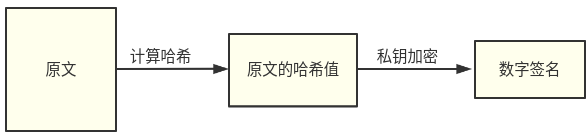
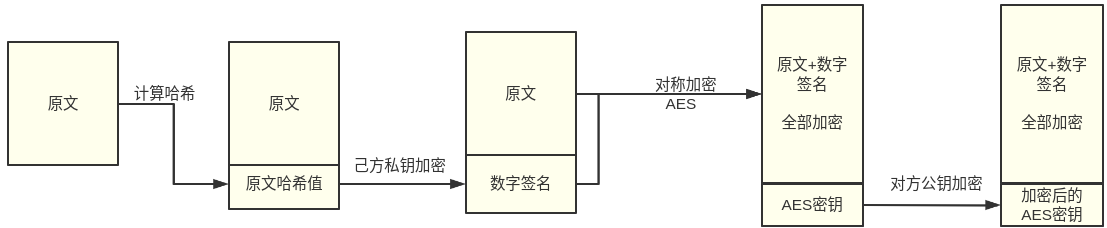
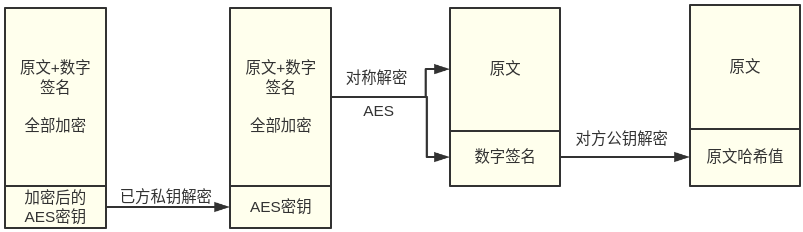
js函数
有默认值的参数传入undefined,则会取默认值。如果这个参数位于最后,则可以不传(相当于隐式传入undefined),否则得显式传入 undefined
1 | function get() { |
有默认值的参数传入undefined,则会取默认值。如果这个参数位于最后,则可以不传(相当于隐式传入undefined),否则得显式传入 undefined
1 | function get() { |
可变状态:
1 | let objA = { name: "xiaoming" } |
我们只修改了 objB 的 name,发现 ojbA 也发生了改变。这个就是可变状态。
可变状态间接修改了其它对象,会造成代码隐患。
解决方案:
当我们使用 deepClone 或 immer / immutable-js 创建一个新对象,新对象进行有副作用(side effect)的操作都不会影响到原来的数据。这就是 immutable。
deepClone 虽然实现了 immutable,但是开销太大,因为它完全创建了一个新的对象出来,其实,对于不会进行赋值操作的 value 保持引用也没关系。
所以在 2014 年,facebook 的 immutable-js 横空出世,即保证了 immutable ,在运行时判断数据间的引用情况,又兼顾了性能。
immutable-js 使用了另一套数据结构的 API ,与我们的常见操作有些许不同,它将所有的原生数据类型(Object, Array 等)都会转化成 immutable-js 的内部对象(Map,List 等),并且任何操作最终都会返回一个新的 immutable 的值。
Immer 是 mobx 的作者写的一个 immutable 库,核心实现是利用 ES6 的 proxy,几乎以最小的成本实现了 js 的不可变数据结构,简单易用、体量小巧、设计巧妙,满足了我们对 JS 不可变数据结构的需求。
与 immutable-js 最大的不同,immer 是使用原生数据结构的 API 而不是像 immutable-js 那样转化为内置对象之后使用内置的 API,举个简单例子:
1 | const produce = require("immer") |
通过上面的例子我们能发现,所有具有副作用的逻辑都可以放进 produce 的第二个参数的函数内部进行处理。在这个函数内部对原来的数据进行任何操作,都不会对原对象产生任何影响。
Immer 使用了 ES6 的新特性 Proxy 。
https://developer.mozilla.org/zh-CN/docs/Web/JavaScript/Reference/Global_Objects/Proxy
Proxy 对象用于创建一个对象的代理,从而实现基本操作的拦截和自定义(如属性查找、赋值、枚举、函数调用等)。
immer 的做法就是维护一份 state 在内部,劫持所有操作,内部来判断是否有变化从而最终决定如何返回。下面这个例子就是一个构造函数,如果将它的实例传入 Proxy 对象作为第一个参数,后面处理对象时,就可以使用其中的方法:
1 | class Store { |
modified,source,copy 三个属性;get,set,modifing 三个方法。
modified 作为内置的 flag,判断如何进行设置和返回。
里面最关键的就应该是 modifing 这个函数,在第一次 set 的时候,实现一次 copy,copy 后的数据也是 immutable。
对于 Proxy 的第二个参数,简单做一层转发,任何对元素的读取和写入都转发到 store 实例内部方法去处理:
1 | const PROXY_FLAG = "@@SYMBOL_PROXY_FLAG" |
这里在 getter 里面加一个 flag 的目的就在于将来从 proxy 对象中获取 store 实例更加方便。
最终我们能够完成这个 produce 函数:
1 | function produce(state, producer) { |
这样,Store 构造函数、handler 处理对象,produce 处理 state,这三个模块最简版就完成了,将它们组合起来就是一个最 tiny 的 immer。真正的 immer 内部还有其他的功能。
当然,Proxy 作为一个新的 API,并不是所有环境都支持,Proxy 也无法 polyfill,所以 immer 在不支持 Proxy 的环境中,使用 Object.defineProperty 来进行一个兼容。
freeze 表示状态树在生成之后就被冻结不可继续操作。对于普通 JS 对象,我们可以使用 Object.freeze 来冻结我们生成的状态树对象,当然像 immer / immutable-js 内部自己有冻结的方法和逻辑。
configureStore创建 Redux storeconfigureStore 接受 reducer 函数作为命名参数configureStore 使用的好用的默认设置自动设置 store<Provider> 组件包裹你的 <App /><Provider store={store}>createSlice创建 Redux “slice” reduceruseSelector/useDispatch钩子useSelector钩子从 store 中读取数据useDispatch钩子获取dispatch函数,并根据需要 dispatch actions你将学到
- RTK Query 如何简化 Redux 应用程序的数据获取
- 如何设置 RTK Query
- 如何使用 RTK Query 进行基本的数据获取和更新请求
RTK Query 是一个强大的数据获取和缓存工具。它旨在简化在 Web 应用程序中加载数据的常见情况,无需自己手动编写数据获取和缓存逻辑。
RTK Query 是一个包含在 Redux Toolkit 包中的可选插件,其功能构建在 Redux Toolkit 中的其他 API 之上。
在过去的几年里,React 社区已经意识到 “数据获取和缓存” 实际上是一组不同于 “状态管理” 的关注点。
RTK Query 从其他开创数据获取解决方案的工具中汲取灵感,例如 Apollo Client、React Query、Urql 和 SWR,但在其 API 设计中添加了独特的方法:
createSlice 和 createAsyncThunk API 之上data 和 isFetching 字段,并在组件挂载和卸载时管理缓存数据的生命周期RTK Query 包含在核心 Redux Toolkit 包的安装中。它可以通过以下两个入口点之一获得:
1 | import { createApi } from "@reduxjs/toolkit/query" |
RTK Query 主要由两个 API 组成:
createApi():RTK Query 功能的核心。它允许你定义一组请求接口来描述如何从一系列请求接口检索数据,包括如何获取和转换该数据的配置。在大多数情况下,你应该在每个应用程序中使用一次,根据经验,“每个基本 URL 一个 API slice”。fetchBaseQuery(): fetch 的一个小包装 -US/docs/Web/API/Fetch_API),旨在简化请求。旨在为大多数用户在 createApi 中使用推荐的 baseQuery。Redux 一直强调可预测性和显式行为。Redux 没有“魔法”,所有 Redux 逻辑都遵循相同的基本模式,即通过 reducers 调度操作和更新状态。这确实意味着有时你必须编写更多代码才能使事情发生。
Redux Toolkit 核心 API 不会更改 Redux 应用程序中的任何基本数据流 你仍在调度操作和编写 reducer,只是代码比手动编写所有逻辑要少。 RTK Query 同理。这是一个额外的抽象级别,但在内部,它仍在执行我们已经看到的用于管理异步请求及其响应的完全相同的步骤。
但是,当你使用 RTK Query 时,会发生思维转变。我们不再考虑“管理状态”本身。相反,我们现在考虑“管理*缓存数据*”。与其尝试自己编写 reducer,我们现在将专注于定义 “这些数据来自哪里?”、“这个更新应该如何发送?”、“这个缓存的数据应该什么时候重新获取?”,以及“缓存的数据应该如何更新?”。如何获取、存储和检索这些数据成为我们不再需要担心的实现细节。
1 | export const fetchNotifications = createAsyncThunk("notifications/fetchNotifications", async (_, { getState }) => { |
payload creator 的第二个参数是一个’ thunkAPI ‘对象,包含几个有用的函数和信息:
dispatch 和 getState:dispatch 和 getState 方法由 Redux store 提供。你可以在 thunk 中使用这些来发起 action,或者从最新的 Redux store 中获取 state (例如在发起 另一个 action 后获取更新后的值)。extra:当创建 store 时,用于传递给 thunk 中间件的“额外参数”。这通常时某种 API 的包装器,比如一组知道如何对应用程序的服务器进行 API 调用并返回数据的函数,这样你的 thunk 就不必直接包含所有的 URL 和查询逻辑。requestId:该 thunk 调用的唯一随机 ID ,用于跟踪单个请求的状态。signal:一个AbortController.signal 函数,可用于取消正在进行的请求。rejectWithValue:一个用于当 thunk 收到一个错误时帮助自定义 rejected action 内容的工具。(如果你要手写 thunk 而不是使用 createAsyncThunk,则 thunk 函数将获取 (dispatch, getState) 作为单独的参数,而不是将他们放在一个对象中。)
你将学到
- 如何使用 Redux “thunk” middleware 处理异步逻辑
- 处理异步请求状态的开发模式
- 如何使用 Redux Toolkit
createAsyncThunkAPI 来简化异步调用
就其本身而言,Redux store 对异步逻辑一无所知,任何异步都必须发生在 store 之外。
Redux middleware 扩展了 store,它允许:
dispatch 和 getState 的额外代码dispatch 如何接受除普通 action 对象之外的其他值,例如函数和 promise,通过拦截它们并 dispatch 实际 action 对象来代替使用 middleware 的最常见原因是允许不同类型的异步逻辑与 store 交互。这允许你编写可以 dispatch action 和检查 store 状态的代码,同时使该逻辑与你的 UI 分开。
Redux 有多种异步 middleware,每一种都允许你使用不同的语法编写逻辑。最常见的异步 middleware 是 redux-thunk,它可以让你编写可能直接包含异步逻辑的普通函数。Redux Toolkit 的 configureStore 功能默认自动设置 thunk middleware,我们推荐使用 thunk 作为 Redux 开发异步逻辑的标准方式。
早些时候,我们看到了Redux 的同步数据流是什么样子。当引入异步逻辑时,我们添加了一个额外的步骤,middleware 可以运行像 AJAX 请求这样的逻辑,然后 dispatch action。这使得异步数据流看起来像这样:
将 thunk middleware 添加到 Redux store 后,它允许你将 thunk 函数 直接传递给 store.dispatch。调用 thunk 函数时总是将 (dispatch, getState) 作为它的参数,你可以根据需要在 thunk 中使用它们。
Thunks 通常还可以使用 action creator 再次 dispatch 普通的 action,比如 dispatch(increment()):
1 | const store = configureStore({ reducer: counterReducer }) |
为了与 dispatch 普通 action 对象保持一致,我们通常将它们写为 _thunk action creators_,它返回 thunk 函数。这些 action creator 可以接受可以在 thunk 中使用的参数。
1 | const logAndAdd = amount => { |
Thunk 通常写在 “slice” 文件中。createSlice 本身对定义 thunk 没有任何特殊支持,因此你应该将它们作为单独的函数编写在同一个 slice 文件中。这样,他们就可以访问该 slice 的普通 action creator,并且很容易找到 thunk 的位置。
“thunk” 这个词是一个编程术语,意思是 “一段做延迟工作的代码”.
Thunk 内部可能有异步逻辑,例如 setTimeout、Promise 和 async/await。这使它们成为使用 AJAX 发起 API 请求的好地方。
Redux 的数据请求逻辑通常遵循以下可预测的模式:

这些步骤不是 _必需的_,而是常用的。(如果你只关心一个成功的结果,你可以在请求完成时发送一个“成功” action ,并跳过“开始”和“失败” action 。)
Redux Toolkit 提供了一个 createAsyncThunk API 来实现这些 action 的创建和 dispatch,我们很快就会看看如何使用它。
如果我们手动编写一个典型的 async thunk 的代码,它可能看起来像这样:
1 | const getRepoDetailsStarted = () => ({ |
提示:
Redux Toolkit 有一个新的 RTK Query data fetching API。 RTK Query 是专门为 Redux 应用程序构建的数据获取和缓存解决方案,可以不用编写任何 thunk 或 reducer 来处理数据获取。
可以编写可复用的“selector 选择器”函数来封装从 Redux 状态中读取数据的逻辑
state 作为参数,并返回一些数据Redux 使用叫做“ middleware ”这样的插件模式来开发异步逻辑
redux-thunk,包含在 Redux Toolkit 中dispatch 和getState 作为参数,并且可以在异步逻辑中使用它们你可以 dispatch 其他 action 来帮助跟踪 API 调用的加载状态
'idle' | 'loading' | 'succeeded' | 'failed'Redux Toolkit 有一个 createAsyncThunk API 可以为你 dispatch 这些 action
createAsyncThunk 接受一个 “payload creator” 回调函数,它应该返回一个 Promise,并自动生成 pending/fulfilled/rejected action 类型fetchPosts 这样生成的 action creator 根据你返回的 Promise dispatch 这些 actionextraReducers 字段在 createSlice 中监听这些 action,并根据这些 action 更新 reducer 中的状态。extraReducers 对象的键,以便切片知道要监听的 action。createAsyncThunk,你可以await dispatch(someThunk()).unwrap()来处理组件级别的请求成功或失败。注意
如果 action 需要包含唯一 ID 或其他一些随机值,请始终先生成该随机值并将其放入 action 对象中。
Reducer 中永远不应该计算随机值,因为这会使结果不可预测。
解释:深入理解 redux 之 reducer 为什么是纯函数
以下是修改传入参数的示例:
1 | const params = { a: 1 } |
redux 的核心提供可预测化的状态管理,即无论何时特定的 action 触发的行为永远保持一致,试想如果 reducer 中有 Date.now()等非纯函数,即使同样的 action,那么 reducer 处理过程中也是有所不同的,不再能保证可预测性。
同样,副作用的操作也会带来不可预测性。
显然 api 操作是不可避免的,因为总要向后台请求数据,那么 api 请求应该如何做呢?这里有两个办法:
Redux action creators 可以使用一个正确的内容模板去构造(prepare)action 对象
createSlice 和 createAction 可以接受一个返回 action payload 的 “prepare callback”Reducers 内(仅)应该包含 state 的更新逻辑
“slice” 是应用中单个功能的 Redux reducer 逻辑和 action 的集合, 通常一起定义在一个文件中。
比如,在一个博客应用中,store 的配置大致长这样:
1 | import { configureStore } from "@reduxjs/toolkit" |
1 | import { createSlice } from "@reduxjs/toolkit" |
Redux Toolkit 有一个名为 createSlice 的函数,它负责生成 action 类型字符串、action creator 函数和 action 对象。
createSlice 内部使用了一个名为 Immer 的库。 Immer 使用一种 “Proxy” 包装你提供的数据,当你尝试 ”mutate“ 这些数据的时候,Immer 会跟踪你尝试进行的所有更改,然后使用该更改列表返回一个安全的、不可变的更新值,就好像你手动编写了所有不可变的更新逻辑一样。
state 和 action 参数计算新的状态值state。必须通过复制现有的 state 并对复制的值进行更改的方式来做 _不可变更新(immutable updates)_。“不可变更新(Immutable Updates)” 这个规则尤其重要,值得进一步讨论。
在 Redux 中,**永远 不允许在 reducer 中直接更改 state 的原始对象!**
1 | // ❌ 非法 - 默认情况下,这将更改 state! |
这就是为什么 Redux Toolkit 的 createSlice 函数可以让你以更简单的方式编写不可变更新!
