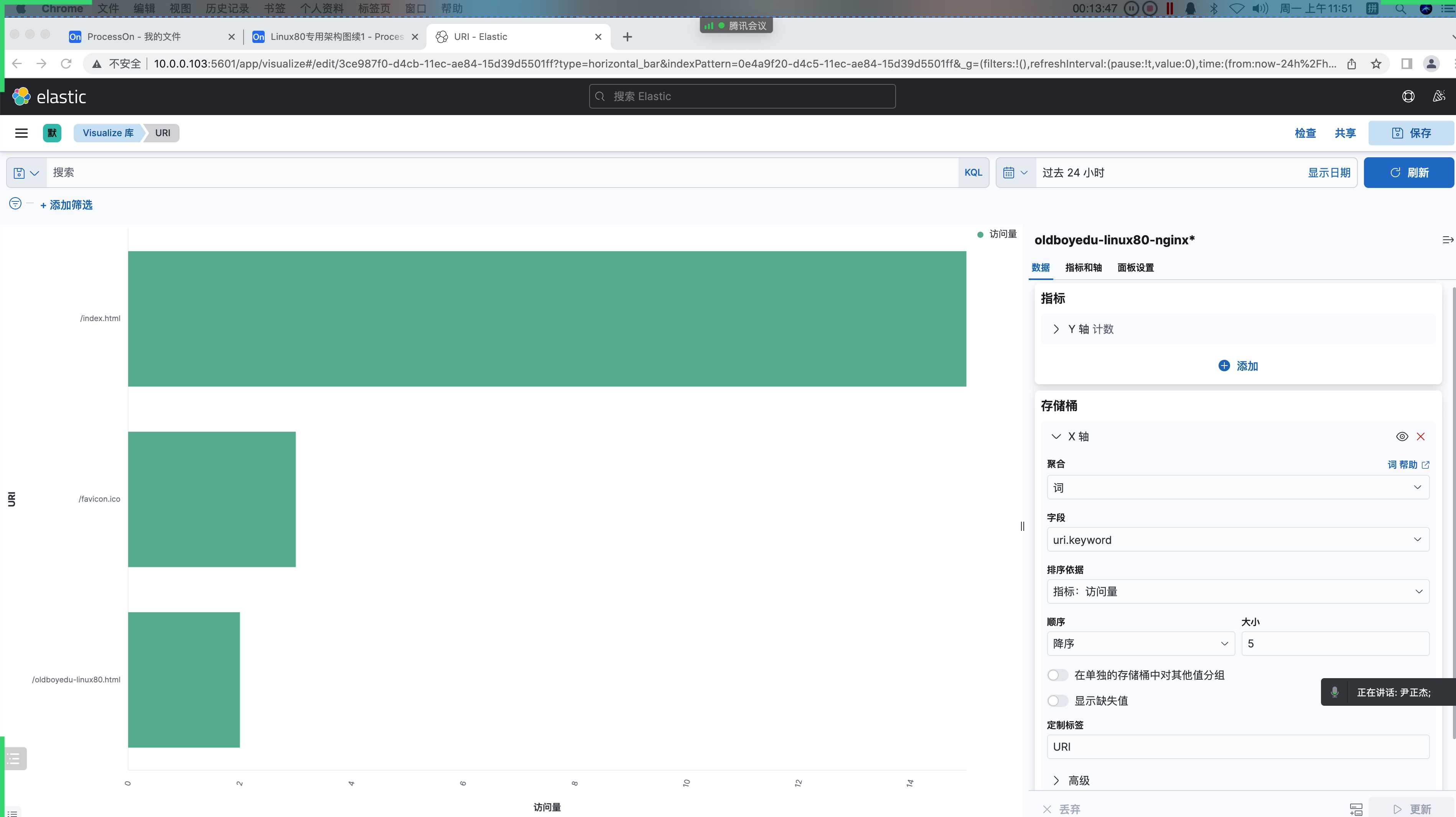
1 | 访问资源统计: |
5.分析客户端的城市分布(垂直条形图)
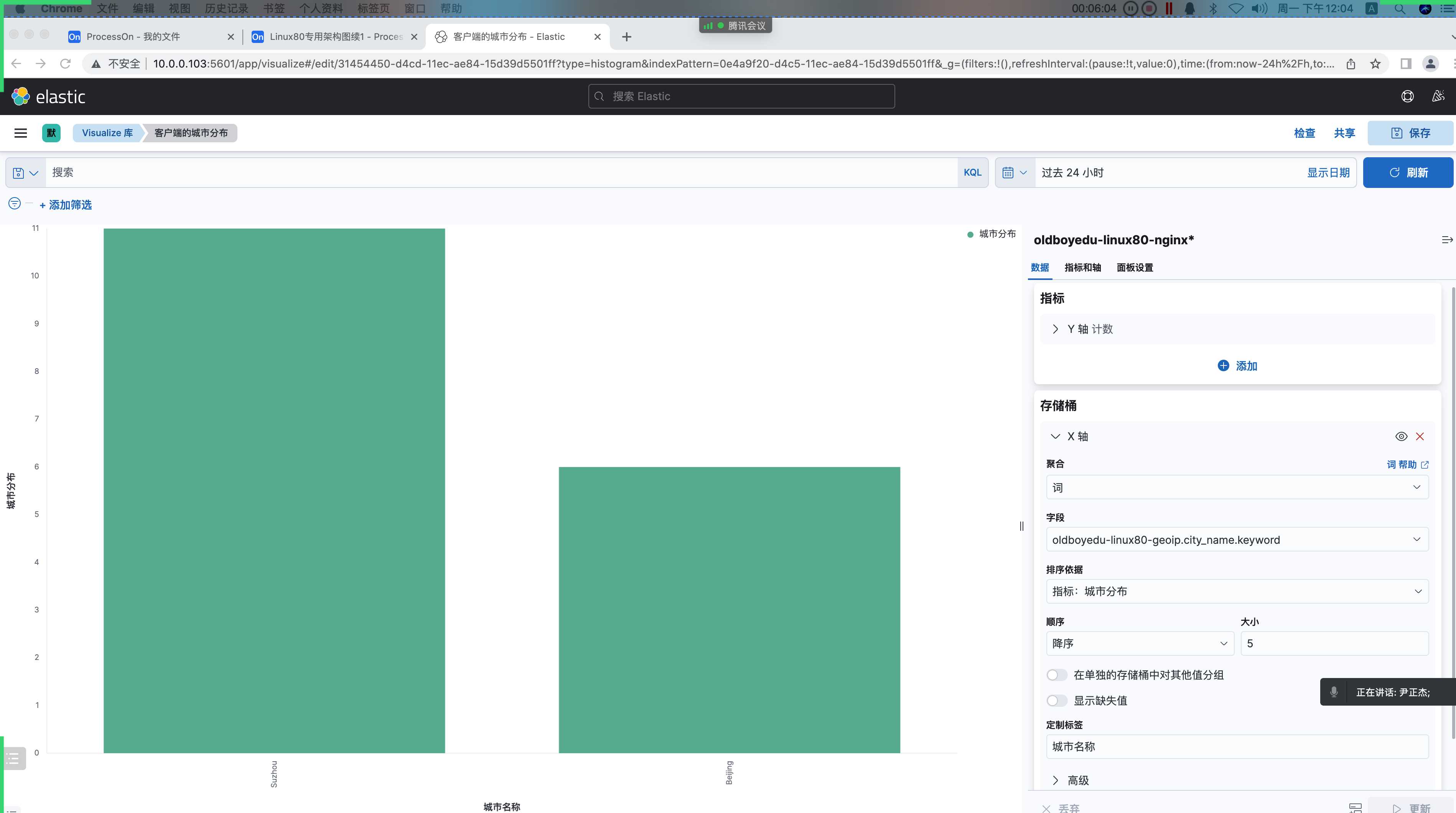
1 | 分析客户端的城市分布: |
6.城市分布百分比(饼图)
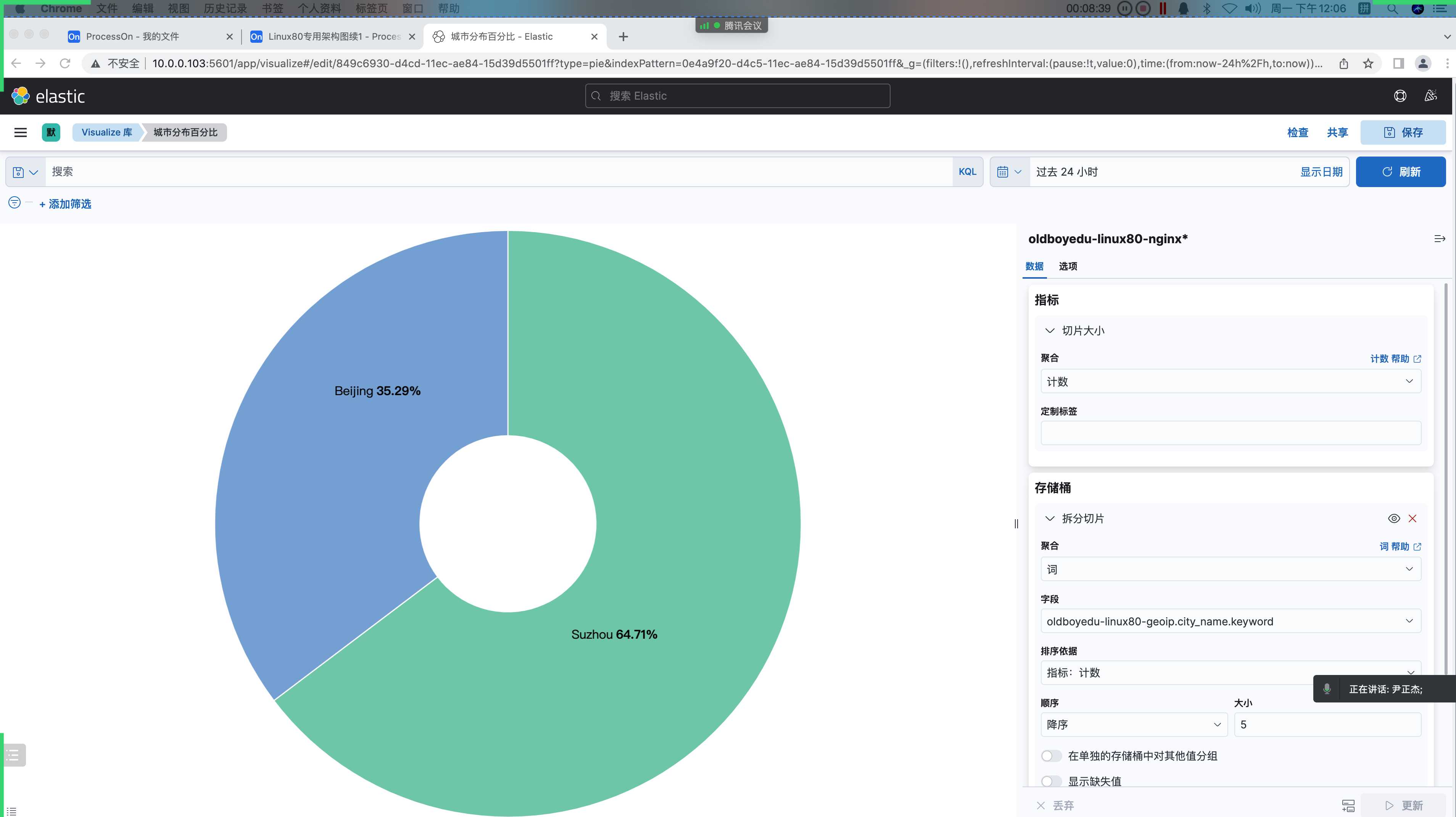
1 | 分析客户端的城市分布: |
7.IP 的 TopN 统计(仪表盘)
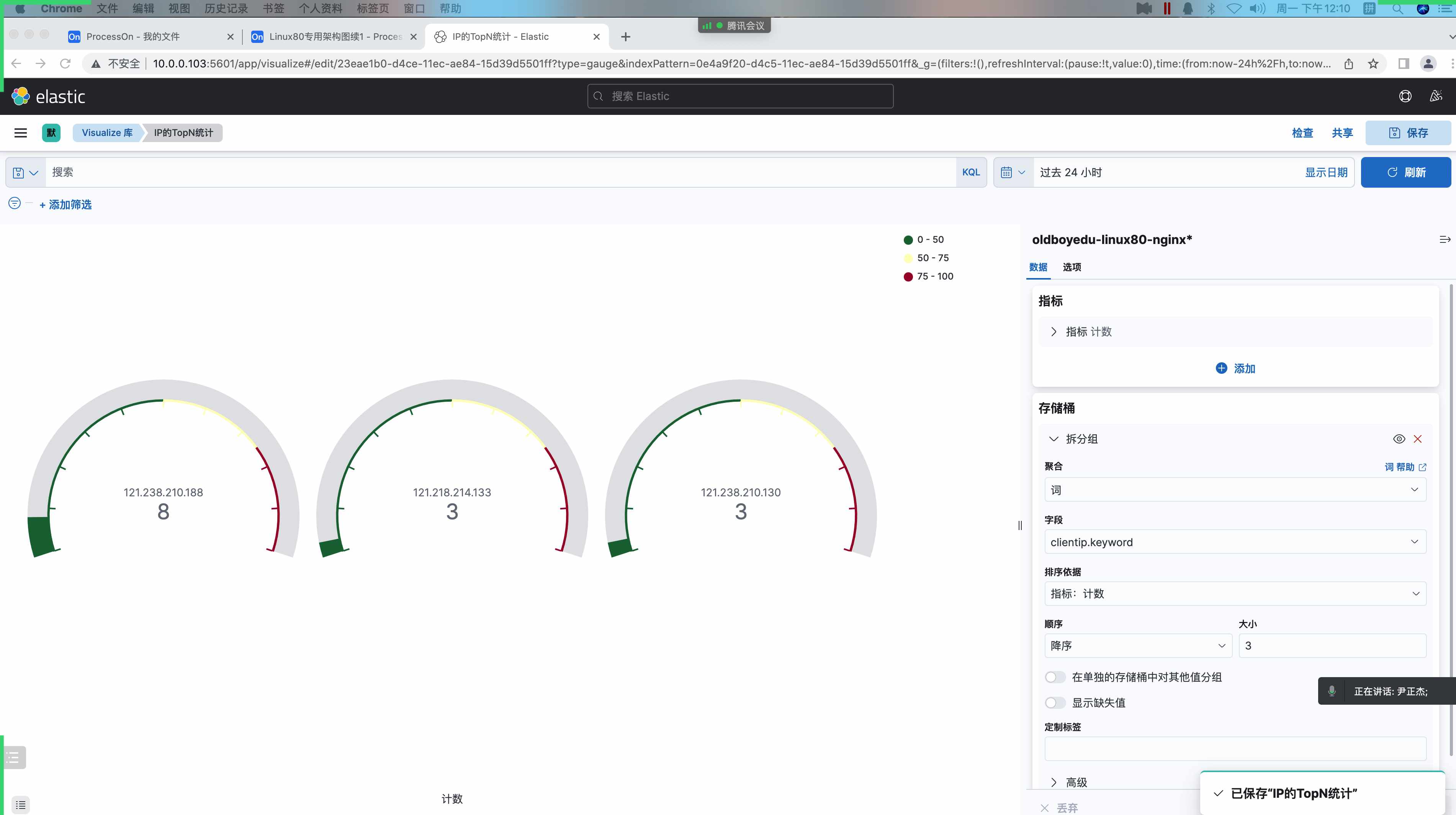
1 | IP的TopN统计: |
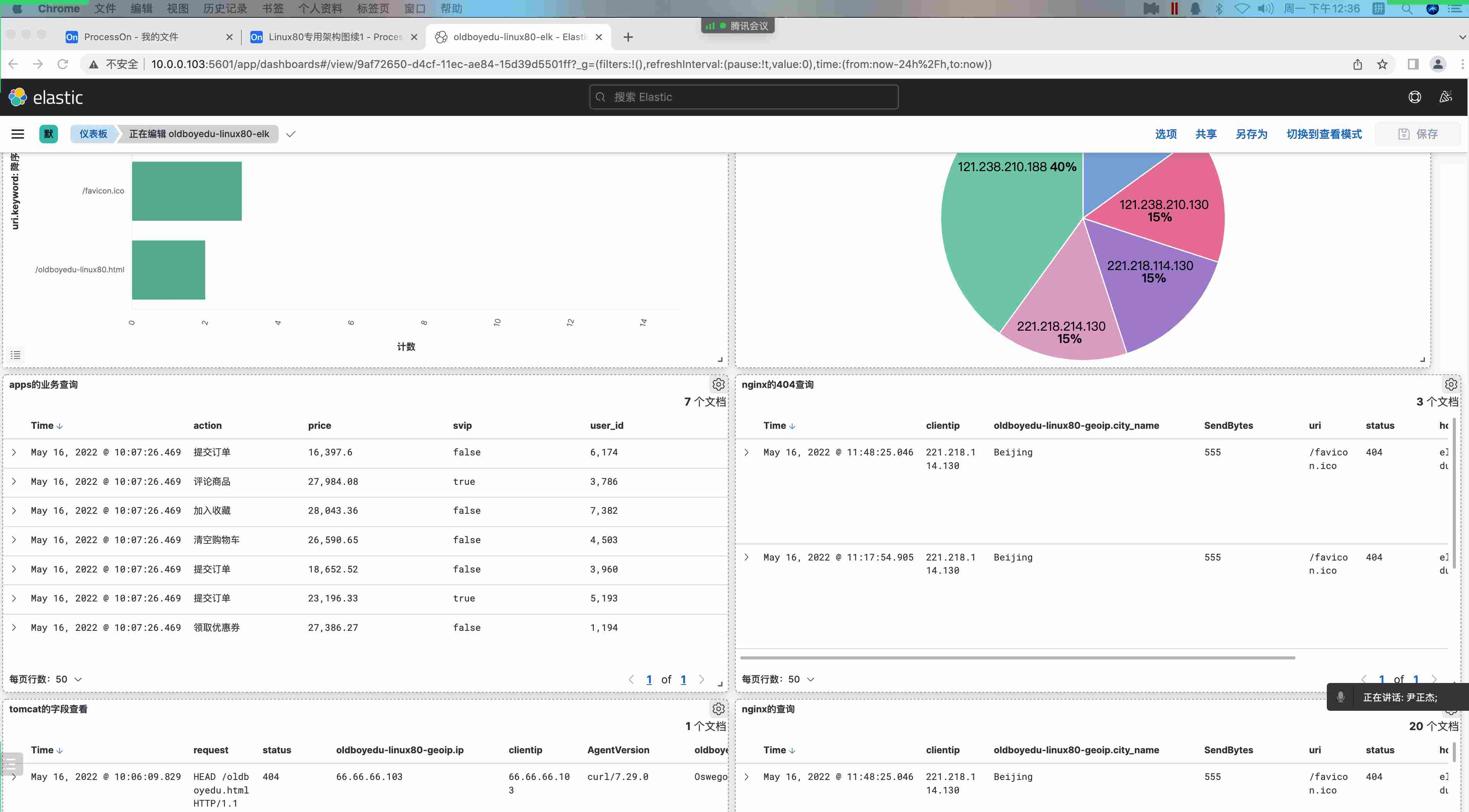
8.自定义 dashboard
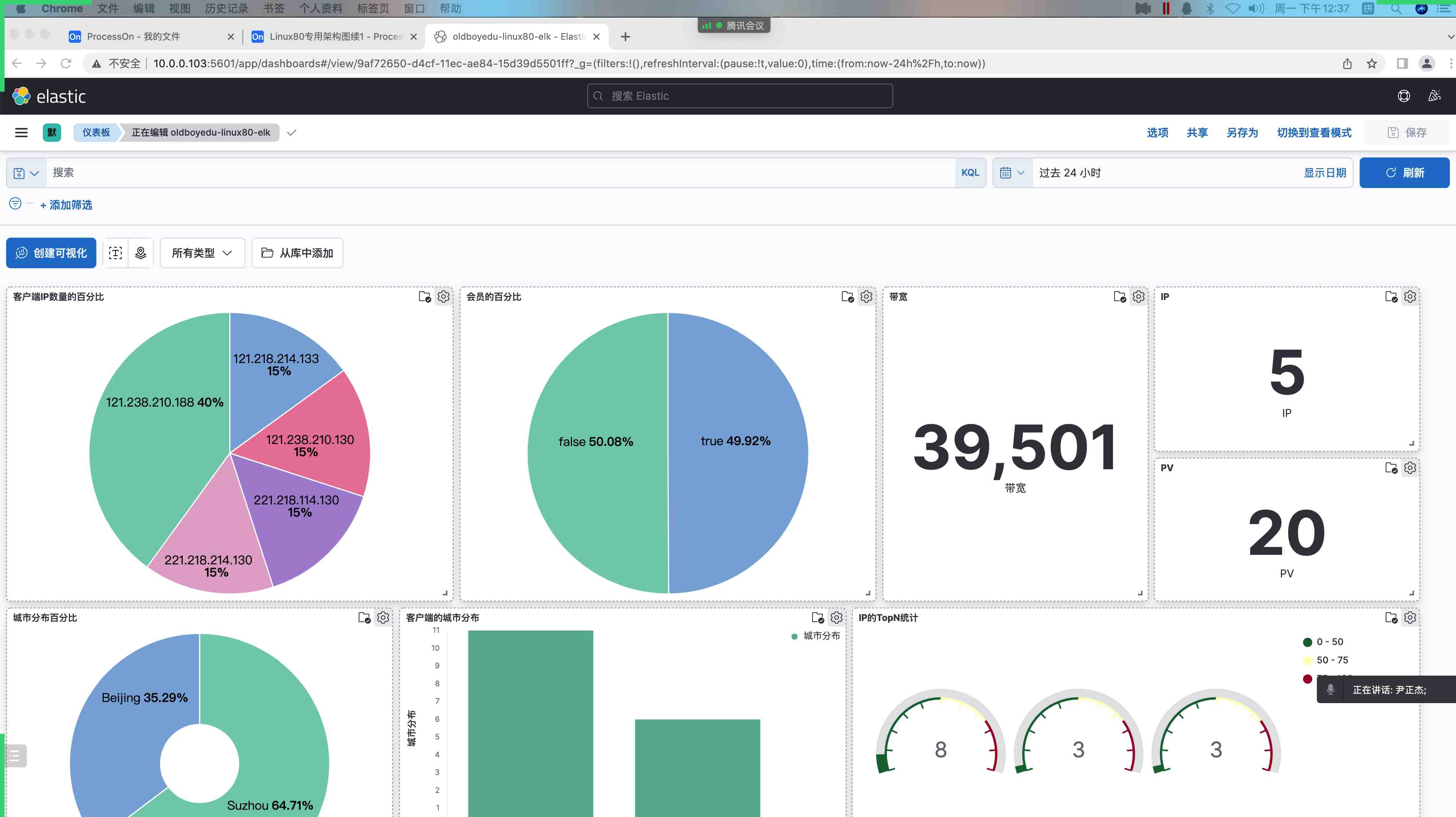
1 | kibana界⾯⿏标依次点击如下: |
ElasticStack 二进制部署及排错
1.部署 Oracle JDK 环境
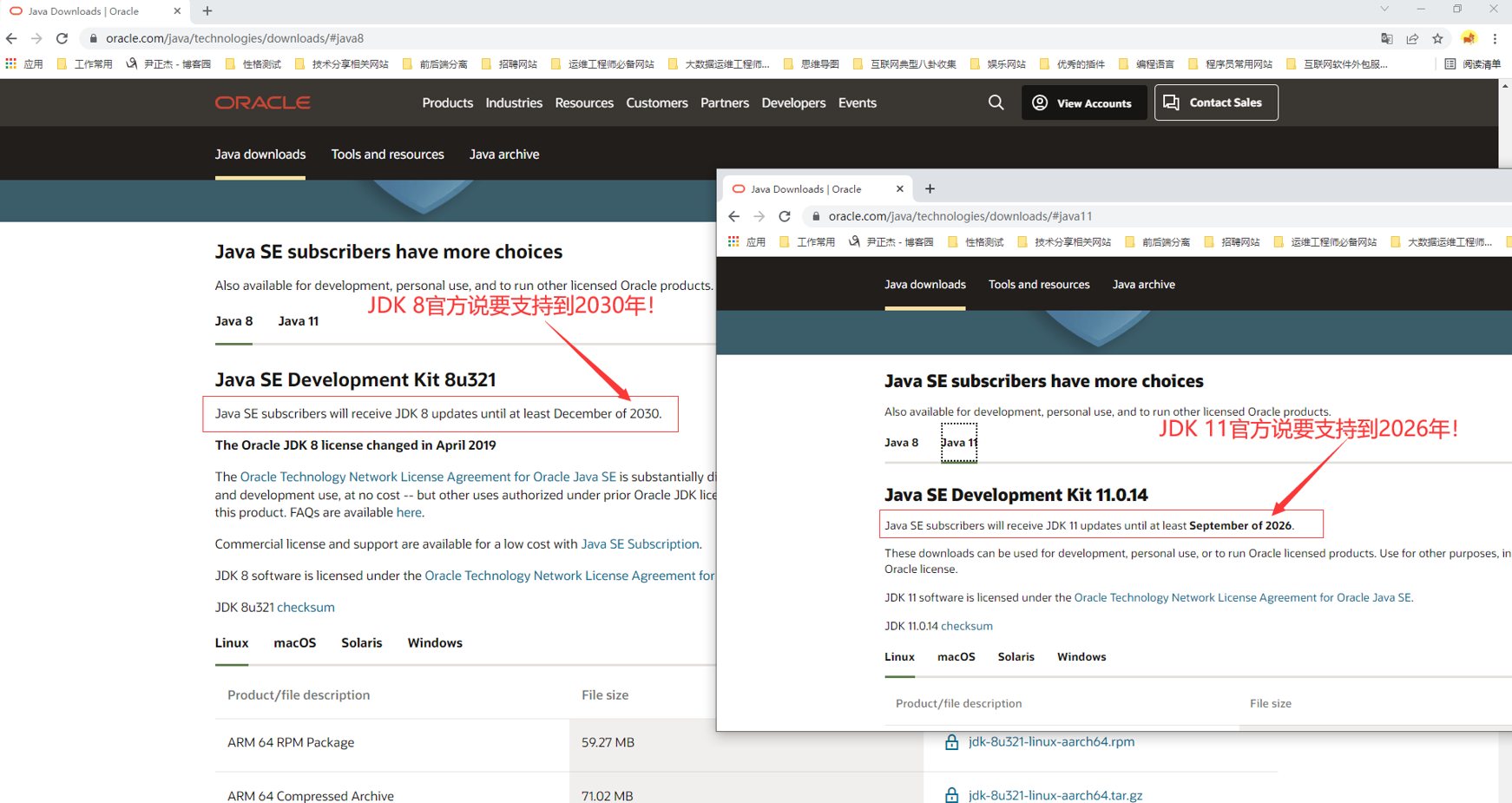
1 | # 官⽅连接: https://www.oracle.com/java/technologies/downloads/#java8 |
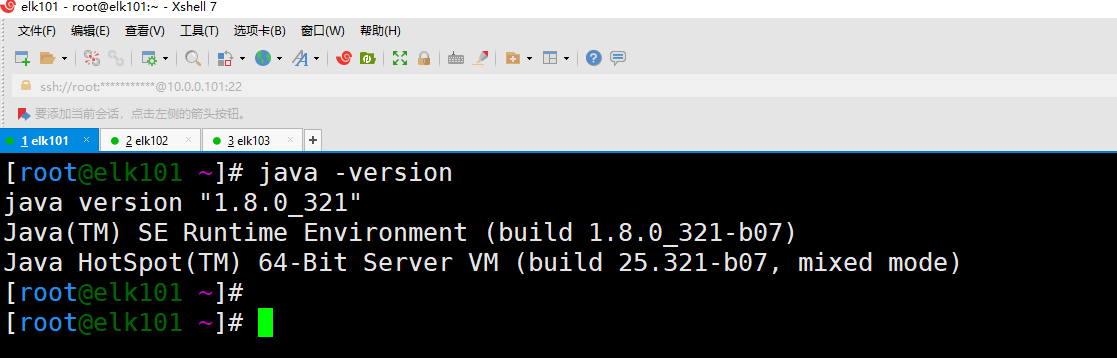
2.单节点 ES 部署
1 | # (1)下载ES软件 |
3.修改 ES 的堆(heap)内存大小
1 | 前置知识: |
4.ES 启动脚本编写
1 | $ cat > /usr/lib/systemd/system/es.service <<EOF |
5.部署 ES 集群
1 | # (1)停⽌ES服务并删除集群之前的数据(如果是ES集群扩容就别删除数据了,我这⾥是部署⼀个"⼲净"的集群) |
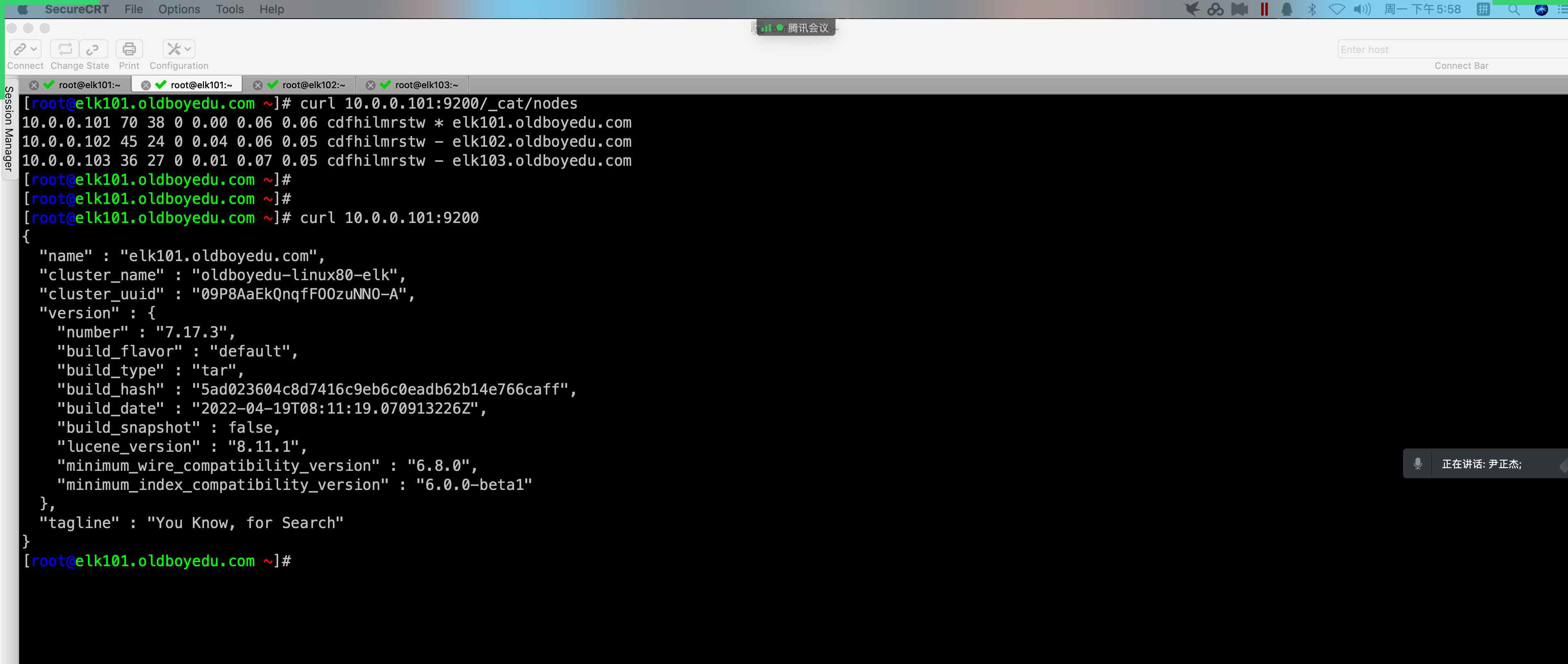
6.部署 kibana 服务
1 | # (1)解压软件包 |
7.部署 logstash
1 | # (1)解压logstash |

7.部署 filebeat