警告
你 只能 在 Redux Toolkit 的
createSlice和createReducer中编写 “mutation” 逻辑,因为它们在内部使用 Immer!如果你在没有 Immer 的 reducer 中编写 mutation 逻辑,它 将 改变状态并导致错误!
到目前为止,我们应用程序中的所有逻辑都是同步的:
但是,我们的应用程序通常具有异步逻辑,我们需要一个地方在我们的 Redux 应用程序中放置异步逻辑。
thunk 是一种特定类型的 Redux 函数,可以包含异步逻辑。Thunk 是使用两个函数编写的:
dispatch 和 getState 作为参数示例:
1 | // 外部的 thunk creator 函数, 它使我们可以执行异步逻辑 |
显然,incrementAsync() 返回的不是 action(action 是具有type字段的纯函数),而是一个函数,但它的使用方式和普通的 action 是一样的:
1 | export function Counter() { |
这是依赖 “middleware” 机制实现的,Redux 的 store 可以使用 “middleware” 进行扩展,中间件是一种可以添加额外功能的附加组件或插件。其最常见的用途就是实现异步逻辑,同时仍能与 store 对话。
Redux Thunk 中间件,代码很短:
1 | const thunkMiddleware = |
它先判断传入 dispatch 的 action 是函数还是对象。如果是一个函数,则调用函数,并返回结果。否则,传入的是普通 action 对象,就把这个 action 传递给 store 处理。
1 | import React, { useState } from "react" |
useSelector 这个 hook 让我们的组件从 Redux 的 store 状态树中提取它需要的任何数据。
我们默认 组件中不能引入 store。所以useSelector负责在幕后与 Redux store 对话。
示例:
1 | const countPlusTwo = useSelector(state => state.counter.value + 2) |
useSelector 会调用 store.getState() 获取 state,然后返回 state.counter.value + 2 的值。
每当一个 action 被 dispatch 并且 Redux store 被更新时,useSelector 将重新运行我们的选择器函数。如果选择器返回的值与上次不同,useSelector 将确保我们的组件使用新值重新渲染。
类似地,我们知道如果我们可以访问 Redux store,可以 store.dispatch(increment())。
由于我们无法访问 store 本身,因此我们需要某种方式来访问 dispatch 方法。
useDispatch hook 为我们完成了这项工作,并从 Redux store 中为我们提供了实际的 dispatch 方法:
1 | const dispatch = useDispatch() |
在 React + Redux 应用中,你的全局状态应该放在 Redux store 中,你的本地状态应该保留在 React 组件中。
大多数表单的 state 不应该保存在 Redux 中。 相反,在编辑表单的时候把数据存到表单组件中,当用户提交表单的时候再 dispatch action 来更新 store。
我们已经看到我们的组件可以使用 useSelector 和 useDispatch 这两个 hook 与 Redux 的 store 通信。奇怪的是,我们并没有导入 store,那么这些 hooks 怎么知道要与哪个 Redux store 对话呢?
答案是使用 Context:
1 | import React from "react" |
我们可以使用 Redux Toolkit configureStore API 创建一个 Redux store
configureStore 接收 reducer 函数来作为命名参数configureStore 自动使用默认值来配置 store在 slice 文件中编写 Redux 逻辑
createSlice API 为你提供的每个 reducer 函数生成 action creator 和 action 类型Redux reducer 必须遵循以下原则
state 和 action 参数去计算出一个新 statecreateSlice API 内部使用了 Immer 库才达到表面上直接修改(”mutating”)state 也实现不可变更新(_immutable updates_)的效果一般使用 “thunks” 来开发特定的异步逻辑
dispatch 和 getState 作为参数redux-thunk 中间件使用 React-Redux 来做 React 组件和 Redux store 的通信
<Provider store={store}> 使得所有组件都能访问到 store官网下载 SecureCRT 9.3.2:https://www.vandyke.com/cgi-bin/account_login.php?pid=scrt_ubuntu2264_deb_932
安装:
1 | sudo dpkg -i scrt-9.3.2-2978.ubuntu22-64.x86_64.deb |
创建securecrt_linux_crack.pl 文件:
1 | #!/usr/bin/perl |
my $file = $ARGV[0];
open FP, $file or die “can not open file $!”;
binmode FP;
open TMPFP, ‘>’, ‘/tmp/.securecrt.tmp’ or die “can not open file $!”;
my $buffer;
my $unpack_data;
my $crack = 0;
while(read(FP, $buffer, 1024)) {
$unpack_data = unpack(‘H*’, $buffer);
if ($unpack_data =~ m/785782391ad0b9169f17415dd35f002790175204e3aa65ea10cff20818/) {
$crack = 1;
last;
}
if ($unpack_data =~ s/6e533e406a45f0b6372f3ea10717000c7120127cd915cef8ed1a3f2c5b/785782391ad0b9169f17415dd35f002790175204e3aa65ea10cff20818/ ){
$buffer = pack(‘H*’, $unpack_data);
$crack = 2;
}
syswrite(TMPFP, $buffer, length($buffer));
}
close(FP);
close(TMPFP);
if ($crack == 1) {
unlink ‘/tmp/.securecrt.tmp’ or die “can not delete files $!”;
print “It has been cracked\n”;
&license;
exit 1;
} elsif ($crack == 2) {
move ‘/tmp/.securecrt.tmp’, $file or die ‘Insufficient privileges, please switch the root account.’;
chmod 0755, $file or die ‘Insufficient privileges, please switch the root account.’;
print “crack successful\n”;
&license;
} else {
die ‘error’;
}
1 |
|
启动 SecureCRT 并输入 license,如果不成功,则随便百度一个 SecureCRT9.3.2 的 license 填上就行,如果百度搜不到,就用 windows 系统生成一个,因为 license 是通用的。
注意:不要直接用系统自带的应用商店安装。
http://www.sublimetext.com/docs/linux_repositories.html#apt
1 | gpg --dearmor | sudo tee /etc/apt/trusted.gpg.d/sublimehq-archive.gpg > /dev/null |
/opt/sublime_text/sublime_text80 78 05 00 0F 94 C1 并替换为 C6 40 05 01 48 85 C9/opt/sublime_text/sublime_texthttps://notabug.org/doublesine/navicat-keygen/src/linux/doc/how-to-use.zh-CN.md
https://notabug.org/doublesine/navicat-keygen/src/linux/doc/how-to-build.zh-CN.md
1 | sudo apt-get install cmake |
https://www.navicat.com/en/download/navicat-premium
1 | wget https://www.navicat.com/download/direct-download?product=navicat16-premium-en.AppImage&location=1 |
https://notabug.org/doublesine/navicat-keygen/src/linux/doc/how-to-use.zh-CN.md
1 | # 当前位于~/opt目录下 |
进入刚才编译安装好的 navicat-keygen/build 目录,使用 navicat-patcher 替换官方公钥:
1 | ./navicat-patcher ~/opt/navicat16-premium-cs-patched |
将文件重新打包成 AppImage:
1 | wget 'https://github.com/AppImage/AppImageKit/releases/download/continuous/appimagetool-x86_64.AppImage' |
运行刚生成的 AppImage:
1 | chmod +x ~/opt/navicat16-premium-en-patched.AppImage |
还是在 navicat-keygen/build 目录,navicat-keygen 来生成 序列号 和 激活码:
1 | ./navicat-keygen --text ./RegPrivateKey.pem |
你会被要求选择 Navicat 产品类别、Navicat 语言版本和填写主版本号。之后一个随机生成的 序列号 将会给出:
1 | *************************************************** |
你可以使用这个 序列号 来暂时激活 Navicat。
之后你会被要求填写 用户名 和 组织名。你可以随意填写,但别太长。
1 | [*] Your name: Double Sine |
之后你会被要求填写请求码。注意不要关闭 keygen。
激活。手动激活。1 | [*] Input request code in Base64: (Double press ENTER to end) |
最终你会得到一个 base64 编码的 激活码。
将之复制到 手动激活 的窗口,然后点击 激活。
如果没有什么意外,应该可以成功激活。
最后清理:
1 | $ rm ~/opt/navicat16-premium-cs.AppImage |
MDN:https://developer.mozilla.org/zh-CN/docs/Web/JavaScript/Reference/Global_Objects/Proxy
Proxy 对象用于创建一个对象的代理,从而实现基本操作的拦截和自定义(如属性查找、赋值、枚举、函数调用等)。
1 | const p = new Proxy(target, handler) |
target:要使用Proxy包装的目标对象(可以是任何类型的对象,包括原生数组、函数、甚至另一个代理)。handler:一个通常以函数作为属性的对象,各属性中的函数分别定义了在执行各种操作时代理p的行为。1 | Proxy.revocable() |
创建一个可撤销的Proxy对象。
handler对象是一个容纳一批特定属性的占位符对象。它包含有Proxy的各个捕获器(trap)。
所有的捕获器是可选的。如果没有定义某个捕获器,那么就会保留源对象的默认行为。
handler.getPrototypeOf() 是一个代理(Proxy)方法,当读取代理对象的原型时,该方法就会被调用。
1 | const monster1 = { |
handler.setPrototypeOf() 方法主要用来拦截 Object.setPrototypeOf().
1 | const p = new Proxy(target, { |
handler.isExtensible() 方法用于拦截对对象的 Object.isExtensible()。
1 | const monster1 = { |
handler.preventExtensions() 方法用于设置对Object.preventExtensions()的拦截。
Object.preventExtensions()方法让一个对象变的不可扩展,也就是永远不能再添加新的属性。
1 | var p = new Proxy(target, { |
1 | const monster1 = { |
handler.getOwnPropertyDescriptor() 方法是 Object.getOwnPropertyDescriptor() 的钩子。
1 | var p = new Proxy(target, { |
1 | const p = new Proxy({ a: 20 }, { |
handler.defineProperty() 用于拦截对象的 Object.defineProperty() 操作。
vue2的双向绑定就是通过 Object.defineProperty() 实现的。
1 | var p = new Proxy(target, { |
handler.has() 方法是针对 in 操作符的代理方法。
示例,_开头的属性为私有属性,使用in判断的时候返回false:
1 | const handler1 = { |
handler.get() 方法用于拦截对象的读取属性操作。
1 | var p = new Proxy(target, { |
1 | const p = new Proxy({ a: 10 }, { |
handler.set() 方法是设置属性值操作的捕获器。
1 | const p = new Proxy(target, { |
1 | const monster1 = { eyeCount: 4 }; |
handler.deleteProperty() 方法用于拦截对对象属性的 delete 操作。
1 | var p = new Proxy(target, { |
handler.ownKeys() 方法用于拦截 Reflect.ownKeys().
1 | const monster1 = { |
handler.apply() 方法用于拦截函数的调用。
1 | const sum = (a, b) => a + b |
handler.construct() 方法用于拦截 new 操作符。为了使 new 操作符在生成的 Proxy 对象上生效,用于初始化代理的目标对象自身必须具有 [[Construct]] 内部方法(即 new target 必须是有效的)。
1 | function sum(a, b) { |
上例中,sum不能是只能是普通函数,不能是箭头函数,因为箭头函数不能new。
{{}}不能在 HTML attributes 中使用。想要响应式的绑定一个 attribute,应该使用v-bind指令是:
1 | <div v-bind:id="dynamicId"></div> |
因为v-bind非常常用,我们提供了特定的简写语法:
1 | <div :id="dynamicId"></div> |
实际上,vue 在所有的数据绑定中都支持完整的 js 表达式。
每个帮顶仅支持单一表达式,也就是一段能够被求值的 js 代码。一个简单的判断是是否可以合法的写在return后面。
绑定在表达式中的方法在组件每次更新时都会被重新调用,因此不应该产生任何副作用,比如改变数据或触发异步操作。
受限的全局访问:
模板中的表达式将被沙盒化,仅能够访问到有限的全局对象列表。该列表中会暴露常用的内置全局对象,比如 Math 和 Date。
没有显式包含在列表中的全局对象将不能在模板内表达式中访问,例如用户附加在 window 上的属性。然而,你也可以自行在 app.config.globalProperties 上显式地添加它们,供所有的 Vue 表达式使用。
指令是带有v-前缀的特殊 attribute,vue 提供了许多内置指令,包括上面提到的v-bind。
指令 attribute 的期望值是一个 js 表达式(除了v-for、v-on、v-slot 这几个少数的例外)。一个指令的任务是在其表达式的值变化时响应式地更新 DOM。
以v-if为例:
1 | <p v-if="seen">Now you see me</p> |
这里,v-if 指令会基于表达式 seen 的值的真假来移除/插入该 <p> 元素。
reactive()我们可以使用 reactive() 函数创建一个响应式对象或数组:
1 | import { reactive } from "vue" |
<script setup>要在组件模板中使用响应式状态,需要在 setup() 函数中定义并返回。
1 | <script> |
在 setup() 函数中手动暴露大量的状态和方法非常繁琐。幸运的是,我们可以通过使用构建工具来简化该操作。当使用单文件组件(SFC)时,我们可以使用 <script setup> 来大幅度地简化代码。
1 | <script setup> |
<script setup> 中的顶层的导入和变量声明可在同一组件的模板中直接使用。你可以理解为模板中的表达式和 <script setup> 中的代码处在同一个作用域中。
当你更改响应式状态后,DOM 会自动更新。然而,你得注意 DOM 的更新并不是同步的。相反,Vue 将缓冲它们直到更新周期的 “下个时机” 以确保无论你进行了多少次状态更改,每个组件都只更新一次。
若要等待一个状态改变后的 DOM 更新完成,你可以使用 nextTick() 这个全局 API:
1 | import { nextTick } from "vue" |
在 Vue 中,状态都是默认深层响应式的。这意味着即使在更改深层次的对象或数组,你的改动也能被检测到。
1 | import { reactive } from "vue" |
你也可以直接创建一个浅层响应式对象。它们仅在顶层具有响应性,一般仅在某些特殊场景中需要。
值得注意的是,reactive() 返回的是一个原始对象的 Proxy,它和原始对象是不相等的:
1 | const raw = {} |
只有代理对象是响应式的,更改原始对象不会触发更新。因此,使用 vue 的响应式系统的最佳实践是 仅使用你声明对象的代理版本。
为保证访问代理的一致性,对同一个原始对象调用reactive()总是返回同样的代理对象,而对一个已存在的代理对象调用reactive()会返回其本身:
1 | // 在同一个对象上调用 reactive() 会返回相同的代理 |
这个规则对嵌套对象也适用。依靠深层响应性,响应式对象内的嵌套对象依然是代理:
1 | const proxy = reactive({}) |
reactive()的局限性因为 js 没有可以作用于所有值类型的“引用”机制。所以reactive() API 有两条限制:
Map、Set 这样的集合类型),而对 string、number 和 boolean 这样的 原始类型 无效。1 | let state = reactive({ count: 0 }) |
同时这也意味着当我们将响应式对象的属性赋值或解构至本地变量时,或是将该属性传入一个函数时,我们会失去响应性:
1 | const state = reactive({ count: 0 }) |
ref()js 没有可以作用于所有值类型的“引用”机制,为此,vue 提供了一个ref()方法来允许我们创建可以使用任何值类型的响应式 ref:
1 | import { ref } from "vue" |
ref()将传入参数的值包装为一个带.value属性的 ref 对象:
1 | const count: Ref<number> = ref(0) |
和响应式对象的属性类似,ref 的 .value 属性也是响应式的。同时,当值为对象类型时,会用 reactive() 自动转换它的 .value。
一个包含对象类型值的 ref 可以响应式地替换整个对象:
1 | const objectRef = ref({ count: 0 }) |
ref 被传递给函数或是从一般对象上被解构时,不会丢失响应性:
1 | const obj = { |
简言之,ref() 让我们能创造一种对任意值的 “引用”,并能够在不丢失响应性的前提下传递这些引用。这个功能很重要,因为它经常用于将逻辑提取到 组合函数 中。
当 ref 在模板中作为顶层属性被访问时,它们会自动“解包”,所以不需要使用.value,示例:
1 | <script setup> |
请注意,仅当 ref 是模板渲染上下文的顶层属性时才适用自动“解包”。 例如:
1 | const object = { foo: ref(1) } |
下面的表达式将不会像预期的那样工作:
1 | { |
因为此时 ref 所在的上下文是object而不是模板。我们可以将foo提取出来,这样 ref 的上下文就是模板了:
1 | const { foo } = object |
1 | { |
需要注意的是,如果是下面这种情况,直接渲染,不参与计算,则也会被自动解包:
1 | { |
当一个ref被嵌套在一个响应式对象中,作为属性被访问或更改时,它会自动解包,因此会表现的和一般属性一样:
1 | const count = ref(0) |
如果将一个新的 ref 赋值给一个关联了已有 ref 的属性,那么它会替换掉旧的 ref:
1 | const otherCount = ref(2) |
只有当嵌套在一个深层响应式对象内时,才会发生 ref 解包,当其作为浅层响应式对象的属性被访问时不会解包。
跟响应式对象不同,当 ref 作为响应式数组或像 Map 这种原生集合类型的元素被访问时,不会进行解包。
1 | const books = reactive([ref("Vue 3 Guide")]) |
1 | <script lang="ts" setup> |
我们在这里定义了一个计算属性 publishedBooksMessage。computed() 方法期望接收一个 getter 函数,返回值为一个计算属性 ref。和其他一般的 ref 类似,你可以通过 publishedBooksMessage.value 访问计算结果。计算属性 ref 也会在模板中自动解包,因此在模板表达式中引用时无需添加 .value。
vue 的计算属性会自动追踪响应式依赖。它会检测到 publishedBooksMessage 依赖于 author.books,所以当 author.books 改变时,任何依赖于 publishedBooksMessage 的绑定都会同时更新。
你可能注意到我们在表达式中像这样调用一个函数也会获得和计算属性相同的结果:
1 | <p>{{ calculateBooksMessage() }}</p> |
1 | // 组件中 |
若我们将同样的函数定义为一个方法而不是计算属性,两种方式在结果上确实是完全相同的,然而,不同之处在于计算属性值会基于其响应式依赖被缓存。一个计算属性仅会在其响应式依赖更新时才重新计算。这意味着只要 author.books 不改变,无论多少次访问 publishedBooksMessage 都会立即返回先前的计算结果,而不用重复执行 getter 函数。
这也解释了为什么下面的计算属性永远不会更新,因为 Date.now() 并不是一个响应式依赖:
1 | const now = computed(() => Date.now()) |
相比之下,方法调用总是会在重渲染发生时再次执行函数。
为什么需要缓存呢?想象一下我们有一个非常耗性能的计算属性 list,需要循环一个巨大的数组并做许多计算逻辑,并且可能也有其他计算属性依赖于 list。没有缓存的话,我们会重复执行非常多次 list 的 getter,然而这实际上没有必要!如果你确定不需要缓存,那么也可以使用方法调用。
计算属性默认是只读的。当你尝试修改一个计算属性时,你会收到一个运行时警告。只在某些特殊场景中你可能才需要用到“可写”的属性,你可以通过同时提供 getter 和 setter 来创建:
1 | <script setup> |
现在当你再运行 fullName.value = 'John Doe' 时,setter 会被调用而 firstName 和 lastName 会随之更新。
计算属性的 getter 应只做计算而没有任何其他的副作用,这一点非常重要,请务必牢记。举例来说,不要在 getter 中做异步请求或者更改 DOM!一个计算属性的声明中描述的是如何根据其他值派生一个值。因此 getter 的职责应该仅为计算和返回该值。在之后的指引中我们会讨论如何使用监听器根据其他响应式状态的变更来创建副作用。
从计算属性返回的值是派生状态。可以把它看作是一个“临时快照”,每当源状态发生变化时,就会创建一个新的快照。更改快照是没有意义的,因此计算属性的返回值应该被视为只读的,并且永远不应该被更改——应该更新它所依赖的源状态以触发新的计算。
因为 class 和 style 都是 attribute,我们可以和其他 attribute 一样使用 v-bind 将它们和动态的字符串绑定。但是,在处理比较复杂的绑定时,通过拼接生成字符串是麻烦且易出错的。因此,Vue 专门为 class 和 style 的 v-bind 用法提供了特殊的功能增强。除了字符串外,表达式的值也可以是对象或数组。
:class 是 v-bind:class 的缩写。
1 | <div :class="{ active: isActive }"></div> |
也可以直接绑定一个对象:
1 | const classObject = reactive({ |
1 | <div :class="classObject"></div> |
也可以绑定一个返回对象的计算属性。这是一个常见且很有用的技巧:
1 | const isActive = ref(true) |
1 | <div :class="classObject"></div> |
我们可以给 :class 绑定一个数组来渲染多个 CSS class:
1 | const activeClass = ref("active") |
1 | <div :class="[activeClass, errorClass]"></div> |
渲染的结果是:
1 | <div class="active text-danger"></div> |
如果你也想在数组中有条件地渲染某个 class,你可以使用三元表达式:
1 | <div :class="[isActive ? activeClass : '', errorClass]"></div> |
然而,这可能在有多个依赖条件的 class 时会有些冗长。因此也可以在数组中嵌套对象:
1 | <div :class="[{ active: isActive }, errorClass]"></div> |
1 | <!-- 子组件模板 --> |
1 | const activeColor = ref("red") |
1 | <div :style="{ 'font-size': fontSize + 'px' }"></div> |
直接绑定一个样式对象通常是一个好主意,这样可以使模板更加简洁:
1 | const styleObject = reactive({ |
1 | <div :style="styleObject"></div> |
同样的,如果样式对象需要更复杂的逻辑,也可以使用返回样式对象的计算属性。
我们还可以给 :style 绑定一个包含多个样式对象的数组。这些对象会被合并后渲染到同一元素上:
1 | <div :style="[baseStyles, overridingStyles]"></div> |
v-if1 | <div v-if="type === 'A'">A</div> |
一个 v-else 元素必须跟在一个 v-if 或者 v-else-if 元素后面,否则它将不会被识别。
v-if、v-else 和 v-else-if 也可以在 <template> 上使用。
1 | <template v-if="ok"> |
v-show另一个可以用来按条件显示一个元素的指令是 v-show。其用法基本一样:
1 | <h1 v-show="ok">Hello!</h1> |
不同之处在于 v-show 会在 DOM 渲染中保留该元素;v-show 仅切换了该元素上名为 display 的 CSS 属性。
v-show 不支持在 <template> 元素上使用,也不能和 v-else 搭配使用。
v-if 和 v-showv-if 是“真实的”按条件渲染,因为它确保了在切换时,条件区块内的事件监听器和子组件都会被销毁与重建。
v-if 也是惰性的:如果在初次渲染时条件值为 false,则不会做任何事。条件区块只有当条件首次变为 true 时才被渲染。
相比之下,v-show 简单许多,元素无论初始条件如何,始终会被渲染,只有 CSS display 属性会被切换。
总的来说,v-if 有更高的切换开销,而 v-show 有更高的初始渲染开销。因此,如果需要频繁切换,则使用 v-show 较好;如果在运行时绑定条件很少改变,则 v-if 会更合适。
v-for1 | const items = ref([{ message: "Foo" }, { message: "Bar" }]) |
1 | <li v-for="item in items">{{ item.message }}</li> |
你也可以使用 of 作为分隔符来替代 in,这更接近 JavaScript 的迭代器语法:
1 | <div v-for="item of items"></div> |
v-for 与对象你也可以使用 v-for 来遍历一个对象的所有属性。遍历的顺序会基于对该对象调用 Object.keys() 的返回值来决定。
1 | const myObject = reactive({ |
1 | <ul> |
v-for 可以直接接受一个整数值。在这种用例中,会将该模板基于 1...n 的取值范围重复多次。
1 | <span v-for="n in 10">{{ n }}</span> |
注意此处 n 的初值是从 1 开始而非 0。
<template> 上的 v-for与模板上的 v-if 类似,你也可以在 <template> 标签上使用 v-for 来渲染一个包含多个元素的块。例如:
1 | <ul> |
v-for 和 v-if警告:
同时使用
v-if和v-for是不推荐的,因为这样二者的优先级不明显。请查看风格指南获得更多信息。
当它们同时存在于一个节点上时,v-if 比 v-for 的优先级更高。这意味着 v-if 的条件将无法访问到 v-for 作用域内定义的变量别名:
1 | <!-- |
在外新包装一层 <template> 再在其上使用 v-for 可以解决这个问题 (这也更加明显易读):
1 | <template v-for="todo in todos"> |
vue 默认按照“就地更新”的策略来更新通过 v-for 渲染的元素列表。当数据项的顺序改变时,vue 不会随之移动 DOM 元素的顺序,而是就地更新每个元素,确保它们在原本指定的索引位置上渲染。
默认模式是高效的,但只适用于列表渲染输出的结果不依赖子组件状态或者临时 DOM 状态 (例如表单输入值) 的情况。
为了给 vue 一个提示,以便它可以跟踪每个节点的标识,从而重用和重新排序现有的元素,你需要为每个元素对应的块提供一个唯一的 key attribute:
1 | <div v-for="item in items" :key="item.id"> |
当你使用 <template v-for> 时,key 应该被放置在这个 <template> 容器上:
1 | <template v-for="todo in todos" :key="todo.name"> |
注意:key 在这里是一个通过 v-bind 绑定的特殊 attribute。请不要和在 v-for 中使用对象里所提到的对象属性名相混淆。
推荐在任何可行的时候为 v-for 提供一个 key attribute,除非所迭代的 DOM 内容非常简单 (例如:不包含组件或有状态的 DOM 元素),或者你想有意采用默认行为来提高性能。
key 绑定的值期望是一个基础类型的值,例如字符串或 number 类型。不要用对象作为 v-for 的 key。关于 key attribute 的更多用途细节,请参阅 key API 文档。
v-for我们可以直接在组件上使用 v-for,和在一般的元素上使用没有区别 (别忘记提供一个 key):
1 | <MyComponent v-for="item in items" :key="item.id" /> |
但是,这不会自动将任何数据传递给组件,因为组件有自己独立的作用域。为了将迭代后的数据传递到组件中,我们还需要传递 props:
1 | <MyComponent v-for="(item, index) in items" :item="item" :index="index" :key="item.id" /> |
不自动将 item 注入组件的原因是,这会使组件与 v-for 的工作方式紧密耦合。明确其数据的来源可以使组件在其他情况下重用。
vue 能够侦听响应式数组的变更方法,并在它们被调用时触发相关的更新。这些变更方法包括:
push()pop()shift()unshift()splice()sort()reverse()变更方法,顾名思义,就是会对调用它们的原数组进行变更。相对地,也有一些不可变 (immutable) 方法,例如 filter(),concat() 和 slice(),这些都不会更改原数组,而总是返回一个新数组。当遇到的是非变更方法时,我们需要将旧的数组替换为新的:
1 | // `items` 是一个数组的 ref |
你可能认为这将导致 vue 丢弃现有的 DOM 并重新渲染整个列表——幸运的是,情况并非如此。vue 实现了一些巧妙的方法来最大化对 DOM 元素的重用,因此用另一个包含部分重叠对象的数组来做替换,仍会是一种非常高效的操作。
有时,我们希望显示数组经过过滤或排序后的内容,而不实际变更或重置原始数据。在这种情况下,你可以创建返回已过滤或已排序数组的计算属性。
举例:
1 | const numbers = ref([1, 2, 3, 4, 5]) |
1 | <li v-for="n in evenNumbers">{{ n }}</li> |
在计算属性不可行的情况下 (例如在多层嵌套的 v-for 循环中),你可以使用以下方法:
1 | const sets = ref([ |
1 | <ul v-for="numbers in sets"> |
在计算属性中使用 reverse() 和 sort() 的时候务必小心!这两个方法将变更原始数组,计算函数中不应该这么做。请在调用这些方法之前创建一个原数组的副本:
1 | - return numbers.reverse() |
我们可以使用 v-on 指令 (简写为 @) 来监听 DOM 事件,并在事件触发时执行对应的 JavaScript。用法:v-on:click="methodName" 或 @click="handler"。
事件处理器的值可以是:
onclick 类似)。内联事件处理器通常用于简单场景,例如:
1 | const count = ref(0) |
1 | <button @click="count++">Add 1</button> |
随着事件处理器的逻辑变得愈发复杂,内联代码方式变得不够灵活。因此 v-on 也可以接受一个方法名或对某个方法的调用。
举例:
1 | const name = ref("Vue.js") |
1 | <!-- `greet` 是上面定义过的方法名 --> |
方法事件处理器会自动接收原生 DOM 事件并触发执行。在上面的例子中,我们能够通过被触发事件的 event.target.tagName 访问到该 DOM 元素。
模板编译器会通过检查 v-on 的值是否是合法的 JavaScript 标识符或属性访问路径来断定是何种形式的事件处理器。举例来说,foo、foo.bar 和 foo['bar'] 会被视为方法事件处理器,而 foo() 和 count++ 会被视为内联事件处理器。
除了直接绑定方法名,你还可以在内联事件处理器中调用方法。这允许我们向方法传入自定义参数以代替原生事件:
1 | function say(message) { |
1 | <button @click="say('hello')">Say hello</button> <button @click="say('bye')">Say bye</button> |
有时我们需要在内联事件处理器中访问原生 DOM 事件。你可以向该处理器方法传入一个特殊的 $event 变量,或者使用内联箭头函数:
1 | <!-- 使用特殊的 $event 变量 --> |
1 | function warn(message, event) { |
在处理事件时调用 event.preventDefault() 或 event.stopPropagation() 是很常见的。尽管我们可以直接在方法内调用,但如果方法能更专注于数据逻辑而不用去处理 DOM 事件的细节会更好。
为解决这一问题,Vue 为 v-on 提供了事件修饰符。修饰符是用 . 表示的指令后缀,包含以下这些:
.stop.prevent.self.capture.once.passive1 | <!-- 单击事件将停止传递 --> |
使用修饰符时需要注意调用顺序,因为相关代码是以相同的顺序生成的。因此使用 @click.prevent.self 会阻止元素及其子元素的所有点击事件的默认行为,而 @click.self.prevent 则只会阻止对元素本身的点击事件的默认行为。
.capture、.once 和 .passive 修饰符与原生 addEventListener 事件相对应:
1 | <!-- 添加事件监听器时,使用 `capture` 捕获模式 --> |
.passive 修饰符一般用于触摸事件的监听器,可以用来改善移动端设备的滚屏性能。
请勿同时使用 .passive 和 .prevent,因为 .passive 已经向浏览器表明了你不想阻止事件的默认行为。如果你这么做了,则 .prevent 会被忽略,并且浏览器会抛出警告。
在监听键盘事件时,我们经常需要检查特定的按键。Vue 允许在 v-on 或 @ 监听按键事件时添加按键修饰符。
1 | <!-- 仅在 `key` 为 `Enter` 时调用 `submit` --> |
你可以直接使用 KeyboardEvent.key 暴露的按键名称作为修饰符,但需要转为 kebab-case 形式。
1 | <input @keyup.page-down="onPageDown" /> |
在上面的例子中,仅会在 $event.key 为 'PageDown' 时调用事件处理。
Vue 为一些常用的按键提供了别名:
.enter.tab.delete (捕获“Delete”和“Backspace”两个按键).esc.space.up.down.left.right你可以使用以下系统按键修饰符来触发鼠标或键盘事件监听器,只有当按键被按下时才会触发。
.ctrl.alt.shift.meta在 Mac 键盘上,meta 是 Command 键 (⌘)。在 Windows 键盘上,meta 键是 Windows 键 (⊞)。在 Sun 微机系统键盘上,meta 是钻石键 (◆)。在某些键盘上,特别是 MIT 和 Lisp 机器的键盘及其后代版本的键盘,如 Knight 键盘,space-cadet 键盘,meta 都被标记为“META”。在 Symbolics 键盘上,meta 也被标识为“META”或“Meta”。
1 | <!-- Alt + Enter --> |
请注意,系统按键修饰符和常规按键不同。与 keyup 事件一起使用时,该按键必须在事件发出时处于按下状态。换句话说,keyup.ctrl 只会在你仍然按住 ctrl 但松开了另一个键时被触发。若你单独松开 ctrl 键将不会触发。
.exact修饰符.exact 修饰符允许控制触发一个事件所需的确定组合的系统按键修饰符。
1 | <!-- 当按下 Ctrl 时,即使同时按下 Alt 或 Shift 也会触发 --> |
.left.right.middle这些修饰符将处理程序限定为由特定鼠标按键触发的事件。
在前端处理表单时,我们常常需要将表单输入框的内容同步给 JavaScript 中相应的变量。手动连接值绑定和更改事件监听器可能会很麻烦:
1 | <input |
v-model 指令帮我们简化了这一步骤:
1 | <input v-model="text"> |
注意:
v-model会忽略任何表单元素上初始的value、checked或selectedattribute。它将始终将当前绑定的 JavaScript 状态视为数据的正确来源。你应该在 JavaScript 中使用响应式系统的 API 来声明该初始值。
有时我们可能希望将该值绑定到当前组件实例上的动态数据。这可以通过使用 v-bind 来实现。此外,使用 v-bind 还使我们可以将选项值绑定为非字符串的数据类型。
1 | <input type="checkbox" v-model="toggle" true-value="yes" false-value="no" /> |
true-value 和 false-value 是 Vue 特有的 attributes,仅支持和 v-model 配套使用。这里 toggle 属性的值会在选中时被设为 'yes',取消选择时设为 'no'。你同样可以通过 v-bind 将其绑定为其他动态值:
1 | <input type="checkbox" v-model="toggle" :true-value="dynamicTrueValue" :false-value="dynamicFalseValue" /> |
提示:
true-value和false-valueattributes 不会影响valueattribute,因为浏览器在表单提交时,并不会包含未选择的复选框。为了保证这两个值 (例如:“yes”和“no”) 的其中之一被表单提交,请使用单选按钮作为替代。
.lazy默认情况下,v-model 会在每次 input 事件后更新数据 (IME 拼字阶段的状态例外)。你可以添加 lazy 修饰符来改为在每次 change 事件后更新数据:
1 | <!-- 在 "change" 事件后同步更新而不是 "input" --> |
.number如果你想让用户输入自动转换为数字,你可以在 v-model 后添加 .number 修饰符来管理输入:
1 | <input v-model.number="age" /> |
如果该值无法被 parseFloat() 处理,那么将返回原始值。
number 修饰符会在输入框有 type="number" 时自动启用。
.trim如果你想要默认自动去除用户输入内容中两端的空格,你可以在 v-model 后添加 .trim 修饰符:
1 | <input v-model.trim="msg" /> |
v-modelHTML 的内置表单输入类型并不总能满足所有需求。幸运的是,我们可以使用 Vue 构建具有自定义行为的可复用输入组件,并且这些输入组件也支持 v-model!要了解更多关于此的内容,请在组件指引中阅读配合 v-model 使用。
每个 Vue 组件实例在创建时都需要经历一系列的初始化步骤,比如设置好数据侦听,编译模板,挂载实例到 DOM,以及在数据改变时更新 DOM。在此过程中,它也会运行被称为生命周期钩子的函数,让开发者有机会在特定阶段运行自己的代码。
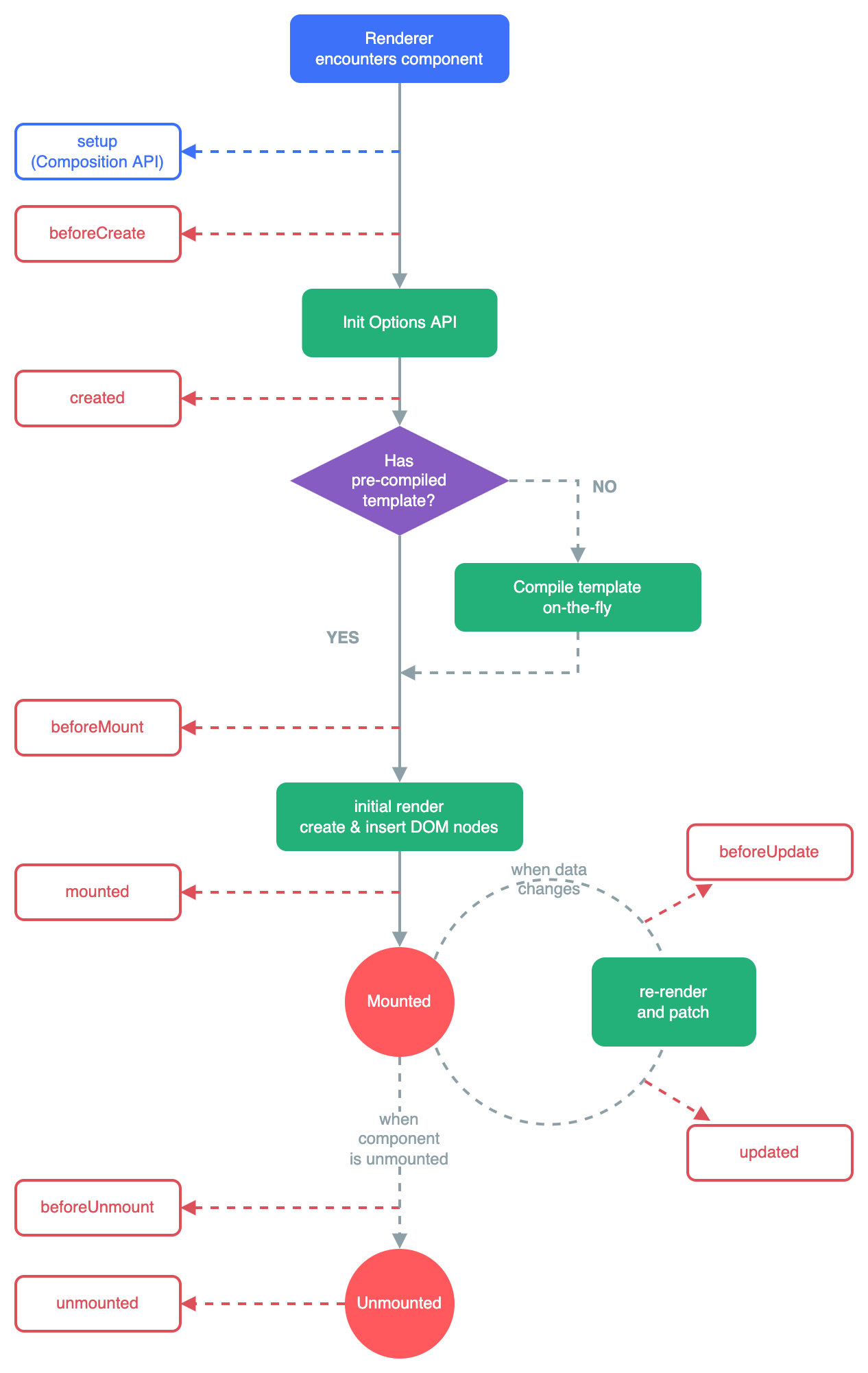
计算属性允许我们声明性地计算衍生值。然而在有些情况下,我们需要在状态变化时执行一些“副作用”:例如更改 DOM,或是根据异步操作的结果去修改另一处的状态。
有“副作用”,使用侦听器;没有“副作用”,使用计算属性。
watch()在组合式 API 中,我们可以使用 watch 函数在每次响应式状态发生变化时触发回调函数:
1 | <script setup> |
watch 的第一个参数可以是不同形式的“数据源”:它可以是一个 ref (包括计算属性)、一个响应式对象、一个 getter 函数、或多个数据源组成的数组:
1 | const x = ref(0) |
注意,你不能直接侦听响应式对象的属性值,例如:
1 | const obj = reactive({ count: 0 }) |
这里需要用一个返回该属性的 getter 函数:
1 | // 提供一个 getter 函数 |
直接给 watch() 传入一个响应式对象,会隐式地创建一个深层侦听器——该回调函数在所有嵌套的变更时都会被触发:
1 | const obj = reactive({ count: 0 }) |
相比之下,一个返回响应式对象的 getter 函数,只有在返回不同的对象时,才会触发回调:
1 | watch( |
你也可以给上面这个例子显式地加上 deep 选项,强制转成深层侦听器:
1 | watch( |
谨慎使用:
深度侦听需要遍历被侦听对象中的所有嵌套的属性,当用于大型数据结构时,开销很大。因此请只在必要时才使用它,并且要留意性能。
watch 默认是懒执行的:仅当数据源变化时,才会执行回调。但在某些场景中,我们希望在创建侦听器时,立即执行一遍回调。举例来说,我们想请求一些初始数据,然后在相关状态更改时重新请求数据。
我们可以通过传入 immediate: true 选项来强制侦听器的回调立即执行:
1 | watch( |
watchEffect()下面的例子中,在每当 todoId 的引用发生变化时使用侦听器来加载一个远程资源:
1 | const todoId = ref(1) |
侦听的数据源是todoId,而回调中也使用到了todoId,这种情况是很常见的。
我们可以用 watchEffect 函数 来简化上面的代码。watchEffect() 允许我们自动跟踪回调的响应式依赖。上面的侦听器可以重写为:
1 | watchEffect(async () => { |
这个例子中,回调会立即执行,不需要指定 immediate: true。在执行期间,它会自动追踪 todoId.value 作为依赖(和计算属性类似)。每当 todoId.value 变化时,回调会再次执行。有了 watchEffect(),我们不再需要明确传递 todoId 作为源值。
对于这种只有一个依赖项的例子来说,watchEffect() 的好处相对较小。但是对于有多个依赖项的侦听器来说,使用 watchEffect() 可以消除手动维护依赖列表的负担。此外,如果你需要侦听一个嵌套数据结构中的几个属性,watchEffect() 可能会比深度侦听器更有效,因为它将只跟踪回调中被使用到的属性,而不是递归地跟踪所有的属性。
提示:
watchEffect仅会在其同步执行期间,才追踪依赖。在使用异步回调时,只有在第一个await正常工作前访问到的属性才会被追踪。
watch 和 watchEffectwatch 和 watchEffect 都能响应式地执行有副作用的回调。它们之间的主要区别是追踪响应式依赖的方式:
watch 只追踪明确侦听的数据源。它不会追踪任何在回调中访问到的东西。另外,仅在数据源确实改变时才会触发回调。watch 会避免在发生副作用时追踪依赖,因此,我们能更加精确地控制回调函数的触发时机。watchEffect,则会在副作用发生期间追踪依赖。它会在同步执行过程中,自动追踪所有能访问到的响应式属性。这更方便,而且代码往往更简洁,但有时其响应性依赖关系会不那么明确。当你更改了响应的状态,它可能会同时触发 vue 组件更新和侦听器回调。
默认情况下,用户创建的侦听器回调,都会在 vue 组件更新之前被调用。这意味着你在侦听器回调中访问的 DOM 将是被 vue 更新的状态。
如果想在侦听器回调中能访问被 vue 更新之后的 DOM,你需要指明flush 'post'选项:
1 | watch(source, callback, { |
后置刷新的watchEffect()有个更方便的别名watchPostEffect():
1 | import { watchPostEffect } from "vue" |
在 setup() 或 <script setup> 中用同步语句创建的侦听器,会自动绑定到宿主组件实例上,并且会在宿主组件卸载时自动停止。因此,在大多数情况下,你无需关心怎么停止一个侦听器。
一个关键点是,侦听器必须用同步语句创建:如果用异步回调创建一个侦听器,那么它不会绑定到当前组件上,你必须手动停止它,以防内存泄漏。如下方这个例子:
1 | <script setup> |
要手动停止一个侦听器,请调用 watch 或 watchEffect 返回的函数:
1 | const unwatch = watchEffect(() => {}) |
注意,需要异步创建侦听器的情况很少,请尽可能选择同步创建。如果需要等待一些异步数据,你可以使用条件式的侦听逻辑:
1 | // 需要异步请求得到的数据 |
虽然 Vue 的声明性渲染模型为你抽象了大部分对 DOM 的直接操作,但在某些情况下,我们仍然需要直接访问底层 DOM 元素。要实现这一点,我们可以使用特殊的 ref attribute:
1 | <input ref="input"> |
ref 是一个特殊的 attribute,和 v-for 章节中提到的 key 类似。它允许我们在一个特定的 DOM 元素或子组件实例被挂载后,获得对它的直接引用。这可能很有用,比如说在组件挂载时将焦点设置到一个 input 元素上,或在一个元素上初始化一个第三方库。
为了通过组合式 API 获得该模板引用,我们需要声明一个同名的 ref:
1 | <script setup> |
注意,你只可以在组件挂载后才能访问模板引用。如果你想在模板中的表达式上访问 input,在初次渲染时会是 null。这是因为在初次渲染前这个元素还不存在呢!