1 | # (1)解压软件包 |
8.部署 es-head 插件
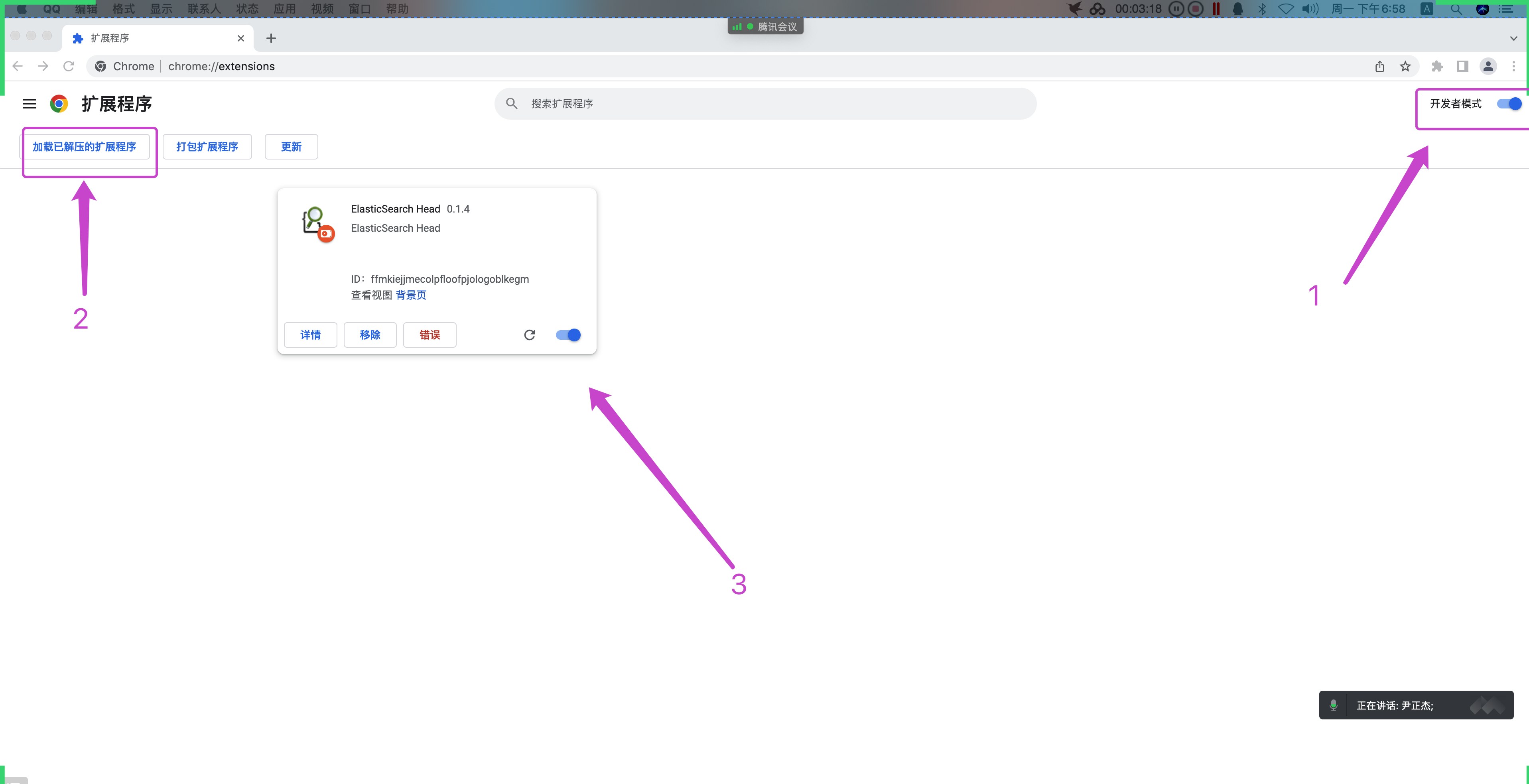
1 | (1)解压es-head组件的软件包 |
9.部署 postman 组件
1 | (1)下载postman组件 |

10.今⽇作业
1 | (1)完成课堂的所有练习 |
ElasticSearch 的 Restful 风格 API 实战
1.Restful 及 JSON 格式
| 数据类型 | 描述 | 举例 |
|---|---|---|
| 字符串 | 要求使⽤双引号(””)引起来的数据 | “oldboyedu” |
| 数字 | 通常指的是 0-9 的所有数字。 | 100 |
| 布尔值 | 只有 true 和 false 两个值 | true |
| 空值 | 只有 null 一个值 | null |
| 数组 | 使⽤⼀对中括号(”[]”)放⼊不同的元素(⽀持⾼级数据类型和基础数据类型) | [“linux”,100,false] |
| 对象 | 使⽤⼀对⼤括号(”{}”)扩起来,⾥⾯的数据使⽤ KEY-VALUE 键值对即可。 | {“class”:”linux80”,”age”:25} |
1 | Restful⻛格程序: |
2.ElasticSearch 的相关术语
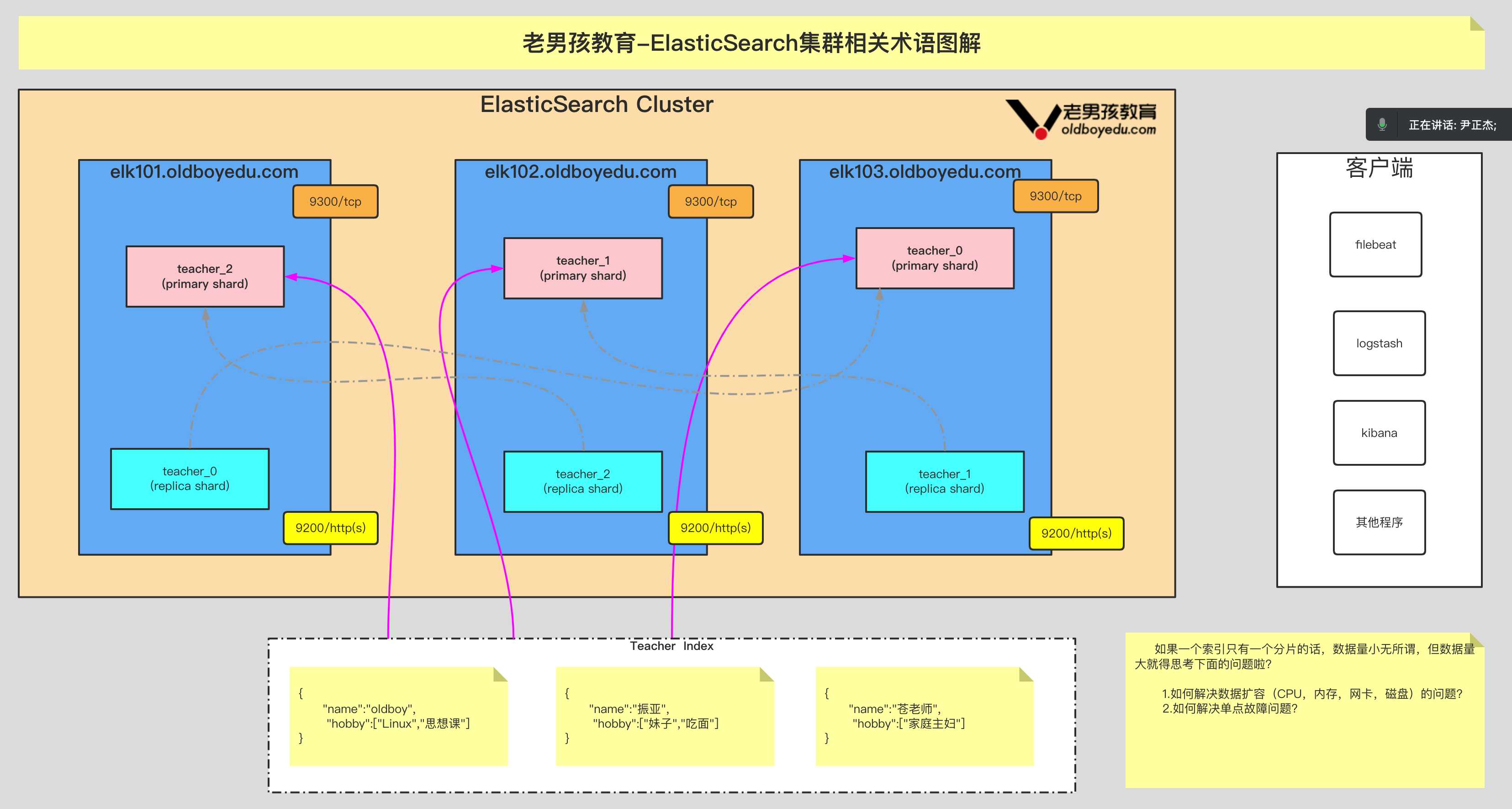
1 | Document: |
3.管理索引的 API
3.1 查看索引信息
1 | GET http://10.0.0.101:9200/_cat/indices # 查看全部的索引信息 |
3.2 创建索引
1 | PUT http://10.0.0.101:9200/oldboyedu-linux82 # 创建索引并指定分⽚和副本 |
3.3 修改索引
1 | PUT http://10.0.0.101:9200/oldboyedu-linux80/_settings |
3.4 删除索引
1 | DELETE http://10.0.0.101:9200/oldboyedu-linux80 |