如果你需要侦听一个模板引用 ref 的变化,确保考虑到其值为 null 的情况:
1 | watchEffect(() => { |
v-for中的模板引用当在 v-for 中使用模板引用时,对应的 ref 中包含的值是一个数组,它将在元素被挂载后包含对应整个列表的所有元素:
1 | <script setup> |
应该注意的是,ref 数组并不保证与源数组相同的顺序。
除了使用字符串值作名字,ref attribute 还可以绑定为一个函数,会在每次组件更新时都被调用。该函数会收到元素引用作为其第一个参数:
1 | <input :ref="(el) => { /* 将 el 赋值给一个数据属性或 ref 变量 */ }" /> |
注意我们这里需要使用动态的 :ref 绑定才能够传入一个函数。当绑定的元素被卸载时,函数也会被调用一次,此时的 el 参数会是 null。你当然也可以绑定一个组件方法而不是内联函数。
模板引用也可以被用在一个子组件上。这种情况下引用中获得的值是组件实例:
1 | <script setup> |
如果一个子组件使用的是选项式 API 或没有使用 <script setup>,被引用的组件实例和该子组件的 this 完全一致,这意味着父组件对子组件的每一个属性和方法都有完全的访问权。这使得在父组件和子组件之间创建紧密耦合的实现细节变得很容易,当然也因此,应该只在绝对需要时才使用组件引用。大多数情况下,你应该首先使用标准的 props 和 emit 接口来实现父子组件交互。
有一个例外的情况,使用了 <script setup> 的组件是默认私有的:一个父组件无法访问到一个使用了 <script setup> 的子组件中的任何东西,除非子组件在其中通过 defineExpose 宏显式暴露:
1 | <script setup> |
当父组件通过模板引用获取到了该组件的实例时,得到的实例类型为 { a: number, b: number } (ref 都会自动解包,和一般的实例一样)。
props 是一种特别的 attributes,你可以在组件上声明注册。要传递给博客文章组件一个标题,我们必须在组件的 props 列表上声明它。这里要用到 defineProps 宏:
1 | <!-- BlogPost.vue --> |
defineProps 是一个仅 <script setup> 中可用的编译宏命令,并不需要显式地导入。声明的 props 会自动暴露给模板。defineProps 会返回一个对象,其中包含了可以传递给组件的所有 props:
1 | const props = defineProps(["title"]) |
父组件可以通过 v-on 或 @ 来选择性地监听子组件上抛的事件,就像监听原生 DOM 事件那样:
1 | <BlogPost ... @enlarge-text="postFontSize += 0.1" /> |
子组件可以通过调用内置的 $emit 方法,通过传入事名称来抛出一个事件:
1 | <!-- BlogPost.vue, 省略了 <script> --> |
因为有了 @enlarge-text="postFontSize += 0.1" 的监听,父组件会接收这一事件,从而更新 postFontSize 的值。
我们可以通过 defineEmits 宏来声明需要抛出的事件:
1 | <!-- BlogPost.vue --> |
这声明了一个组件可能触发的所有事件,还可以对事件的参数进行验证。同时,这还可以让 Vue 避免将它们作为原生事件监听器隐式地应用于子组件的根元素。
和 defineProps 类似,defineEmits 仅可用于 <script setup> 之中,并且不需要导入,它返回一个等同于 $emit 方法的 emit 函数。它可以被用于在组件的 <script setup> 中抛出事件,因为此处无法直接访问 $emit:
1 | <script setup> |
一个 Vue 组件在使用前需要先被“注册”,这样 Vue 才能在渲染模板时找到其对应的实现。组件注册有两种方式:全局注册和局部注册。
我们可以使用 Vue 应用实例的 app.component() 方法,让组件在当前 Vue 应用中全局可用。
1 | import MyComponent from "./App.vue" |
app.component() 方法可以被链式调用:
1 | app.component("ComponentA", ComponentA).component("ComponentB", ComponentB).component("ComponentC", ComponentC) |
全局注册的组件可以在此应用的任意组件的模板中使用。并且相互可以在彼此内部使用。
局部注册的组件需要在使用它的父组件中显式导入,并且只能在该父组件中使用。它的优点是使组件之间的依赖关系更加明确,并且对 tree-shaking 更加友好。
在 SFC 中,推荐为子组件使用PascalCase的标签名,以此来和原声的 HTML 元素作区分。
但是,PascalCase 的标签名在 DOM 模板中是不可用的,详情参见 DOM 模板解析注意事项,在这种情况下,需要使用 kebab-case 形式。
什么是 DOM 模板?就是直接写在 DOM 中的模板,会被浏览器直接解析:
1 |
|
<my-component></my-component> 就是 DOM 模板。
一个组件需要显式声明它所接受的 props,这样 Vue 才能知道外部传入的哪些是 props,哪些是透传 attribute (关于透传 attribute,我们会在专门的章节中讨论)。
1 | <script setup> |
如果使用了 ts,也可以这么声明:
1 | <script setup lang="ts"> |
这被称之为“基于类型的声明”。感觉怪怪的。
当使用基于类型的声明时,我们失去了为 props 声明默认值的能力。这可以通过 withDefaults 编译器宏解决:
1 | export interface Props { |
prop 名字使用 camelCase 形式:
1 | defineProps({ |
然而对于传递 props 来说,使用 camelCase 并没有太多优势,因此我们推荐更贴近 HTML 的书写风格,使用 kebab-case 形式:
1 | <MyComponent greeting-message="hello" /> |
静态:
1 | <BlogPost title="My journey with Vue" /> |
动态绑定:
1 | <!-- 根据一个变量的值动态传入 --> |
不仅仅是字符串,实际上任何类型的值都可以作为 props 的值被传递。
Number:
1 | <!-- 虽然 `42` 是个常量,我们还是需要使用 v-bind --> |
Boolean:
1 | <!-- 仅写上 prop 但不传值,会隐式转换为 `true` --> |
Array:
1 | <!-- 虽然这个数组是个常量,我们还是需要使用 v-bind --> |
Object:
1 | <!-- 虽然这个对象字面量是个常量,我们还是需要使用 v-bind --> |
如果你想要将一个对象的所有属性都当作 props 传入,你可以使用没有参数的 v-bind,即只使用 v-bind 而非 :prop-name。例如,这里有一个 post 对象:
1 | const post = { |
1 | <BlogPost v-bind="post" /> |
等价于:
1 | <BlogPost :id="post.id" :title="post.title" /> |
所有的 props 都遵循着单向绑定原则,props 因父组件的更新而变化,自然地将新的状态向下流往子组件,而不会逆向传递。这避免了子组件意外修改父组件的状态的情况,不然应用的数据流将很容易变得混乱而难以理解。
另外,每次父组件更新后,所有的子组件中的 props 都会被更新到最新值,这意味着你不应该在子组件中去更改一个 prop。若你这么做了,Vue 会在控制台上向你抛出警告。
当对象或数组作为 props 被传入时,虽然子组件无法更改 props 绑定,但仍然可以更改对象或数组内部的值。这是因为 JavaScript 的对象和数组是按引用传递,而对 Vue 来说,禁止这样的改动,虽然可能生效,但有很大的性能损耗,比较得不偿失。
这种更改的主要缺陷是它允许了子组件以某种不明显的方式影响父组件的状态,可能会使数据流在将来变得更难以理解。在最佳实践中,你应该尽可能避免这样的更改,除非父子组件在设计上本来就需要紧密耦合。在大多数场景下,子组件应该抛出一个事件来通知父组件做出改变。
在组件的模板表达式中,可以直接使用 $emit 方法触发自定义事件:
1 | <!-- MyComponent --> |
父组件监听事件:
1 | <MyButton @increase-by="n => (count += n)" /> |
同样,组件的事件监听器也支持 .once 修饰符:
1 | <MyComponent @some-event.once="callback" /> |
像组件与 prop 一样,事件的名字也提供了自动的格式转换。注意这里我们触发了一个以 camelCase 形式命名的事件,但在父组件中可以使用 kebab-case 形式来监听。与 prop 大小写格式一样,在模板中我们也推荐使用 kebab-case 形式来编写监听器。
提示:
和原生 DOM 事件不一样,组件触发的事件没有冒泡机制。你只能监听直接子组件触发的事件。平级组件或是跨越多层嵌套的组件间通信,应使用一个外部的事件总线,或是使用一个全局状态管理方案。
组件可以显式地通过 defineEmits() 宏来声明它要触发的事件:
1 | <script setup lang="ts"> |
我们在 <template> 中使用的 $emit 方法不能在组件的 <script setup> 部分中使用,但 defineEmits() 会返回一个相同作用的函数供我们使用:
1 | <script setup> |
v-model 可以在组件上使用以实现双向绑定。
首先让我们回忆一下 v-model 在原生元素上的用法:
1 | <input v-model="searchText" /> |
模板编译器会对 v-model 进行冗长的等价展开。因此上面的代码其实等价于下面这段:
1 | <input :value="searchText" @input="searchText = $event.target.value" /> |
而当使用在一个组件上时,v-model 会被展开为如下的形式:
1 | <CustomInput :modelValue="searchText" @update:modelValue="newValue => (searchText = newValue)" /> |
所以,<CustomInput> 组件内部需要做两件事:
<input> 元素的 value attribute 绑定到 modelValue propinput 事件触发时,触发一个携带了新值的 update:modelValue 自定义事件1 | <!-- CustomInput.vue --> |
现在 v-model 可以在这个组件上正常工作了:
1 | <CustomInput v-model="searchText" /> |
另一种在组件内实现 v-model 的方式是使用一个可写的,同时具有 getter 和 setter 的 computed 属性。get 方法需返回 modelValue prop,而 set 方法需触发相应的事件:
1 | <!-- CustomInput.vue --> |
v-model 的参数默认情况下,v-model 在组件上都是使用 modelValue 作为 prop,并以 update:modelValue 作为对应的事件。我们可以通过给 v-model 指定一个参数来更改这些名字:
1 | <MyComponent v-model:title="bookTitle" /> |
在这个例子中,子组件应声明一个 title prop,并通过触发 update:title 事件更新父组件值:
1 | <!-- MyComponent.vue --> |
v-model绑定1 | <UserName v-model:first-name="first" v-model:last-name="last" /> |
1 | <script setup> |
v-model修饰符在学习输入绑定时,我们知道了 v-model 有一些内置的修饰符,例如 .trim,.number 和 .lazy。在某些场景下,你可能想要一个自定义组件的 v-model 支持自定义的修饰符。
我们来创建一个自定义的修饰符 capitalize,它会自动将 v-model 绑定输入的字符串值第一个字母转为大写:
1 | <MyComponent v-model.capitalize="myText" /> |
组件的 v-model 上所添加的修饰符,可以通过 modelModifiers prop 在组件内访问到。在下面的组件中,我们声明了 modelModifiers 这个 prop,它的默认值是一个空对象:
1 | <script setup> |
注意这里组件的 modelModifiers prop 包含了 capitalize 且其值为 true,因为它在模板中的 v-model 绑定 v-model.capitalize="myText" 上被使用了。
有了这个 prop,我们就可以检查 modelModifiers 对象的键,并编写一个处理函数来改变抛出的值。在下面的代码里,我们就是在每次 <input /> 元素触发 input 事件时将值的首字母大写:
1 | <script setup> |
对于又有参数又有修饰符的 v-model 绑定,生成的 prop 名将是 arg + "Modifiers"。举例来说:
1 | <MyComponent v-model:title.capitalize="myText"> |
相应的声明应该是:
1 | const props = defineProps(["title", "titleModifiers"]) |
“透传 attribute”指的是传递给一个组件,却没有被该组件声明为 props 或 emits 的 attribute 或者 v-on 事件监听器。最常见的例子就是 class、style 和 id。
当一个组件以单个元素为根作渲染时,透传的 attribute 会自动被添加到根元素上。举例来说,假如我们有一个 <MyButton> 组件,它的模板长这样:
1 | <!-- <MyButton> 的模板 --> |
一个父组件使用了这个组件,并且传入了 class:
1 | <MyButton class="large" /> |
最后渲染出的 DOM 结果是:
1 | <button class="large">click me</button> |
这里,<MyButton> 并没有将 class 声明为一个它所接受的 prop,所以 class 被视作透传 attribute,自动透传到了 <MyButton> 的根元素上。
class 和 style 的合并如果一个子组件的根元素已经有了 class 或 style attribute,它会和从父组件上继承的值合并。如果我们将之前的 <MyButton> 组件的模板改成这样:
1 | <!-- <MyButton> 的模板 --> |
则最后渲染出的 DOM 结果会变成:
1 | <button class="btn large">click me</button> |
v-on 监听器继承同样的规则也适用于 v-on 事件监听器:
1 | <MyButton @click="onClick" /> |
click 监听器会被添加到 <MyButton> 的根元素,即那个原生的 <button> 元素之上。当原生的 <button> 被点击,会触发父组件的 onClick 方法。同样的,如果原生 button 元素自身也通过 v-on 绑定了一个事件监听器,则这个监听器和从父组件继承的监听器都会被触发。
有些情况下一个组件会在根节点上渲染另一个组件。例如,我们重构一下 <MyButton>,让它在根节点上渲染 <BaseButton>:
1 | <!-- <MyButton/> 的模板,只是渲染另一个组件 --> |
此时 <MyButton> 接收的透传 attribute 会直接继续传给 <BaseButton>。
请注意:
<MyButton> 上声明过的 props 或是针对 emits 声明事件的 v-on 侦听函数,换句话说,声明过的 props 和侦听函数被 <MyButton>“消费”了。<BaseButton>。如果你不想要一个组件自动地继承 attribute,你可以在组件选项中设置 inheritAttrs: false。
如果你使用了 <script setup>,你需要一个额外的 <script> 块来书写这个选项声明:
1 | <script> |
最常见的需要禁用 attribute 继承的场景就是 attribute 需要应用在根节点以外的其他元素上。通过设置 inheritAttrs 选项为 false,你可以完全控制透传进来的 attribute 被如何使用。
这些透传进来的 attribute 可以在模板的表达式中直接用 $attrs 访问到。
1 | <span>Fallthrough attribute: {{ $attrs }}</span> |
这个 $attrs 对象包含了除组件所声明的 props 和 emits 之外的所有其他 attribute,例如 class,style,v-on 监听器等等。
有几点需要注意:
foo-bar 这样的一个 attribute 需要通过 $attrs['foo-bar'] 来访问。@click 这样的一个 v-on 事件监听器将在此对象下被暴露为一个函数 $attrs.onClick。1 | <div class="btn-wrapper"> |
小提示:没有参数的 v-bind 会将一个对象的所有属性都作为 attribute 应用到目标元素上。
和单根节点组件有所不同,有着多个根节点的组件没有自动 attribute 透传行为。如果 $attrs 没有被显式绑定,将会抛出一个运行时警告。
1 | <CustomLayout id="custom-layout" @click="changeValue" /> |
如果 <CustomLayout> 有下面这样的多根节点模板,由于 Vue 不知道要将 attribute 透传到哪里,所以会抛出一个警告。
1 | <header>...</header> |
如果 $attrs 被显式绑定,则不会有警告:
1 | <header>...</header> |
如果需要,你可以在 <script setup> 中使用 useAttrs() API 来访问一个组件的所有透传 attribute:
1 | <script setup> |
需要注意的是,虽然这里的 attrs 对象总是反映为最新的透传 attribute,但它并不是响应式的 (考虑到性能因素)。你不能通过侦听器去监听它的变化。如果你需要响应性,可以使用 prop。或者你也可以使用声明周期函数 onUpdated() 使得在每次更新时结合最新的 attrs 执行副作用。
依靠 props 传值,还是不够,如果要传递模板内容,则需要使用插槽 slots。
1 | <FancyButton> |
<FancyButton> 模板是这样的:
1 | <button class="fancy-btn"> |
<slot> 元素是一个插槽出口 (slot outlet),标示了父元素提供的插槽内容 (slot content) 将在哪里被渲染。
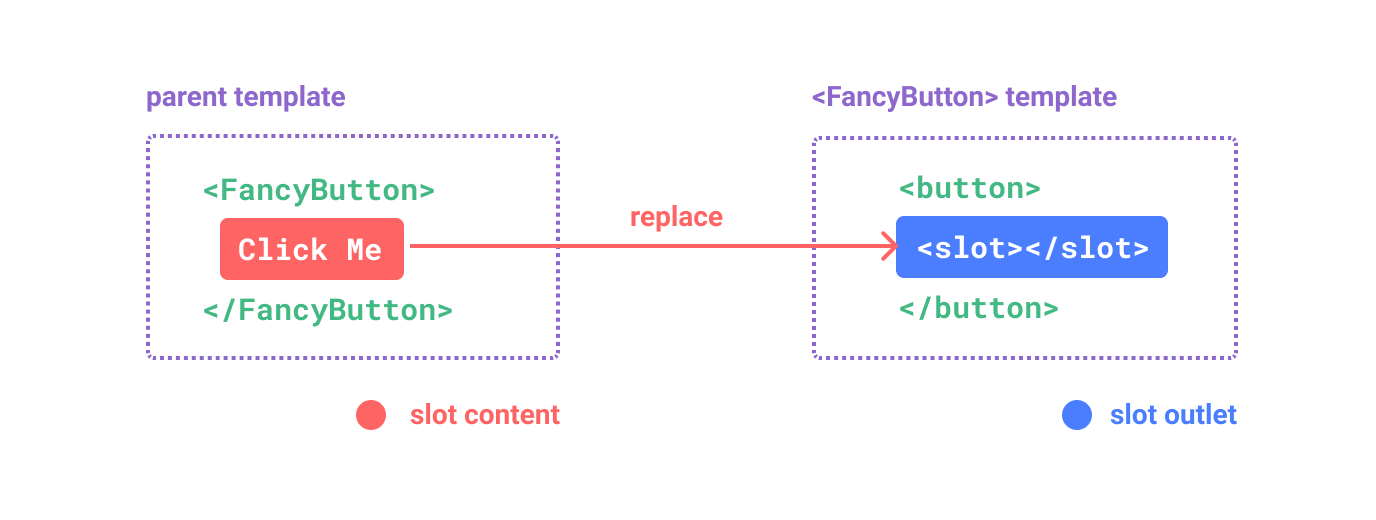
最终渲染出的 DOM 是这样:
1 | <button class="fancy-btn">Click me!</button> |
如果有多个插槽,需要给插槽命名。
1 | <div class="container"> |
这类带 name 的插槽被称为具名插槽 (named slots)。没有提供 name 的 <slot> 出口会隐式地命名为“default”。
要为具名插槽传入内容,我们需要使用一个含 v-slot 指令的 <template> 元素,并将目标插槽的名字传给该指令,v-slot 有对应的简写 #:
1 | <BaseLayout> |
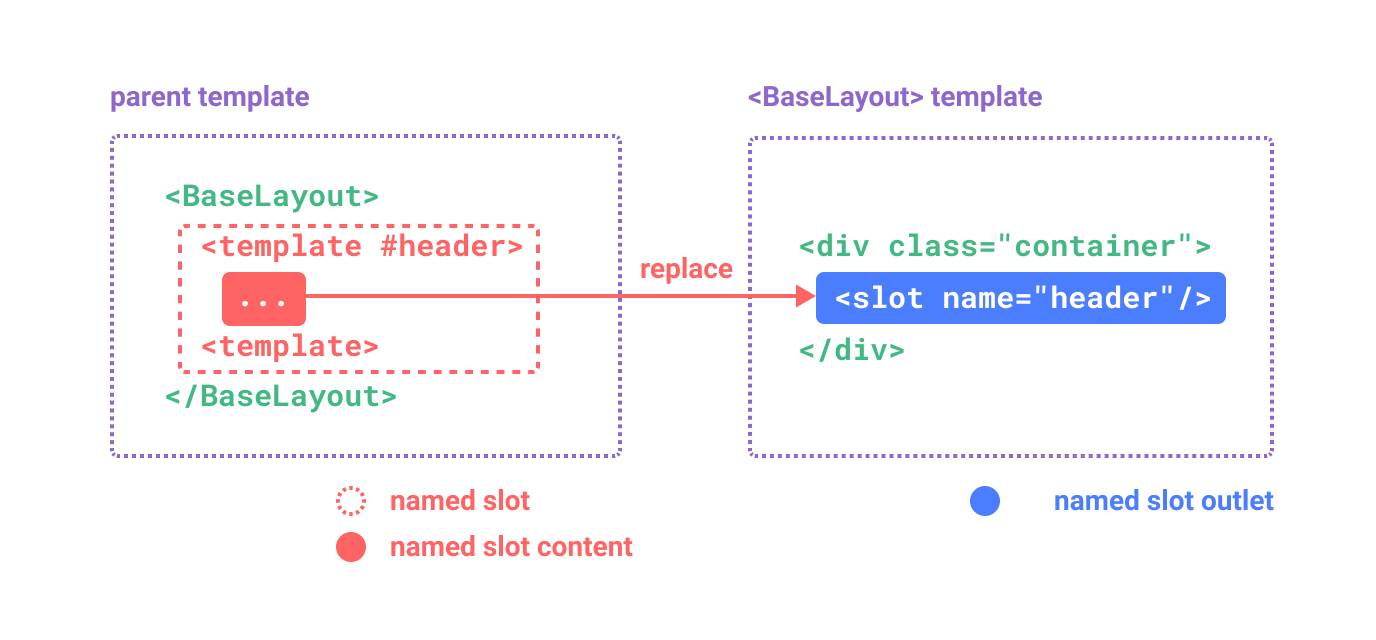
当一个组件同时接收默认插槽和具名插槽时,所有位于顶级的非 <template> 节点都被隐式地视为默认插槽的内容。所以上面也可以写成:
1 | <BaseLayout> |
Vue 模板中的表达式只能访问其定义时所处的作用域,这和 JavaScript 的词法作用域规则是一致的。
子组件定义插槽,父组件中使用子组件的时候,定义插槽中的内容。
插槽中内容是在父组件中定义的,所以插槽中只能访问父组件的作用域,但是如果插槽中需要使用到子组件作用域中的数据,怎么办?
子组件在定义插槽的时候,将需要使用到的数据传入插槽,这样,父组件在定义插槽中的内容时,就能使用传入的数据了。
定义组件 FacyList,并将item传入:
1 | <ul> |
或者:
1 | <ul> |
注意:插槽上的 name 是一个 Vue 特别保留的 attribute,不会作为 props 传递给插槽。
在父组件中引用子组件 FancyList,可以使用传入的参数:
1 | <FancyList> |
一些组件可能只包括了逻辑而不需要自己渲染内容,视图输出通过作用域插槽全权交给了消费者组件。我们将这种类型的组件称为无渲染组件。
大部分能用无渲染组件实现的功能都可以通过组合式 API 以另一种更高效的方式实现,并且还不会带来额外组件嵌套的开销。
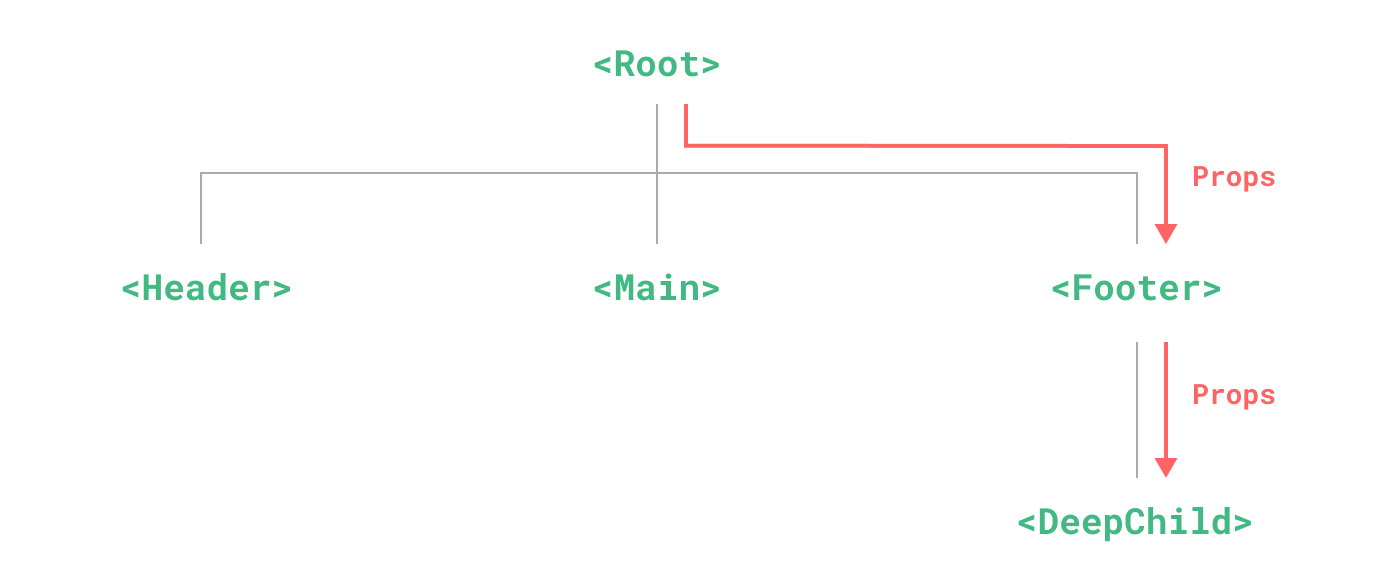
深层的组件需要顶层的数据,如果通过层层组件逐级传递 props,会很麻烦,中间层的组件可能根本不关系这些 props。
这个问题被称为 “prop 逐级透传”。
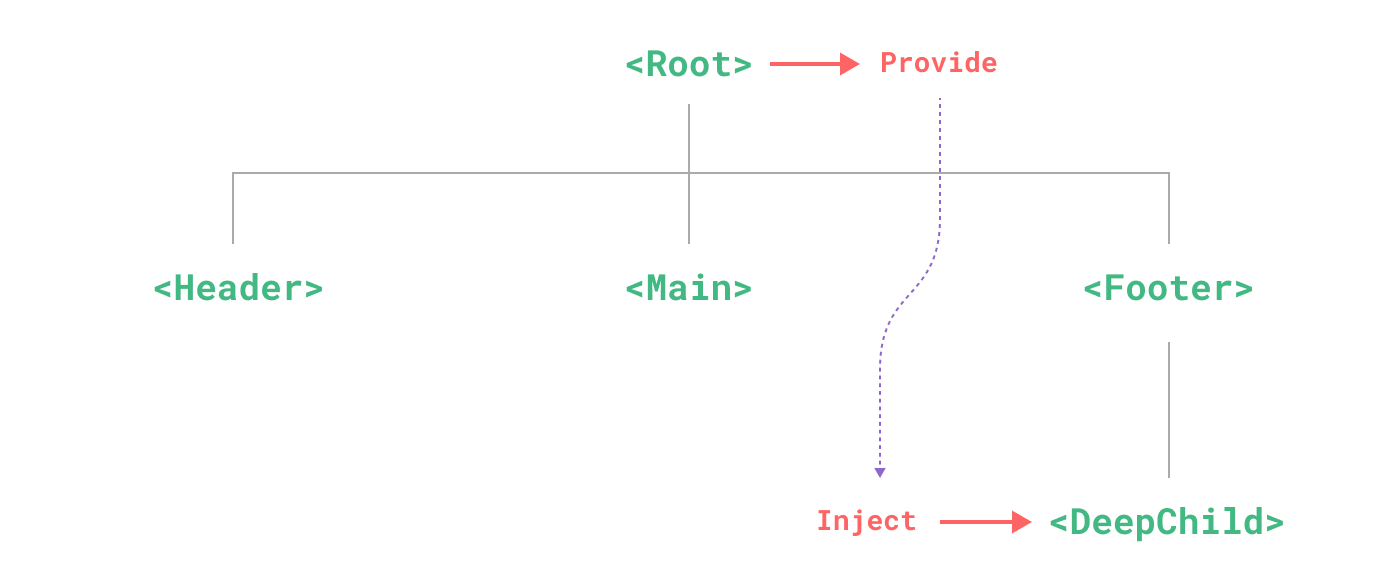
provide(提供) 和 inject(注入) 可以帮助我们解决这一问题。一个父组件相对于其所有的后代组件,会作为依赖提供者。任何后代的组件树,无论层级有多深,都可以注入由父组件提供给整条链路的依赖。
要为组件后代提供数据,需要使用到 provide() 函数:
1 | <script setup> |
注入名 可以是字符串或是 Symbol。
后代组件会用注入名来查找期望注入的值。
可以多次调用 provide(),使用不同的注入名,注入不同的依赖值。
值 可以是任意类型,包括响应式的状态,比如一个 ref:
1 | import { ref, provide } from "vue" |
提供的响应式状态使后代组件可以由此和提供者建立响应式的联系。
除了在一个组件中提供依赖,我们还可以在整个应用层面提供依赖:
1 | import { createApp } from "vue" |
在应用级别提供的数据在该应用内的所有组件中都可以注入。这在你编写插件时会特别有用,因为插件一般都不会使用组件形式来提供值。
要注入上层组件提供的数据,需使用 inject() 函数:
1 | <script setup> |
如果提供的值是一个 ref,注入进来的会是该 ref 对象,而不会自动解包为其内部的值。这使得注入方组件能够通过 ref 对象保持了和供给方的响应性链接。
1 | // 如果没有祖先组件提供 "message" |
或者:
1 | const value = inject('key', () => new ExpensiveClass()) |
当提供 / 注入响应式的数据时,建议尽可能将任何对响应式状态的变更都保持在供给方组件中。这样可以确保所提供状态的声明和变更操作都内聚在同一个组件内,使其更容易维护。
有的时候,我们可能需要在注入方组件中更改数据。在这种情况下,我们推荐在供给方组件内声明并提供一个更改数据的方法函数:
1 | <!-- 在供给方组件内 --> |
1 | <!-- 在注入方组件 --> |
最后,如果你想确保提供的数据不能被注入方的组件更改,你可以使用 readonly() 来包装提供的值。
1 | <script setup> |
如果你正在构建大型的应用,包含非常多的依赖提供,或者你正在编写提供给其他开发者使用的组件库,建议最好使用 Symbol 来作为注入名以避免潜在的冲突。
我们通常推荐在一个单独的文件中导出这些注入名 Symbol:
1 | // keys.js |
1 | // 在供给方组件中 |
1 | // 注入方组件 |
在大型项目中,我们可能需要拆分应用为更小的块,并仅在需要时再从服务器加载相关组件。Vue 提供了 defineAsyncComponent 方法来实现此功能:
1 | import { defineAsyncComponent } from "vue" |
如你所见,defineAsyncComponent 方法接收一个返回 Promise 的加载函数。这个 Promise 的 resolve 回调方法应该在从服务器获得组件定义时调用。你也可以调用 reject(reason) 表明加载失败。
ES 模块动态导入也会返回一个 Promise,所以多数情况下我们会将它和 defineAsyncComponent 搭配使用。类似 Vite 和 Webpack 这样的构建工具也支持此语法 (并且会将它们作为打包时的代码分割点),因此我们也可以用它来导入 Vue 单文件组件:
1 | import { defineAsyncComponent } from "vue" |
最后得到的 AsyncComp 是一个外层包装过的组件,仅在页面需要它渲染时才会调用加载内部实际组件的函数。它会将接收到的 props 和插槽传给内部组件,所以你可以使用这个异步的包装组件无缝地替换原始组件,同时实现延迟加载。
异步操作不可避免地会涉及到加载和错误状态,因此 defineAsyncComponent() 也支持在高级选项中处理这些状态:
1 | const AsyncComp = defineAsyncComponent({ |
如果提供了一个加载组件,它将在内部组件加载时先行显示。在加载组件显示之前有一个默认的 200ms 延迟——这是因为在网络状况较好时,加载完成得很快,加载组件和最终组件之间的替换太快可能产生闪烁,反而影响用户感受。
如果提供了一个报错组件,则它会在加载器函数返回的 Promise 抛错时被渲染。你还可以指定一个超时时间,在请求耗时超过指定时间时也会渲染报错组件。
异步组件可以搭配内置的 <Suspense> 组件一起使用,若想了解 <Suspense> 和异步组件之间交互,请参阅 Suspense 章节。
复用无状态逻辑的库有很多,比如你可能已经用过的 lodash 或是 date-fns。
在 Vue 中,复用有状态逻辑使用“组合式函数”(Composables) 。
和组件一样,可以在组合式函数中使用所有的 组合式 API,并返回需要暴露的状态。
更酷的是,你还可以嵌套多个组合式函数:一个组合式函数可以调用一个或多个其他的组合式函数。这使得我们可以像使用多个组件组合成整个应用一样,用多个较小且逻辑独立的单元来组合形成复杂的逻辑。实际上,这正是为什么我们决定将实现了这一设计模式的 API 集合命名为组合式 API。
1 | // fetch.js |
1 | <script lang="ts" setup> |
推荐使用 TanStack Query 库。
组合式函数约定用驼峰命名法命名,并以“use”作为开头。
你可能已经注意到了,我们一直在组合式函数中使用 ref() 而不是 reactive()。我们推荐的约定是组合式函数始终返回一个包含多个 ref 的普通的非响应式对象,这样该对象在组件中被解构为 ref 之后仍可以保持响应性:
1 | // x 和 y 是两个 ref |
从组合式函数返回一个响应式对象会导致在对象解构过程中丢失与组合式函数内状态的响应性连接。与之相反,ref 则可以维持这一响应性连接。
如果你更希望以对象属性的形式来使用组合式函数中返回的状态,你可以将返回的对象用 reactive() 包装一次,这样其中的 ref 会被自动解包,例如:
1 | const mouse = reactive(useMouse()) |
1 | Mouse position is at: {{ mouse.x }}, {{ mouse.y }} |
在组合式函数中的确可以执行副作用 (例如:添加 DOM 事件监听器或者请求数据),但请注意以下规则:
如果你的应用用到了服务端渲染 (SSR),请确保在组件挂载后才调用的生命周期钩子中执行 DOM 相关的副作用,例如:onMounted()。这些钩子仅会在浏览器中被调用,因此可以确保能访问到 DOM。
确保在 onUnmounted() 时清理副作用。举例来说,如果一个组合式函数设置了一个事件监听器,它就应该在 onUnmounted() 中被移除。
1 | // event.js |
组合式函数在 <script setup> 或 setup() 钩子中,应始终被同步地调用。在某些场景下,你也可以在像 onMounted() 这样的生命周期钩子中使用他们。
这个限制是为了让 Vue 能够确定当前正在被执行的到底是哪个组件实例,只有能确认当前组件实例,才能够:
提示:
<script setup>是唯一在调用await之后仍可调用组合式函数的地方。编译器会在异步操作之后自动为你恢复当前的组件实例。
除了 Vue 内置的一系列指令 (比如 v-model 或 v-show) 之外,Vue 还允许你注册自定义的指令 (Custom Directives)。
我们已经介绍了两种在 Vue 中重用代码的方式:组件和组合式函数。组件是主要的构建模块,而组合式函数则侧重于有状态的逻辑。另一方面,自定义指令主要是为了重用涉及普通元素的底层 DOM 访问的逻辑。
一个自定义指令由一个包含类似组件生命周期钩子的对象来定义。钩子函数会接收到指令所绑定元素作为其参数。下面是一个自定义指令的例子,当一个 input 元素被 Vue 插入到 DOM 中后,它会被自动聚焦:
1 | <script setup> |
假设你还未点击页面中的其他地方,那么上面这个 input 元素应该会被自动聚焦。该指令比 autofocus attribute 更有用,因为它不仅仅可以在页面加载完成后生效,还可以在 Vue 动态插入元素后生效。
在 <script setup> 中,任何以 v 开头的驼峰式命名的变量都可以被用作一个自定义指令。在上面的例子中,vFocus 即可以在模板中以 v-focus 的形式使用。
将一个自定义指令全局注册到应用层级也是一种常见的做法:
1 | const app = createApp({}) |
提示:
只有当所需功能只能通过直接的 DOM 操作来实现时,才应该使用自定义指令。其他情况下应该尽可能地使用
v-bind这样的内置指令来声明式地使用模板,这样更高效,也对服务端渲染更友好。
一个指令的定义对象可以提供几种钩子函数 (都是可选的):
1 | const myDirective = { |
当在组件上使用自定义指令时,它会始终应用于组件的根节点,和透传 attributes 类似。
总的来说,不推荐在组件上使用自定义指令。
插件 (Plugins) 是一种能为 Vue 添加全局功能的工具代码。下面是如何安装一个插件的示例:
1 | import { createApp } from "vue" |
一个插件可以是一个拥有 install() 方法的对象,也可以直接是一个安装函数本身。安装函数会接收到安装它的应用实例和传递给 app.use() 的额外选项作为参数:
1 | const myPlugin = { |
插件没有严格定义的使用范围,但是插件发挥作用的常见场景主要包括以下几种:
app.component() 和 app.directive() 注册一到多个全局组件或自定义指令。app.provide() 使一个资源 可被注入 进整个应用。app.config.globalProperties 中添加一些全局实例属性或方法…
在一个元素或组件进入和离开 DOM 时应用动画。
在一个 v-for 列表中的元素或组件被插入,移动,或移除时应用动画。
想要组件能在被“切走”的时候保留它们的状态。
可以用 <KeepAlive> 内置组件将这些动态组件包装起来。
它可以将一个组件内部的一部分模板“传送”到该组件的 DOM 结构外层的位置去。
<Suspense>是一项实验性功能。它不一定会最终成为稳定功能,并且在稳定之前相关 API 也可能会发生变化。
<Suspense> 是一个内置组件,用来在组件树中协调对异步依赖的处理。它让我们可以在组件树上层等待下层的多个嵌套异步依赖项解析完成,并可以在等待时渲染一个加载状态。
转载:
1 | // bad: 未判断data的长度,可导致 index out of range |
1 | type Packet struct { |
在进行数字运算操作时,需要做好长度限制,防止外部输入运算导致异常:
以下场景必须严格进行长度限制:
1 | // bad: 未限制长度,导致整数溢出 |
1 | // bad |
1 | // bad |
1 | // bad |
1 | // bad: 协程没有设置退出条件 |
1 | // bad: 通过unsafe操作原始指针 |
1 | // bad |
1 | // bad: 任意文件读取 |
1 | ioutil.WriteFile(p, []byte("present"), 0640) |
1.3.1【必须】命令执行检查
1 | // bad |
1 | // good |
1 | // bad |
1 | // bad |
1 | defer func () { |
1 | // bad |
1 | // bad |
1 | // good |
1 | // good |
1 | import ( |
1 | import ( |
1 | // bad |
使用”net/http”下的方法http.Get(url)、http.Post(url, contentType, body)、http.Head(url)、http.PostForm(url, data)、http.Do(req)时,如变量值外部可控(指从参数中动态获取),应对请求目标进行严格的安全校验。
如请求资源域名归属固定的范围,如只允许a.qq.com和b.qq.com,应做白名单限制。如不适用白名单,则推荐的校验逻辑步骤是:
第 1 步、只允许HTTP或HTTPS协议
第 2 步、解析目标URL,获取其HOST
第 3 步、解析HOST,获取HOST指向的IP地址转换成Long型
第 4 步、检查IP地址是否为内网IP,网段有:
1 | // 以RFC定义的专有网络为例,如有自定义私有网段亦应加入禁止访问列表。 |
第 5 步、请求URL
第 6 步、如有跳转,跳转后执行1,否则绑定经校验的ip和域名,对URL发起请求
官方库encoding/xml不支持外部实体引用,使用该库可避免xxe漏洞
1 | import ( |
1 | // bad |
1 | // good |
1 | import ( |
1 | import ( |
1 | // good |
除非资源完全可对外开放,否则系统默认进行身份认证,使用白名单的方式放开不需要认证的接口或页面。
根据资源的机密程度和用户角色,以最小权限原则,设置不同级别的权限,如完全公开、登录可读、登录可写、特定用户可读、特定用户可写等
涉及用户自身相关的数据的读写必须验证登录态用户身份及其权限,避免越权操作
1 | -- 伪代码 |
没有独立账号体系的外网服务使用QQ或微信登录,内网服务使用统一登录服务登录,其他使用账号密码登录的服务需要增加验证码等二次验证
1 | // bad |
1 | // bad |
敏感操作如果未作并发安全限制,可导致数据读写异常,造成业务逻辑限制被绕过。可通过同步锁或者原子操作进行防护。
通过同步锁共享内存
1 | // good |
1 | // good |
https://segmentfault.com/a/1190000041634906
1 | type MySlice[T int | string] []T |

任何泛型类型都必须传入类型实参实例化才可以使用:
1 | m := MyMap[string, int]{"a": 1, "b": 2} |

注意:匿名结构体不支持泛型
1、定义泛型类型的时候,基础类型不能只有类型形参。如下:
1 | type CommonType[T int|string|float32] T // 错误 |
2、当类型约束的一些写法会被编译器误认为是表达式时会报错。如下:
1 | type NewType[T *int] []T // 错误。T *int会被编译器误认为是表达式 T乘以int,而不是int指针 |
为了避免这种误解,解决办法就是给类型约束包上 interface{} 或加上逗号消除歧义
1 | type NewType[T interface{*int}] []T |
单纯的泛型类型实际上对开发来说用处并不大,但泛型类型和泛型 receiver 相结合,就有了非常大的实用性。
我们知道,定义了新的普通类型之后可以给类型添加方法。那么可以给泛型类型添加方法吗?答案自然是可以的,如下:
1 | type MySlice[T int | float32] []T |
使用接口的时候经常会用到类型断言或 type swith 来确定接口具体的类型,然后对不同类型做出不同的处理,如:
1 | var i interface{} = 123 |
但是,对于 valut T 这样通过类型形参定义的变量,不能使用类型断言或 type swith 判断具体类型。
1 | func (q *Queue[T]) Put(value T) { |
可以通过反射机制达到目的:
1 | func (receiver Queue[T]) Put(value T) { |
这看起来达到了我们的目的,可是当你写出上面这样的代码时候就出现了一个问题:
你为了避免使用反射而选择了泛型,结果到头来又为了一些功能在在泛型中使用反射