3.5 索引别名
1 | POST http://10.0.0.101:9200/_aliases # 添加索引别名 |
3.6 索引关闭
1 | POST http://10.0.0.101:9200/oldboyedu-linux80/_close # 关闭索引 |
3.7 索引打开
1 | POST http://10.0.0.101:9200/oldboyedu-linux80/_open # 打开索引 |
3.8 索引的其他操作
推荐阅读: https://www.elastic.co/guide/en/elasticsearch/reference/current/indices.html
4.管理文档的 API
4.1 文档的创建
1 | POST http://10.0.0.101:9200/teacher/_doc # 创建⽂档不指定"_id" |
4.2 文档的查看
1 | GET http://10.0.0.101:9200/teacher/_search # 查看所有的⽂档 |
4.3 文档的修改
1 | POST http://10.0.0.101:9200/teacher/_doc/4FHB0IABf2fC857QLdH6 # 全量更新,会覆盖原有的⽂档数据内容。 |
4.4 文档的删除
1 | DELETE http://10.0.0.101:9200/teacher/_doc/1001 |
4.5 文档的批量操作
1 | POST http://10.0.0.101:9200/_bulk # 批量创建 |
温馨提示: 对于⽂档的批量写操作,需要使⽤_bulk的 API,⽽对于批量的读操作,需要使⽤_mget的 API。
参考链接:
https://www.elastic.co/guide/en/elasticsearch/reference/7.17/docs-bulk.html
https://www.elastic.co/guide/en/elasticsearch/reference/7.17/docs-multi-get.html
4.6 课堂的练习
将下⾯的数据存储到 ES 集群:
1 | {"name":"oldboy","hobby":["Linux","思想课"]} |
5.使用映射(mapping)自定义数据类型
5.1 映射的数据类型
当写⼊⽂档时,字段的数据类型会被 ES 动态⾃动创建,但有的时候动态创建的类型并符合我们的需求。这个时候就可以使⽤映射解决。
使⽤映射技术,可以对 ES ⽂档的字段类型提前定义我们期望的数据类型,便于后期的处理和搜索。
- text: 全⽂检索,可以被全⽂匹配,即该字段是可以被拆分的。
- keyword: 精确匹配,必须和内容完全匹配,才能被查询出来。
- ip: ⽀持 Ipv4 和 Ipv6,将来可以对该字段类型进⾏ IP 地址范围搜索。
参考链接:
https://www.elastic.co/guide/en/elasticsearch/reference/7.17/mapping.html
https://www.elastic.co/guide/en/elasticsearch/reference/7.17/mapping-types.html
5.2 IP 案例
1 | PUT http://10.0.0.101:9200/oldboyedu-linux80-elk # 创建索引时指定映射关系 |
5.3 其他类型类型案例
1 | PUT http://10.0.0.101:9200/oldboyedu-linux80-elk-2022 # 创建索引 |
6. IK 中文分词器
6.1 内置的标准分词器 - 分析英文
1 | GET http://10.0.0.101:9200/_analyze |
温馨提示: 标准分词器模式使⽤空格和符号进⾏切割分词的。
6.2 内置的标准分词器 - 分析中文并不友好
1 | GET http://10.0.0.101:9200/_analyze |
温馨提示: 标准分词器默认使⽤单个汉⼦进⾏切割,很明显,并不符合我们国内的使⽤习惯。
6.3 安装 IK 分词器
下载地址: https://github.com/medcl/elasticsearch-analysis-ik
安装 IK 分词器:
1 | install -d /oldboyedu/softwares/es/plugins/ik -o oldboyedu -g oldboyed |
重启 ES 节点,使之加载插件:
1 | systemctl restart es |
测试 IK 分词器:
1 | GET http://10.0.0.101:9200/_analyze # 细粒度拆分 |
6.4 自定义 IK 分词器的字典
1 | # (1)进⼊到IK分词器的插件安装⽬录 |
6.5 自定义分词器 - 了解即可
1 | # (1)⾃定义分词器 |
7. 今日作业
1 | (1)将"shopping.json"⽂件的内容使⽤"_bulk"的API批量写⼊ES集群,要求索引名称为"oldboyedu-shopping"; |
7.1 shopping.json
1 | { |
7.2 oldboyedu-linux80.json
1 | 等你来完善... |
参考案例 1
1 | POST http://10.0.0.103:9200/_bulk |
参考案例 2
1 | # (1)启动filebeat |
索引模板
1.什么是索引模板
索引模板是创建索引的⼀种⽅式。
当数据写⼊指定索引时,如果该索引不存在,则根据索引名称匹配相应索引模板的话,会根据模板的配置⽽建⽴索引。
索引模板仅对新创建的索引⽣效,对已经创建的索引是没有任何作⽤的。
推荐阅读: https://www.elastic.co/guide/en/elasticsearch/reference/7.17/index-templates.html
2.查看索引模板
1 | GET http://10.0.0.103:9200/_template # 查看所有的索引模板 |
3.创建/修改索引模板
1 | POST http://10.0.0.103:9200/_template/oldboyedu-linux80 |
4.删除索引模板
1 | DELETE http://10.0.0.103:9200/_template/oldboyedu-linux80 |
ES 的 DSL 语句查询 - DBA 方向需要掌握!