当出现这种情况的时候你可能需要重新思考一下,自己的需求是不是真的需要用泛型(毕竟泛型机制本身就很复杂了,再加上反射的复杂度,增加的复杂度并不一定值得)
示例:
1 | func Add[T int | float32 | float64](a T, b T) T { |
注意:
1 | type A struct { |
如果要想在方法中使用泛型的话,可以通过 receiver 间接实现:
1 | type A[T int | float32 | float64] struct { |
有时候使用泛型编程时,我们会书写长长的类型约束,如下:
1 | // 一个可以容纳所有int,uint以及浮点类型的泛型切片 |
理所当然,这种写法是我们无法忍受也难以维护的,而 Go 支持将类型约束单独拿出来定义到接口中,从而让代码更容易维护:
1 | type IntUintFloat interface { |
这段代码把类型约束给单独拿出来,写入了接口类型 IntUintFloat 当中。需要指定类型约束的时候直接使用接口 IntUintFloat 即可。
不过这样的代码依旧不好维护,而接口和接口、接口和普通类型之间也是可以通过 | 进行组合:
1 | type Int interface { |
或者:
1 | type SliceElement interface { |
~ 指定底层类型1 | var s1 Slice[int] // 正确 |
这里发生错误的原因是,泛型类型 Slice[T] 允许的是 int 作为类型实参,而不是 MyInt (虽然 MyInt 类型底层类型是 int ,但它依旧不是 int 类型)。
为了从根本上解决这个问题,Go 新增了一个符号 ~ ,在类型约束中使用类似 ~int 这种写法的话,就代表着不光是 int ,所有以 int 为底层类型的类型也都可用于实例化。
使用 ~ 对代码进行改写之后如下:
1 | type Int interface { |
限制:使用 ~ 时有一定的限制:
~后面的类型不能为接口~后面的类型必须为基本类型上面的例子中,我们学习到了一种接口的全新写法,而这种写法在 Go1.18 之前是不存在的。这意味着 Go 语言中 接口(interface) 这个概念发生了非常大的变化。
在 Go1.18 之前,Go 官方对 接口(interface)的定义是:接口是一个方法集(method set)。
从 Go1.18 开始,接口的定义正式更改为了 类型集(Type set)。
既然接口定义发生了变化,那么从 Go1.18 开始 接口实现(implement) 的定义自然也发生了变化。
当满足以下条件时,我们可以说 类型 T 实现了接口 I :
T 不是接口时:类型 T 是接口 I 代表的类型集中的一个成员T 是接口时: T 接口代表的类型集是 I 代表的类型集的子集如果一个接口有多个类型的定义,取它们之间的 交集
1 | type AllInt interface { |
上面的例子中:
A代表的是AllInt与Uint的交集,即:~uint | ~uint8 | ~uint16 | ~uint32 | ~uint64B代表的是AllInt与~int的交集,即:~intinterface{} 和 anyGo1.18 开始接口的定义发生了改变,所以 interface{} 的定义也发生了一些变更:
空接口代表了所有类型的集合
所以,对于 Go1.18 之后的空接口应该这样理解:
虽然空接口内没有写入任何的类型,但它代表的是所有类型的集合,而非一个 空集
类型约束中指定 空接口 的意思是指定一个包含所有类型的集合,并不是类型约束限制了只能使用 空接口 来做类型形参
1 | // 空接口代表所有类型的集合。写入类型约束意味着所有类型都可拿来做类型实参 |
因为空接口是一个包含了所有类型的类型集,所以我们经常会用到它。于是,Go1.18 开始提供了一个和空接口 interface{} 等价的新关键词 any ,用来使代码更简单:
1 | type Slice[T any] []T // 代码等价于 type Slice[T interface{}] []T |
对于一些数据类型,我们需要在类型约束中限制只接受能 != 和==对比的类型,如 map:
1 | // 错误。因为 map 中键的类型必须是可进行 != 和 == 比较的类型 |
所以 Go 直接内置了一个叫 comparable 的接口,它代表了所有可用 != 以及 == 对比的类型:
1 | type MyMap[KEY comparable, VALUE any] map[KEY]VALUE // 正确 |
注意:可比较指的是可以执行!= 和 == 操作,并没有确保这个类型可以执行大小比较(> < >= <=)
而可进行大小比较的类型被称为 Orderd 。目前 Go 并没有像 comparable 这样直接内置对应的关键词,所以想要的话需要自己来定义相关接口,比如我们可以参考golang.org/x/exp/constraints 如何定义:
1 | // Ordered 代表所有可比大小排序的类型 |
这里虽然可以直接使用官方包 golang.org/x/exp/constraints ,但因为这个包属于实验性质的 x 包,今后可能会发生非常大变动,所以并不推荐直接使用
1 | type ReadWriter interface { |
我们用类型集的概念来理解这个接口的意思:
接口类型 ReadWriter 代表了一个类型集合,所有以 string 或 []rune 为底层类型,并且实现了 Read() Write() 这两个方法的类型都在 ReadWriter 代表的类型集当中。
1 | // 类型 StringReadWriter 实现了接口 Readwriter |
现在,定义一个 ReadWriter 类型的接口变量,接口变量赋值的时候不光要考虑到方法的实现,还必须考虑到具体底层类型,心智负担太大。为了解决这个问题也为了保持 Go 语言的兼容性,Go1.18 开始将接口分为了两种类型:
接口定义中如果只有方法的话,那么这种接口被称为**基本接口(Basic interface)**。这种接口就是 Go1.18 之前的接口,用法也基本和 Go1.18 之前保持一致。基本接口大致可以用于如下几个地方:
定义接口变量并赋值
1 | type MyError interface { // 接口中只有方法,所以是基本接口 |
用在类型约束中
1 | type MySlice[T io.Reader | io.Writer] []Slice |
接口中有类型的话,这种接口被称为 一般接口(General interface) ,如下例子都是一般接口:
1 | type Uint interface { // 接口 Uint 中有类型,所以是一般接口 |
一般接口类型不能用来定义变量,只能用于泛型的类型约束中。所以以下的用法是错误的:
1 | type Uint interface { |
这一限制保证了一般接口的使用被限定在了泛型之中,不会影响到 Go1.18 之前的代码,同时也极大减少了书写代码时的心智负担。
1 | type DataProcessor[T any] interface { |
Go1.18 从开始,在定义类型集(接口)的时候增加了非常多十分琐碎的限制规则,其中很多规则都在之前的内容中介绍过了,但剩下还有一些规则因为找不到好的地方介绍,所以在这里统一介绍下:
用 | 连接多个类型的时候,类型之间不能有相交的部分(即必须是不交集):
1 | type MyInt int |
但是相交的类型中是接口的话,则不受这一限制:
1 | type MyInt int |
类型的并集中不能有类型形参
1 | type MyInf[T ~int | ~string] interface { |
接口不能直接或间接地并入自己
1 | type Bad interface { |
接口的并集成员个数大于一的时候不能直接或间接并入 comparable 接口
1 | type OK interface { |
带方法的接口(无论是基本接口还是一般接口),都不能写入接口的并集中:
1 | type _ interface { |
实际上推荐的使用场景也并没有那么广泛,对于泛型的使用,我们应该遵守下面的规则:
泛型并不取代 Go1.18 之前用接口+反射实现的动态类型,在下面情景的时候非常适合使用泛型:当你需要针对不同类型书写同样的逻辑,使用泛型来简化代码是最好的 (比如你想写个队列,写个链表、栈、堆之类的数据结构)
slice 是数组的引用,但是本身是结构体:
1 | // runtime/slice.go |
1 | s := make([]string, 1, 3) |
创建 slice:
cap的数组,如果不指定cap,则cap等于len;例如s := []string{"a","b","c"}的len和cap都是 3;len个元素进行初始化,上例中数组第一个元素 k 初始化为空字符串;slice 的分割不涉及复制操作:它只是新建了一个结构来放置一个不同的指针,长度和容量:

分割表达式x[1:3]并不分配更多的数据:它只是创建了一个新的 slice 来引用相同的存储数据。
1 | s1 := []int{1, 2, 3} |
修改 s1,也会影响到 s2。
字符串的分割也同理:

现有的元素加上要添加的元素,长度不超过 cap,则不会发生扩容行为,只会修改被引用的数组和len:
1 | s1 := make([]int, 2, 100) |
append 添加的元素太多,当前底层的数组不够用了,就会自动扩容,会复制被引用的数组,然后切断引用关系。
上面的例子中:
1 | s1 := []int{1, 2, 3} |
修改 s1,也会影响到 s2,如果想避免这种情况,需要使用copy(dst, src):
1 | s1 := []int{1, 2, 3} |
在对 slice 进行 append 等操作时,可能导致 slice 会自动扩容,重新分配更大的数组。go1.18 之前其扩容的策略是:
go1.18 之后,优化了切片扩容的策略 2,让底层数组大小的增长更加平滑:
1 | newcap := old.cap |
通过减小阈值并固定增加一个常数,使得优化后的扩容的系数在阈值前后不再会出现从 2 到 1.25 的突变,作者给出了几种原始容量下对应的“扩容系数”:
| 原始容量 | 扩容系数 |
|---|---|
| 256 | 2.0 |
| 512 | 1.63 |
| 1024 | 1.44 |
| 2048 | 1.35 |
| 4096 | 1.30 |
在 go 语言中 slice 是很灵活的,大部分情况都能表现的很好,但也有特殊情况。
当程序要求 slice 的容量超大并且需要频繁的更改 slice 的内容时,就不应该用 slice,改用list更合适。
转载:http://hmli.ustc.edu.cn/doc/linux/ubuntu-autoinstall/index.html
Ubuntu 22.04下的PXE自动无人值守安装配置服务设置,原文内容比较简单,基本为翻译的 Ubuntu 22.04官方手册 。
服务端提供PXE自动安装服务的信息:
提供DHCPD服务的网卡:enp2s0IP:192.168.22.254掩码:255.255.255.0
客户端(目标对象)网络启动引导的信息:
安装系统名:Cleint1采用DHCP协议引导的网卡:enp1s0MAC地址:08:00:20:0A:0C:01自身IP:192.168.22.1网关IP:192.168.22.254掩码:255.255.255.0DNS:202.38.64.7
下述带有 1.、2. 编号的才是实际执行的步骤,其他都是介绍。
AMD64(也称为x86_64)架构的系统启动既可以采用 UEFI 也可以采用传统 legacy (“BIOS”) 模式(很多系统可以被配置为采用其中任一模式启动)。确切的细节取决于系统固件,但两种模式都支持 PXE(“Preboot eXecution Environment”) 规范,使得可以通过网络来提供启动器引导加载程序启动主机。
两种模式的网络启动实时服务器安装程序的过程相似,如下所示:
UEFI 和传统模式之间的区别在于:在 UEFI 模式下,引导加载程序是 EFI 可执行文件,经过签名以便安全引导 SecureBoot 接受,而在传统模式下,它是 PXELINUX 。大多数 DHCP/bootp 服务器可以配置为为特定机器提供正确的引导加载程序。
有几种可用的 DHCP/bootp 和 tftp 协议实现。本文档将简要介绍如何配置 dnsmasq 服务(相比配置 isc-dhcp-server 与 tftpd 简单的多)以执行这两个角色。
创建存放为客户端提供 tftp 服务所需要的文件的目录 /srv/tftp :
1 | mkdir /srv/tftp |
安装 dnsmasq 包,执行命令:
1 | apt install dnsmasq |
设置文件 /etc/dnsmasq.conf.d/pxe.conf ,其内容:
1 | #设置本服务器提供DHCP服务的网卡 |
上面 enp2s0 为对客户端安装服务时使用的网卡名(与客户端启动网络安装服务的网卡在同一网络)。
重启 dnsmasq 服务,执行命令:
1 | systemctl restart dnsmasq |
安装对应包
1 | apt install cd-boot-images-amd64 |
生成软链接 /srv/tftp/boot-amd64指向 /usr/share/cd-boot-images-amd64 :
安装时,需要通过 HTTP 协议下载所需文件,为此需要配置 WEB 服务。
安装所需要包,并重新启动服务:
1 | apt install apache2 |
或者不用上述 apache 服务,如python3支持http模块,则可直接执行下述命令启动简易 WEB 服务:
1 | python3 -m http.server 80 |
针对该次使用 Ubuntu 22.04 server 版(代号: jammy ),建议有些配置文件放置在目录 /var/www/html/jammy 下,为此先生成该目录:
mkdir /var/www/html/jammy
下载所需要的操作系统 Live ISO 镜像到目录 /var/www/html :
1 | cd /var/www/html/jammy |
挂载该ISO文件:
1 | mount -o loop /var/www/html/jammy/ubuntu-22.04.1-live-server-amd64.iso /mnt |
将内核和 initrd 从其中复制到 dnsmasq 中设置的 tftp 的位置:
1 | cp /mnt/casper/{vmlinuz,initrd} /srv/tftp/ |
将签名的 shim 二进制文件复制到位:
1 | apt download shim-signed |
将签名的 grub 二进制文件复制到位:
1 | apt download grub-efi-amd64-signed |
Grub 还需要在 tftp 上可用的字体:
1 | apt download grub-common |
生成文件 /srv/tftp/grub/grub.cfg ,内容为:
1 | set default="0" |
备注:
ds=nocloud-net;s=http 部分的“;”前面有个转义符“”,最后有三个“-”从 20.04 版起,服务器安装程序支持一种新的操作模式:自动安装(简称 autoinstall ),此功能也被称为无人值守、甩手或预置安装。
自动安装使得用户可以通过提前配置自动安装配置文件回答所有这些安装配置问题,并让安装过程无需任何交互即可自行运行,适合批量安装多台主机。
preseeds 是基于 debian-installer (又名 d-i )自动化安装程序的方法。
Ubuntu新 autoinstall 方式的自动安装主要在以下方面不同于 preseeds :
格式完全不同( cloud-init config 格式,通常是 yaml 格式,vs debconf-set-selections 格式)
当一个问题的答案不存在于 preseeds 中时, d-i 停止执行并要求用户输入。 autoinstalls 自动安装不是这样的:默认情况下,如果有任何自动安装配置,安装程序会为任何未回答的问题采用默认设置(如没有默认设置则失败)。
用户可以将配置中的特定部分指定为“交互式”,这意味着安装程序仍会停止并询问这些部分。
自动安装配置是通过 cloud-init 配置提供的,几乎无限灵活。在大多数情况下,最简单的方法是通过 nocloud 数据源提供用户数据。
自动安装配置应在配置中的关键字 autoinstall 下提供,如:
1 | #cloud-config |
即使找到完全非交互式的自动安装配置,服务器安装程序也会在写入磁盘之前要求确认,除非内核命令行上存在自动安装关键字 autoinstall 。这是为了避免意外创建一个U盘,结果该U盘会在主机启动时重新格式化它插入的机器。许多自动安装将通过 netboot 完成,其中内核命令行由 netboot 配置控制 —— 只需记住将自动安装放在那里!