1.什么是 DSL
Elasticsearch 提供了基于 JSON 的完整 Query DSL(Domain Specific Language,领域特定语⾔)来定义查询。
2.全文检索 - match 查询
1 | POST http://10.0.0.103:9200/oldboyedu-shopping/_search |
3.完全匹配 - match_phrase 查询
1 | POST http://10.0.0.103:9200/oldboyedu-shopping/_search |
4.全量查询 - match_all
1 | POST http://10.0.0.103:9200/oldboyedu-shopping/_search |
5.分页查询 - size-from
1 | POST http://10.0.0.103:9200/oldboyedu-shopping/_search |
6.查看“_source”对象的指定字段
1 | POST http://10.0.0.103:9200/oldboyedu-shopping/_search |
7.查询包含指定字段的文档 - exists
1 | POST http://10.0.0.103:9200/oldboyedu-shopping/_search |
8.语法高亮 - hightlight
1 | POST http://10.0.0.103:9200/oldboyedu-shopping/_search |
9.基于字段进行排序 - sort
1 | POST http://10.0.0.103:9200/oldboyedu-shopping/_search |
10.多条件查询 - bool
1 | POST http://10.0.0.103:9200/oldboyedu-shopping/_search |
11.范围查询 - filter
1 | POST http://10.0.0.103:9200/oldboyedu-shopping/_search |
12.精确匹配多个值 - terms
1 | POST http://10.0.0.103:9200/oldboyedu-shopping/_search |
13.多词搜索 - 了解即可
1 | POST http://10.0.0.103:9200/oldboyedu-shopping/_search |
14.权重案例 - 了解即可
1 | POST http://10.0.0.103:9200/oldboyedu-shopping/_search |
15.聚合查询 - 了解即可
1 | POST http://10.0.0.103:9200/oldboyedu-shopping/_search # 统计每个品牌的数量。 |
ES 集群迁移
1.部署 ES6 分布式集群
1 | # (1)下载ES 6的软件包 |
2.基于_reindex 的 API 迁移
1 | POST http://10.0.0.103:9200/_reindex |
3.基于 logstash 实现索引跨集群迁移
1 | [root@elk101.oldboyedu.com ~]$ cat conf-logstash/03-es-to-es.conf |
ES 集群常用的 API
1.ES 集群健康状态 API(heath)

1 | # (1)安装jq⼯具 |
2.ES 集群的设置及优先级(settings)
1 | 如果您使⽤多种⽅法配置相同的设置,Elasticsearch 会按以下优先顺序应⽤这些设置: |
3.集群状态 API(state)
1 | 集群状态是⼀种内部数据结构,它跟踪每个节点所需的各种信息,包括: |
4.集群统计 API(stats)
1 | Cluster Stats API 允许从集群范围的⻆度检索统计信息。返回基本索引指标(分⽚数量、存储⼤⼩、内存使⽤情况)和有关构成集群的当前节点的信息(数量、⻆⾊、操作系统、jvm 版本、内存使⽤情况、cpu 和已安装的插件)。 |
5.查看集群的分片分配情况(allocation)
集群分配解释 API 的⽬的是为集群中的分⽚分配提供解释。
对于未分配的分⽚,解释 API 提供了有关未分配分⽚的原因的解释。
对于分配的分⽚,解释 API 解释了为什么分⽚保留在其当前节点上并且没有移动或重新平衡到另⼀个节点。
当您尝试诊断分⽚未分配的原因或分⽚继续保留在其当前节点上的原因时,此 API 可能⾮常有⽤,⽽您可能会对此有所期待。
1 | # (1)分析teacher索引的0号分⽚未分配的原因。 |
6.集群分片重路由 API(reroute)
reroute 命令允许⼿动更改集群中各个分⽚的分配。
例如,可以将分⽚从⼀个节点显式移动到另⼀个节点,可以取消分配,并且可以将未分配的分⽚显式分配给特定节点。
1 | POST http://10.0.0.101:9200/_cluster/reroute # 将"teacher"索引的0号分⽚从elk102节点移动到elk101节点。 |
推荐阅读: https://www.elastic.co/guide/en/elasticsearch/reference/7.17/cluster-reroute.html
7.今日作业
1 | (1)完成课堂的所有练习; |
ES 集群理论篇
1.倒排索引
⾯试题: 分⽚底层时如何⼯作的?
答: 分⽚底层对应的是⼀个 Lucene 库,⽽ Lucene 底层使⽤倒排索引技术实现。
正排索引(正向索引)
我们 MySQL 为例,⽤ id 字段存储博客⽂章的编号,⽤ context 存储⽂件的内容。
1 | CREATE TABLE blog (id INT PRIMARY KEY AUTO_INCREMENT, contextTEXT); |
此时,如果我们查询⽂章内容包含”Jason Yin”的词汇的时候,就⽐较麻烦了,因为要进⾏全表扫描。
1 | SELECT * FROM blog WHERE context LIKE 'Jason Yin'; |
倒排索引(反向索引)
ES 使⽤⼀种称为”倒排索引”的结构,它适⽤于快速的全⽂检索。
倒排索引中有以下三个专业术语:
1、词条:
指的是最⼩的存储和查询单元,换句话说,指的是您想要查询的关键字(词)。
对应英⽂⽽⾔通常指的是⼀个单词,⽽对于中⽂⽽⾔,对应的是⼀个词组。
2、词典(字典):
它是词条的集合,底层通常基于”Btree+”和”HASHMap”实现。
3、倒排表:
记录了词条出现在什么位置,出现的频率是什么。
倒排表中的每⼀条记录我们称为倒排项。
倒排索引的搜索过程:
- ⾸先根据⽤户需要查询的词条进⾏分词后,将分词后的各个词条字典进⾏匹配,验证词条在词典中是否存在;
- 如果上⼀步搜索结果发现词条不在字典中,则结束本次搜索,如果在词典中,就需要去查看倒排表中的记录(倒排项);
- 根据倒排表中记录的倒排项来定位数据在哪个⽂档中存在,⽽后根据这些⽂档的”_id”来获取指定的数据;
综上所述,假设有 10 亿篇⽂章,对于 mysql 不创建索引的情况下,会进⾏全表扫描搜索”JasonYin”。⽽对于 ES ⽽⾔,其只需要将倒排表中返回的 id 进⾏扫描即可,⽽⽆须进⾏全量查询。
2.集群角色

1 | ⻆⾊说明: |
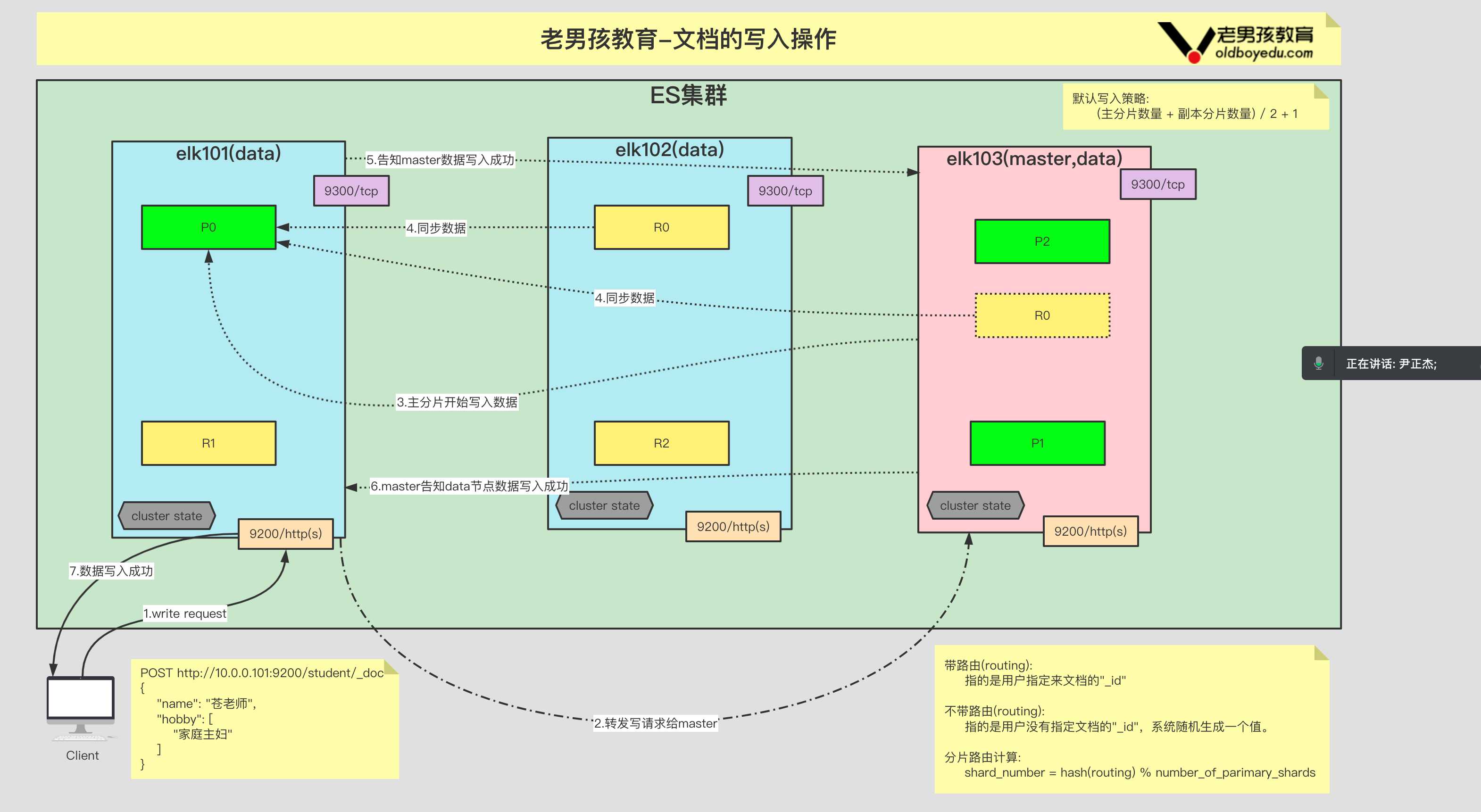
3.文档的写流程
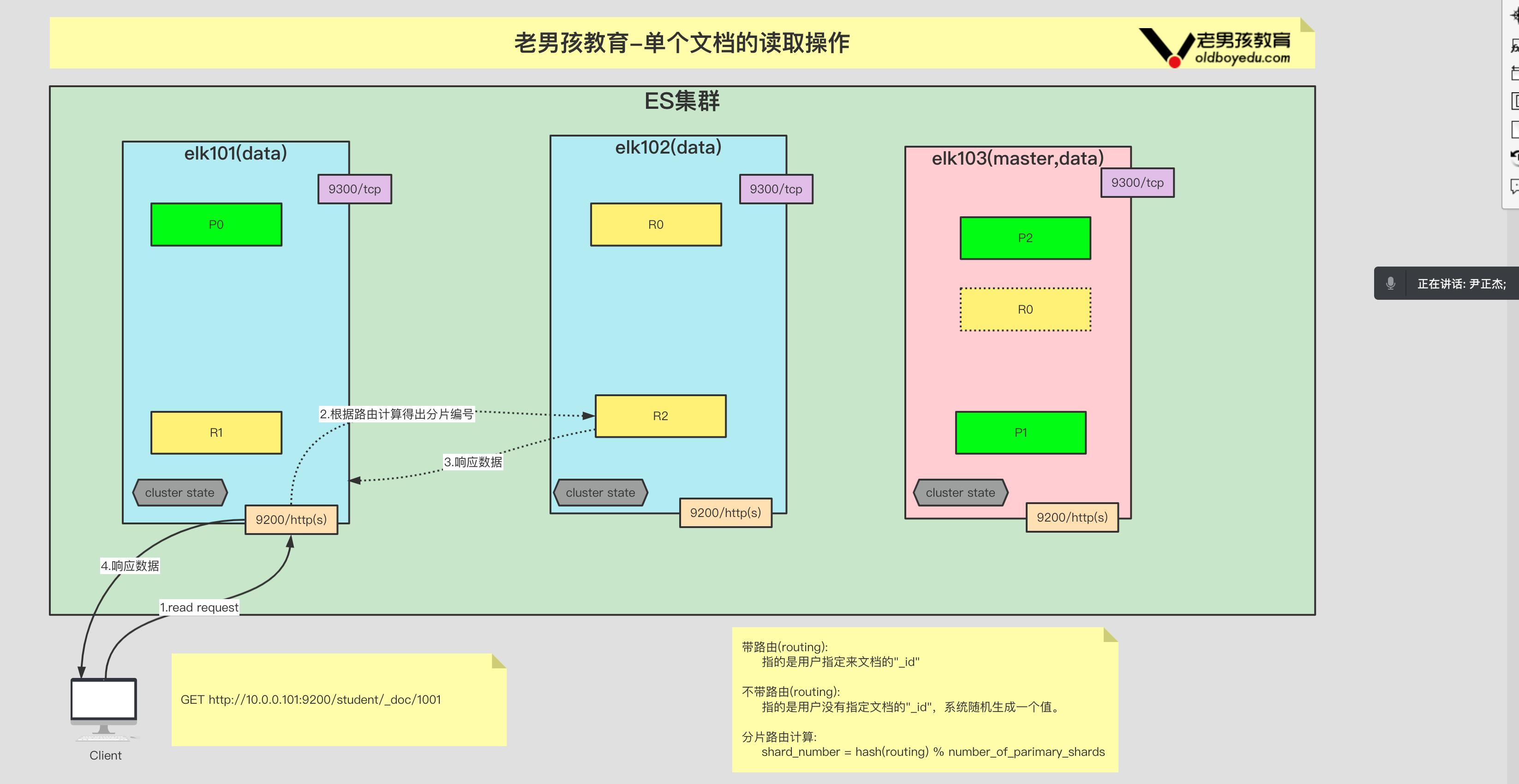
4.单个文档的读流程
5.ES 底层存储原理剖析
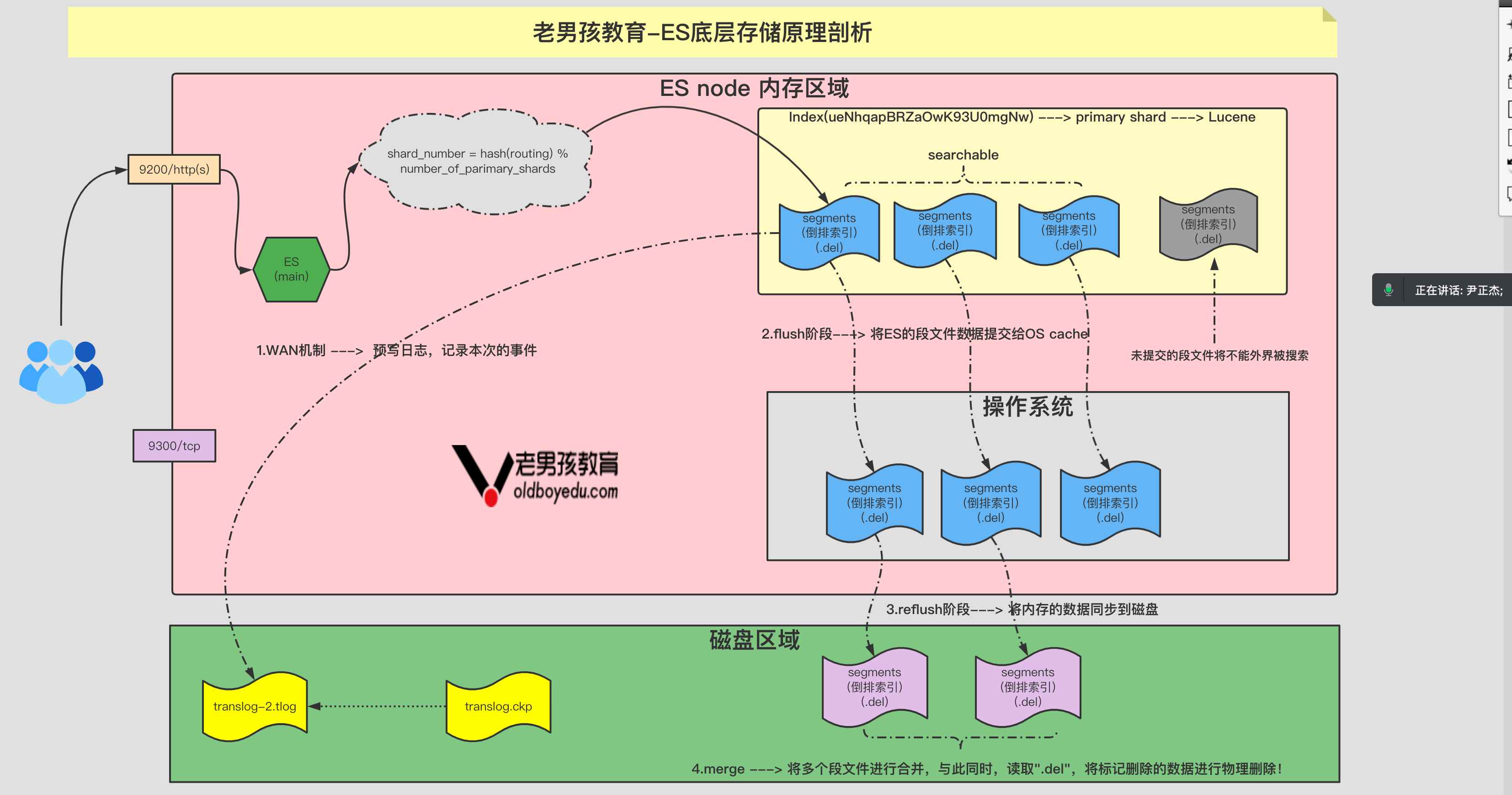
事务⽇志存储在哪⾥?
1 | 在索引分⽚⽬录下,取名⽅式如下: |
什么时候删事务⽇志?
1 | 在flush的时候,translog⽂件会被清空。实际的过程是先删掉⽼⽂件,再创建⼀个新⽂件,取名时,序号加1,⽐如图2中,flush后你只会看到 translog-2.tlog,原来的translog-1.tlog已被删除。 |
为什么要删?