如只是想试试看,可以参看页面 https://ubuntu.com/server/docs/install/autoinstall-quickstart 。
当服务器安装好Ubuntu操作系统时,会在安装好后的服务器上创建一个可用于重复安装的自动安装文件 /var/log/installer/autoinstall-user-data ,这可用于做后续需要的文件 user-data 的模板。
如已经有了Debian系统的 preseed 文件,可利用自动安装生成器 autoinstall-generator snap 包(snap 是一种包管理器,可用于安装远程snap包)可以帮助将该预置数据转换为自动安装文件。
安装 autoinstall-generator 包,执行:
1 | snap install autoinstall-generator |
将 preseed 文件转换为自动安装格式的基本用法为:
1 | autoinstall-generator my-preseed.txt my-cloud-config.yaml --cloud |
有关详细信息,请 参阅 。
自动安装配置的完整说明参见:https://ubuntu.com/server/docs/install/autoinstall-reference 。
从技术上讲,虽然配置未定义为文本格式,但 cloud-init 配置通常以 YAML 形式提供,这是本文档使用的语法。
一个最小的配置是:
1 | version: 1 |
含有更多特性的配置为:
1 | version: 1 |
许多关键字和值一般直接对应于安装程序提出的问题(例如键盘选择),请参阅相关资料。
安装过程中的进度及出错信息,可以通过报告 reporting 关键字设定的系统获取。此外,当发生致命错误时,将执行错误命令 error-commands 并将回溯打印到控制台,然后服务器等待人为交互式干预。
可能希望扩展磁盘的 match specs (匹配规范)以涵盖选择磁盘的其他方式。
cloud-init 使用以下三种数据并对其进行操作。
设置用户数据文件 /var/www/html/jammy/user-data (可以采用文件 /var/log/installer/autoinstall-user-data 为模板修改),其内容为:
1 | #cloud-config |
备注:late-commands 等中的字符串在传递给执行安装的主机时,有些特殊字符串需要特殊处理。
生成所需要的文件 meta-data (空文件即可),执行命令:
1 | touch /var/www/html/jammy/meta-data |
供应商数据文件 vendor-data 非必需,可不管。
确保目录 /var/www/html/jammy/ 下的文件对所有人可读:
1 | chmod -R a+r /var/www/html/jammy/ |
上述各项含义参见: 自动服务器安装配置文件参考 。
备注:做好上述工作后,同一子网内的客户机启动采用PXE引导时,即可自动安装配置所需要的系统。
自动安装 autoinstall 文件是 YAML 格式的。在顶层,它必须是包含本文档中描述的关键字 key 的映射。无法识别的关键字将被忽略。
自动安装配置在使用前会根据 JSON 模式进行转换并进行验证。
几个配置关键字是要执行的命令列表。每个命令可以是字符串(在这种情况下通过 sh -c 执行)或列表,在这种情况下直接执行。任何以非零返回码退出的命令都被视为错误并中止安装(错误命令除外,它被忽略)。
version
名称:版本
类型:整型
默认值:无
为将来不同版本准备的版本信息,目前只能为 1 。
interactive-sections
名称:交互式部分
类型:字符串列表
默认值:[]
仍然显示在用户界面 UI 中的配置键列表,如:
1 | version: 1 |
交互式操作,将在网络屏幕上停止并允许用户更改默认值。如果为交互式部分提供了值,则将其用作默认值。
可以使用特殊的块名称 “*” 来指示安装程序应该询问所有常见问题——在这种情况下,文件 autoinstall.yaml 根本不是真正的“自动安装”文件,而只是一种用于更改用户界面中的默认值的文件。
并非所有配置关键字都对应于用户界面中的屏幕。该文档指示给定块是否可以交互。
如果有任何交互块,则忽略报告关键字 reporting 。
early-commands
名称:早期命令
默认值:无
是否可交互:不可
安装程序启动后立即调用的shell命令列表,特别是在执行探测块和网络设备操作之前执行。自动安装配置在 /autoinstall.yaml 中可用(不管它是如何被提供),并且在早期命令 early-commands 运行后将重新读取该文件,以允许它们在必要时更改配置。
locale
名称:语言环境
类型:字符串
默认值:en_US.UTF-8
是否可交互:可,对于任何块中是的话,总是可以交互
为已安装系统配置的语言环境。
refresh-installer
控制安装程序在继续之前是否更新到给定频道 channel 中可用的新版本。
映射包含关键字:
update
控制是否执行系统更新。
channel
用于检查系统更新的频道。
keyboard
任何附属键盘的布局。通常自动安装的系统根本没有键盘,在这种情况下,此处使用的值无关紧要。
映射的关键字对应于 /etc/default/keyboard 配置文件中的设置。有关更多详细信息,请参阅其手册页。
映射包含关键字:
layout
对应于键盘 XKBLAYOUT 设置。
variant
名称:变种
类型:字符串
默认值:””
对应于键盘 XKBVARIANT 设置。
toggle
对应于 grp 值: 来自键盘 XKBOPTIONS 设置的选项的值。可接受的值是(但请注意,安装程序不会验证这些):caps_toggle、toggle、rctrl_toggle、rshift_toggle、rwin_toggle、menu_toggle、alt_shift_toggle、ctrl_shift_toggle、ctrl_alt_toggle、alt_caps_toggle、lctrl_lshift_toggle、lalt_toggle、lctrl_toggle、lwinshift_toggle
与20.04 GA一起发布的 subiquity 版本由于一个bug不接受该字段为null。
network
netplan 格式的网络配置。将在安装期间以及已安装的系统中应用。默认是解释安装媒介的配置,它在名称匹配 “eth*” 或 “en*” 的任何网卡上运行 DHCPv4 请求,并随后禁用任何未获取到IP地址的网卡。
例如,要在特定网卡 enp0s31f6 上运行 dhcp6 请求:
1 | network: |
请注意,由于一个错误,随 20.04 GA 发布的 subiquity 版本强制您使用额外的 “network:” 关键字编写此代码,如下所示:
1 | network: |
更高版本也支持此语法(以实现兼容性),但如果可以确定采用修复后的新版本,则应使用前者(无需使用额外的 “network:” 关键字)。
proxy
在安装期间以及在目标系统中为 apt 和 snapd 配置的代理,以便访问网络。
apt
APT配置,在安装期间和引导到目标系统后都使用。
这使用与 https://curtin.readthedocs.io/en/latest/topics/apt_source.html 中描述的 curtin (the curt installer) 安装格式相同的格式,但有一个扩展:关键字 geoip 控制是否完成地理IP(geoip)查找。
默认值为:
1 | apt: |
如关键字 geoip 为 true 并且要使用的镜像源是默认值( http://archive.ubuntu.com/ubuntu 或 http://ports.ubuntu.com/ubuntu-ports 等),则向 https://geoip.ubuntu.com/lookup 发出请求,并且将使用的镜像URI更改为 http://CC.archive.ubuntu.com/ubuntu , 其中 CC 是查找返回的国家代码(或类似的端口,对于中国为 CN ),这将使用所在国家区域的源,提升网络更新速度。如果此部分不是交互式的,则请求会在10秒后超时。
任何提供的配置都会与默认配置合并,而不是替换它。
如果您只想设置镜像源,请使用如下配置:
1 | apt: |
增加一个 PPA 源:
1 | apt: |
storage
存储配置是一个复杂的话题,自动安装文件中所需配置的描述也可能很复杂。安装程序支持“布局layouts”,即表达常见配置的简单方法。
支持的布局
目前支持的布局就两种,分别是逻辑卷模式 lvm 和直通模式 direct 。
1 | storage: |
默认情况下,这些将安装到系统中容量最大的磁盘,但您可以提供匹配规范(“match: {}”,见下文)来指示要使用的磁盘:
1 | storage: |
(可以用“match: {}”来匹配任意磁盘)
默认采用 lvm 。
基于动作的配置
为了获得完全的灵活性,安装程序允许使用一种语法完成存储配置,该语法是 curtin 支持的语法的超集,在 https://curtin.readthedocs.io/en/latest/topics/storage.html 中进行了描述。
如果使用 layout 功能配置磁盘,则不会使用 config 部分。
除了将操作列表放在关键字 config 下之外, grub 和 swap curtin配置项也可以放在此处。因此存储部分可能如下所示:
1 | storage: |
Curtin语法的扩展围绕磁盘选择和分区/逻辑卷大小调整。
磁盘选择扩展
Curtin支持通过串行(如 Crucial_CT512MX100SSD1_14250C57FECE )或路径(如 /dev/sdc )识别磁盘,服务器安装程序也支持这一点。安装程序还支持磁盘操作上的 match spec ,支持更灵活的匹配。
存储配置中的操作按照它们在自动安装文件中的顺序进行处理。任何磁盘操作都会被分配一个匹配的磁盘——如果有多个磁盘,则从一组未分配的磁盘中任意选择,如果没有未分配的匹配磁盘,则会导致安装失败。
匹配规范支持以下关键字: - model: foo :匹配 udev 中 ID_VENDOR=foo 的磁盘,支持通配符 - path: foo :匹配 udev 中 DEVPATH=foo 的磁盘,支持通配符(通配符支持将此与直接在磁盘操作中指定 path: foo 区分开来) - serial: foo :匹配 udev 中 ID_SERIAL=foo 的磁盘,支持通配符(通配符支持将此与直接在磁盘操作中指定 serial: foo 区分开来) - ssd: yes|no :匹配是或不是 SSD 的磁盘(相对于机械硬盘) - size: largest|smallest :如果有多个匹配项,则取最大或最小的磁盘而不是任意一个(在 20.06.1 版本中添加了对最小 smallest 的支持)
因此,例如,要匹配任意磁盘,只需:
1 | - type: disk |
匹配容量最大的SSD硬盘:
1 | - type: disk |
匹配希捷Seagate硬盘:
1 | - type: disk |
分区/逻辑卷扩展
curtin中的分区或逻辑卷的大小指定为字节数。自动安装配置更加灵活:
1 | - type: partition |
identity
配置系统的初始用户。这是唯一必须存在的配置关键字(除非存在用户数据部分,在这种情况下它是可选的)。
可以包含关键字的映射,所有关键字都采用字符串值:
ssh
为已安装的系统配置 SSH 服务。可以包含关键字的映射:
install-server
是否安装 OpenSSH 服务。
authorized-keys
要安装在初始用户帐户中的 SSH 公钥列表,方便其他主机采用密钥通过 SSH 访问该主机。
allow-pw
snaps
要安装的snap包列表。每个snap都表示为具有必需的关键字 name 和可选的关键字 chanel (默认为 stable )和 classic (经典默认为 false )的映射。如:
1 | snaps: |
debconf-selections
安装程序将使用 debconf 设置选择值更新目标。用户需要熟悉软件包 debconf 选项。
packages
要安装到目标系统中的软件包列表。更准确地说,是传递给命令 apt-get install 的字符串列表,因此这包括任务选择( dns-server^ )和安装特定版本的包( my-package=1-1 )。
late-commands
在安装成功完成并安装任何更新和软件包之后运行的 Shell 命令,就在系统重新启动之前。它们在安装程序环境中运行,已安装的系统安装在目录 /target 。您可以运行 curtin in-target -- $shell_command (使用20.04 GA发布的subiquity安装程序版本,采用 curtin 格式,您需要将其指定为 curtin in-target --target=/target -- $shell_command )以在目标系统中运行(类似了解如何在 d-i preseed/late_command 中使用简单的目标内)。
error-commands
安装失败后运行的Shell命令。它们在安装程序环境中运行,并且目标系统(或安装程序设法配置的尽可能多的系统)将安装在目录 /target 。日志将在实时会话中的目录 /var/log/installer 中可用。
reporting
安装程序支持向各种目的地报告进度。请注意,如果有任何交互部分,则忽略此部分;它仅适用于全自动安装。
配置,实际上实现,与curtin使用的90%相同。
配置中报告映射中的每个键都定义了一个目标,其中子关键字 type 是以下之一:
(原文在该处有 The rsyslog reporter does not yet exist ,没理解为什么在这个位置说这个,也不清楚什么含义)
例子:
默认配置:
1 | reporting: |
输出到 rsyslog :
1 | reporting: |
抑制默认输出:
1 | reporting: |
输出到 curtin 样式的 webhook :
1 | reporting: |
user-data
提供 cloud-init 用户数据,它将与安装程序生成的用户数据 user-data 合并。如果您提供此信息,则无需提供身份 ** identity** 部分(但您有责任确保您可以登录到已安装的系统!)。