1 | 因为数据修改已经写⼊磁盘了,之前的旧的⽇志就⽆⽤武之地了,留着只能⽩嫖存储空间。 |
6.乐观锁机制 - 了解即可
两种⽅法通常被⽤来解决并发更新时变更不会丢失的解决⽅案:
1、悲观并发控制
这种⽅法被关系型数据库⼴泛使⽤,它假定有变更冲突可能发⽣,因此阻塞访问资源以防⽌冲突。⼀个典型的例⼦是修改⼀⾏数据之前像将其锁住,确保只有获得锁的线程能够对这⾏数据进⾏修改。
2、乐观锁并发控制
ES 中使⽤的这种⽅法假设冲突是不可能发⽣的,并且不会阻塞正在尝试的操作。然⽽,如果源数据在读写当中被修改,更新将会失败。应⽤程序接下来该如果解决冲突。例如,可以重试更新,使⽤新的数据,或者将相关情况报告给⽤户。
1 | # (1)创建⽂档 |
python 操作 ES 集群 API 实战
1.创建索引
1 | #!/usr/bin/env python3 |
2.写⼊单个⽂档
1 | #!/usr/bin/env python3 |
3.写入多个文档
1 | #!/usr/bin/env python3 |
4.全量查询
1 | #!/usr/bin/env python3 |
5.查看多个文档
1 | #!/usr/bin/env python3 |
6.DSL 查询
1 | #!/usr/bin/env python3 |
7.查看索引是否存在
1 | #!/usr/bin/env python3 |
8.修改文档
1 | #!/usr/bin/env python3 |
9.删除单个文档
1 | #!/usr/bin/env python3 |
10.删除索引
1 | #!/usr/bin/env python3 |
ES 集群加密的 Kibana 的 RABC 实战
1.基于 nginx 反向代理控制 kibana
1 | # (1)部署nginx服务 略,参考之前的笔记即可。 |
2.配置 ES 集群 TLS 认证
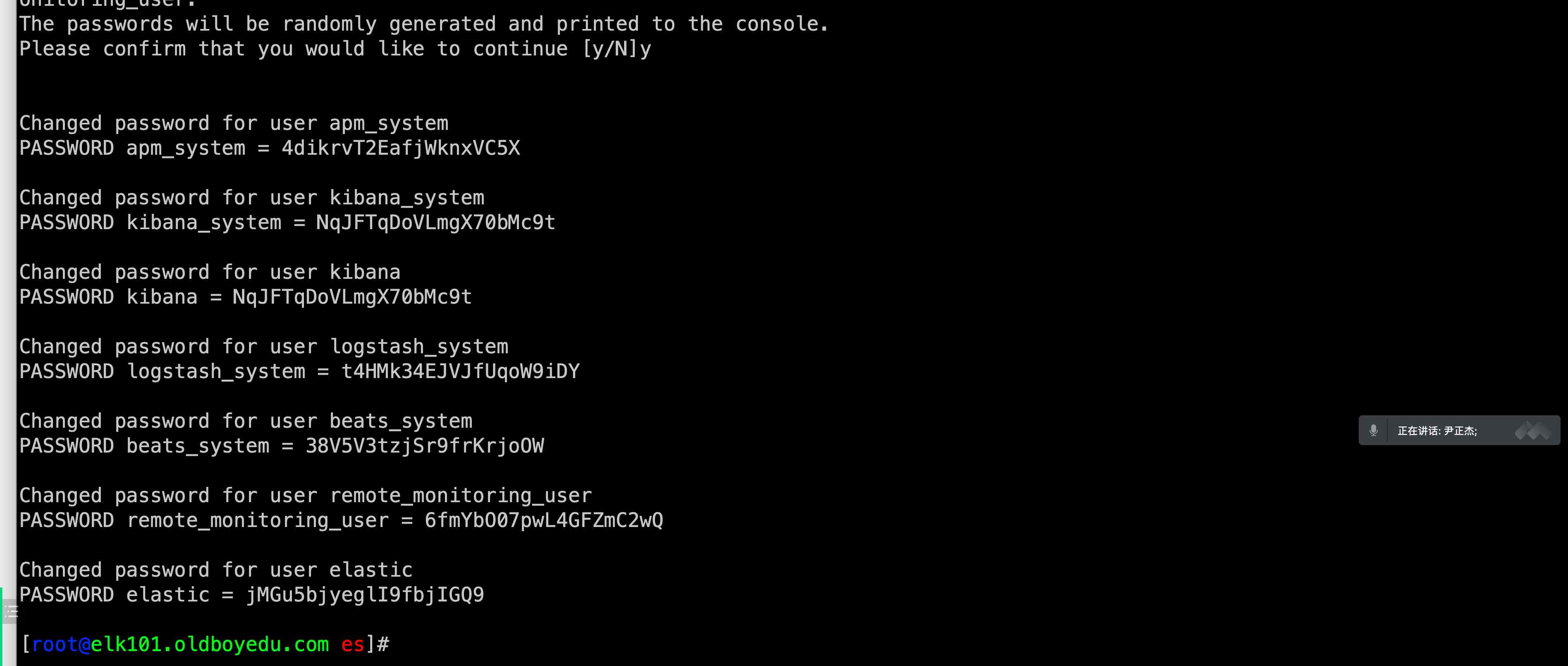
1 | # (1)⽣成证书⽂件 |
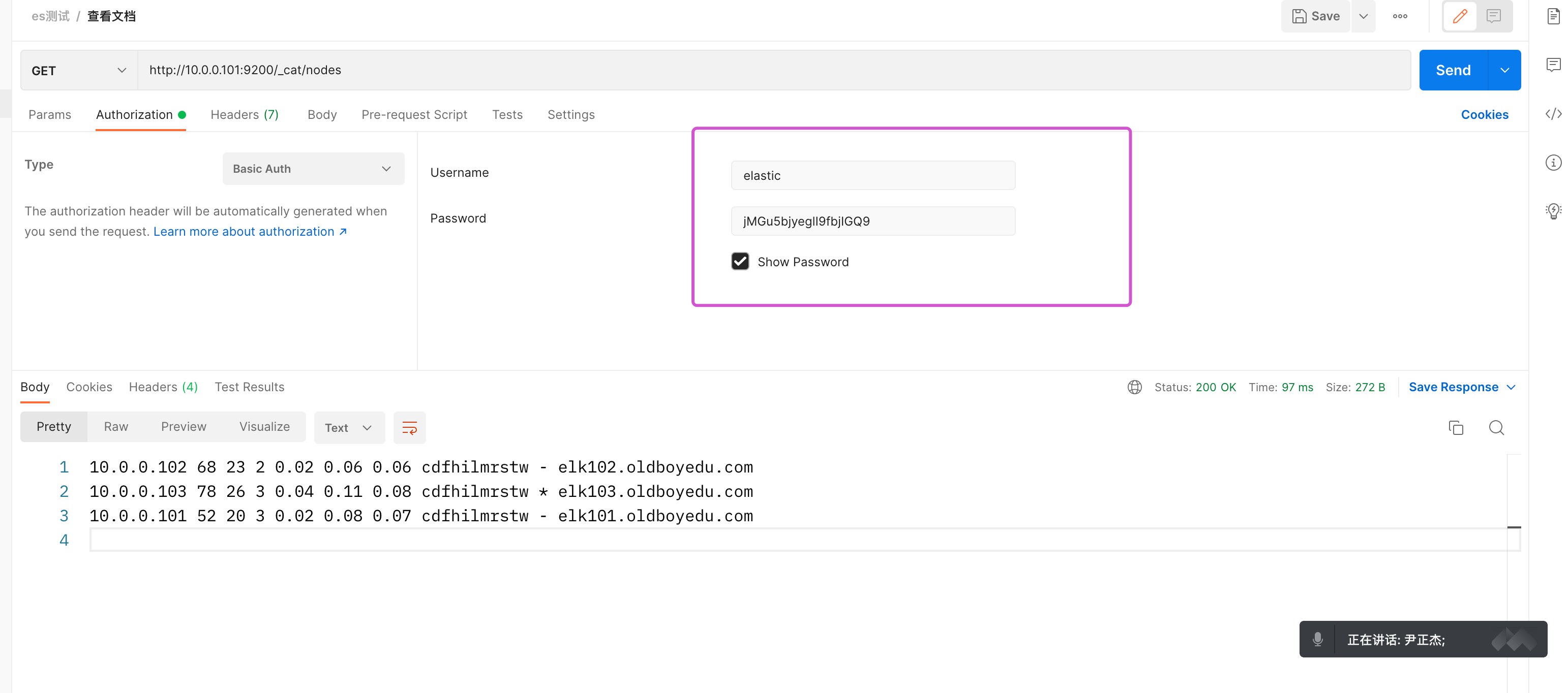
3.kibana 添加 ES 认证
1 | # (1)修改kibana的配置⽂件 |
4.kibana 的 RBAC

具体实操⻅视频。
5.logstash 写入 ES 加密集群案例
1 | input { |
温馨提示:
建议⼤家不要使⽤ elastic 管理员⽤户给 logstash 程序使⽤,⽽是创建⼀个普通⽤户,并为该⽤户细化权限。
6.filebeat 写入 ES 加密集群案例
1 | filebeat.inputs: |
温馨提示:
建议⼤家不要使⽤ elastic 管理员⽤户给 filebeat 程序使⽤,⽽是创建⼀个普通⽤户,并为该⽤户细化权限。